在第一章中,我们对比过单机系统和分布式系统的区别,单机系统通过共享内存进行通信、有全局唯一的时钟,在出错时有确定的表现,在单机系统上编程是相对容易的。相较而言,分布式系统由多个节点组成,节点之间通过消息进行通信,这导致了分布式系统更加复杂。因此在开始设计分布式系统之前,需要一套描述系统运行模型的理论框架,开发者需要在设计时就明确系统的运行环境所满足的各种条件,不同的条件系统的实现难度不同。分布式系统模型就是用于描述和分析分布式系统行为、属性和设计的理论框架。它们为研究分布式系统的通信、计算、故障、同步等特性提供了一种抽象方式,帮助设计者和研究者在复杂环境中理解系统行为并解决实际问题。
在本章中,我们从两个著名的分布式实验两将军问题和拜占庭将军问题开始,展开对分布式系统模型的讨论。
两将军问题 #
两将军问题(Two Generals’ Problem)1是分布式领域里的一个思想实验,旨在说明:试图通过不可靠的连接来进行通信,协调分布式系统中的多节点之间的操作,会遇到的陷阱和挑战。
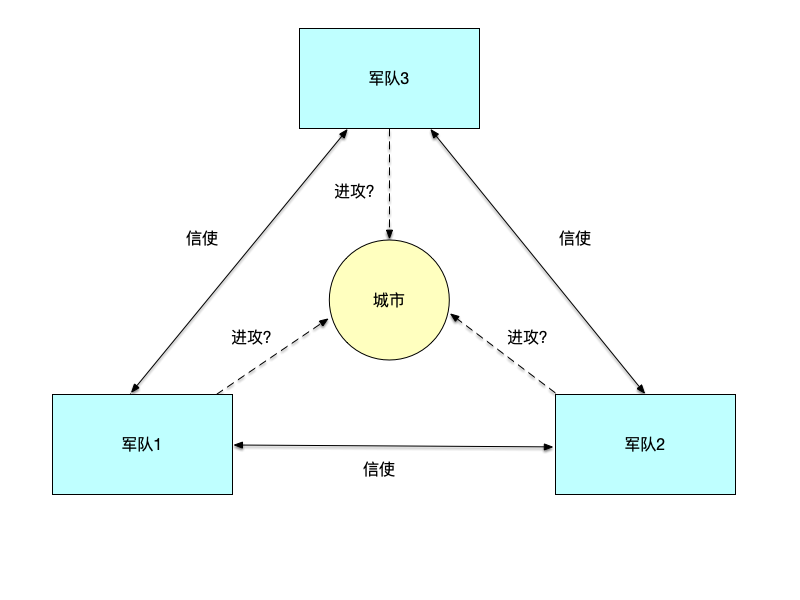
实验中假设有两支军队,分别由一位将领负责给军队发号施令,两支军队准备进攻一座城市。这座城市的防守很坚固,需要两支军队一起行动才能胜利,而任何一方单独行动都将失败。两位将领需要协调一个共同发起攻击的时间。两支军队驻扎在城市的两处,中间有一个山谷将两支军队分开,他们之间通信的唯一方式就是派遣信使穿越山谷。然而,山谷被城市的守军控制,途经该山谷传递的消息有可能被俘。
虽然两位将军已经就进攻城市达成了共识,但是并没有就进攻时间达成共识。两位将军必须同时让自己的军队一起发起进攻才能取胜。因此,他们之间必须沟通协调一个发起进攻的时间。如果一位将军以为协调了一个进攻时间,而另一位将军却并不知情,导致只有一个军队发起进攻,那么这将是一个灾难性的失败,如下表所示:
| 军队A1 | 军队A2 | 结果 |
|---|---|---|
| 不进攻 | 不进攻 | 无事发生 |
| 进攻 | 不进攻 | 军队A1失败 |
| 不进攻 | 进攻 | 军队A2失败 |
| 进攻 | 进攻 | 攻下城市 |
表:发起进攻的可能结果
在这个实验中,“将军"就是分布式系统中的节点,它们之间通信的信使就是节点之间通信的连接,可以看到这个连接并不可靠:消息可能会被丢失。我们来看一下在这种不可靠连接的通信下,两个将军是否能达成一个关于进攻时间的共识。
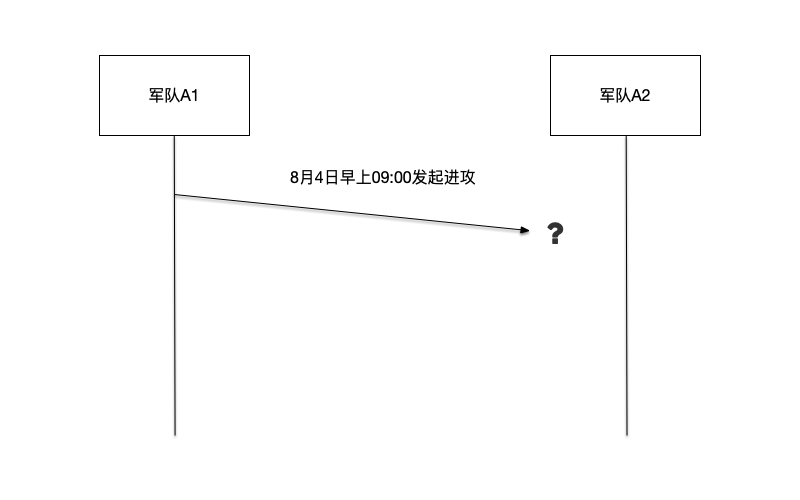
假如A1将军向A2将军传递消息"8月4日早上09:00发起进攻”,由于信使可能会被俘获,所以A1将军也并不确定消息可以被A2将军收到。这种不确定性导致A1犹豫不决,因为如果只有他发起进攻会导致失败。
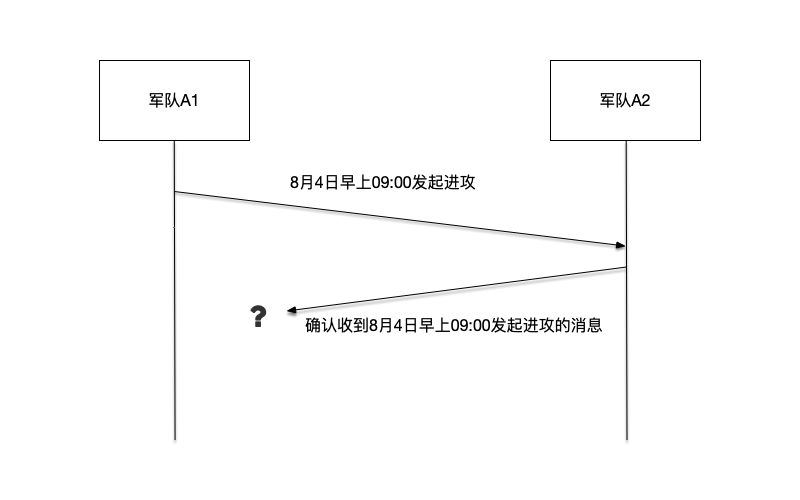
为了消除这种不确定性,A1和A2约定:收到消息后,要对应发出一个确认消息,让发送方确认消息已经被成功接收。然而,确认消息也同样可能被俘获,也不确定是否能到达接收方。这种不确定性导致A2犹豫不决,因为如果只有他发起进攻会导致失败。
问题到了这里,进入了一个死胡同:因为无论发送多少确认消息,都没有办法保证两位将军有足够的自信,保证自己的信使没有被敌军俘获。
从以上两个场景中可以看到,两将军问题中面临以下的难题:
- 消息传递的不确定性:将军A1发送消息给将军A2,告知进攻时间,但无法确认A2是否收到。即便A2收到并回复确认,A1也无法确认回复是否送达。这种确认过程可能无限循环,因为每次确认都需要进一步确认。
- 无限确认问题:为了确保双方都同意进攻时间,A1需要A2的确认,A2需要A1确认收到A2的确认,以此类推。由于通信不可靠,每次确认都可能丢失,导致无法达成确定的共识。
两将军问题最早由E.A.Akkoyunlu, K.Ekanadham和R.V.Huber在1975年发表的论文《SOME CONSTRAINTS AND TRADEOFFS IN THE DESIGN OF NETWORK COMMUNICATIONS》中提出,就在这篇文章的第73页中,描述两个黑帮之间的通信,同时论文也给出了这类问题无解的证明。1978年,在Jim Gray的《Notes on Data Base Operating Systems》一书中,被命名为*“两将军悖论(Two Generals Paradox)"*。
两将军问题说明,在不可靠通信环境下,无法通过有限次消息交换达成绝对的共识。
严格来说,两将军问题在理论上是无法完全绕过的,然而,在实际工程中,可以通过以下方法缓解或规避两将军问题的限制,使系统在实际场景中可行:
- 以数量赢得概率:这种方案的思路是,同一时间同时发送多个确认消息,如果接收方收到了其中的部分消息,就认为可以发起行动。例如在两将军问题中,任意一方不再是派出一名信使来传递消息,而是同时派出多名信使,例如同时派出100名信使,如果接收方能收到其中的10条消息(即1/10的概率),就认为收到消息。然而,从工程上而言,这样的做法性能不友好。
- 引入超时和超时后的默认动作:接收方可以设定一个默认接收消息时间,在这个时间仍然收不到对方的消息,就采取一个默认的安全动作。例如在两将军问题中,发出开始进攻的军队约好在早上九点发起进攻,但是如果在9点十分之前都没有收到进攻信号,就默认放弃进攻。这样的默认行为,虽然无法攻下城市,但是却不用冒单方面进攻导致失败的风险。在分布式系统的设计中,也有不少超时之后采用默认行为的设计,例如在Raft算法中,Follower节点在选举超时之前没有收到来自Leader节点的消息,就默认Leader节点出现故障,这时会采取发起新一轮的选举流程。
考虑现实中两台计算机需要进行通信的场景。在这种情况下,通信的挑战仍然是不可靠的通信信道,所以这也是两将军问题的现实场景之一,而TCP(Transmission Control Protocol)2协议可以认为是两将军问题的(部分)工程解。
本书中并不打算完整阐述TCP协议的实现原理,感兴趣的可以参考相关书籍,这里重点阐述TCP如何在一个不可靠的通信信道上进行通信,以达到部分解决两将军问题的目标。
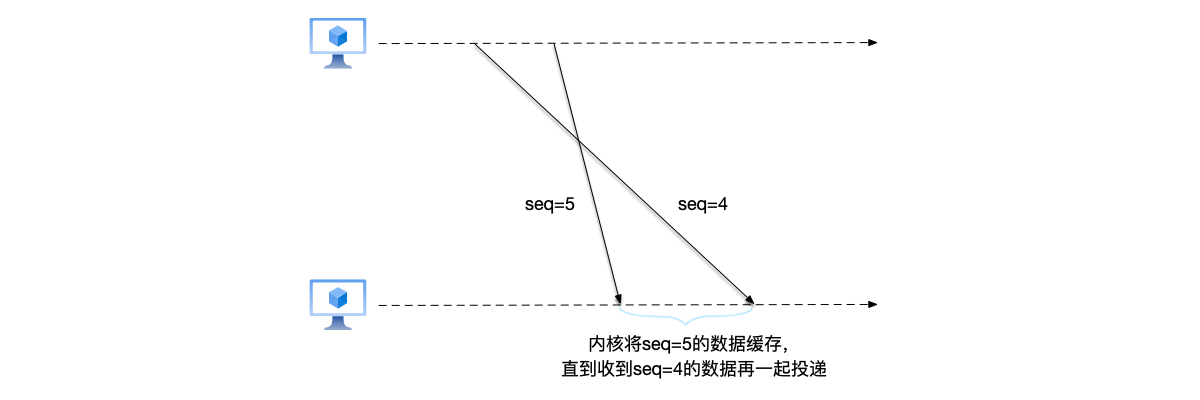
TCP协议中,每个数据包都有唯一的*序列号(Sequence Number)*与之对应,接收端收到数据包之后,通过发送确认包文(Acknowledgment, ACK)来应答收到数据包。通过这个机制,TCP协议解决了数据包乱序到达的问题。考虑如下的场景:如果发送端向接收端分别发送了序列号为4和5的数据包,但是接收端首先收到的是序列号为5的数据包,如果马上向应用层投递seq=5的数据包,将导致数据乱序问题。为了避免乱序投递数据,内核会首先判断该数据包前面的所有数据包是否都已经被投递给应用层,只有在该数据包是当前最早的未投递数据包的情况下才会被投递。在这个场景中,seq=4的数据包还未收到,于是内核会首先将seq=5的数据包缓存起来,等待收到seq=4的数据包到来再一起投递。
备注
在 TCP 协议栈的具体实现中,上述"缓存乱序数据"的行为并非无限进行的,而是受到*接收窗口(Receive Window, 简称rwnd)*的严格限制。
TCP 接收端维护着一个滑动窗口结构。当收到乱序报文(如 seq=5)时,内核会检查该报文的序列号是否落在当前允许的接收窗口范围内:
- 如果超出窗口范围:该报文会被直接丢弃,以保护接收端内存不被耗尽。
- 如果由于之前的报文缺失(如 seq=4 丢失)导致乱序:TCP 协议栈会将 seq=5 放入乱序队列(Out-of-Order Queue)中暂存,并向发送端发送针对 seq=4 之前数据的重复 ACK(Duplicate ACK),触发发送端的快速重传(Fast Retransmit)机制。
- 只有当缺失的 seq=4 最终到达时,TCP 才会将 seq=4 与乱序队列中的 seq=5 拼接成连续的字节流,推进滑动窗口的左边界,并最终提交给应用层。这一机制体现了分布式系统设计中的一个重要权衡:通过消耗接收端的内存空间,换取网络传输带宽的节省(避免重传已到达的乱序包)。
序列号解决了乱序投递问题,而数据丢失问题则由超时重传机制来解决。在TCP协议中,发送端发送数据包之后,就会开启一个针对该数据包的重传超时时间,如果在指定时间内还没有收到接收端的ACK应答报文,就认为这个数据包丢失,此时将重传该数据包。TCP协议将尽力多次重传保证数据包能传送成功,如果在多次重传都失败以后,将不再尝试返回错误。
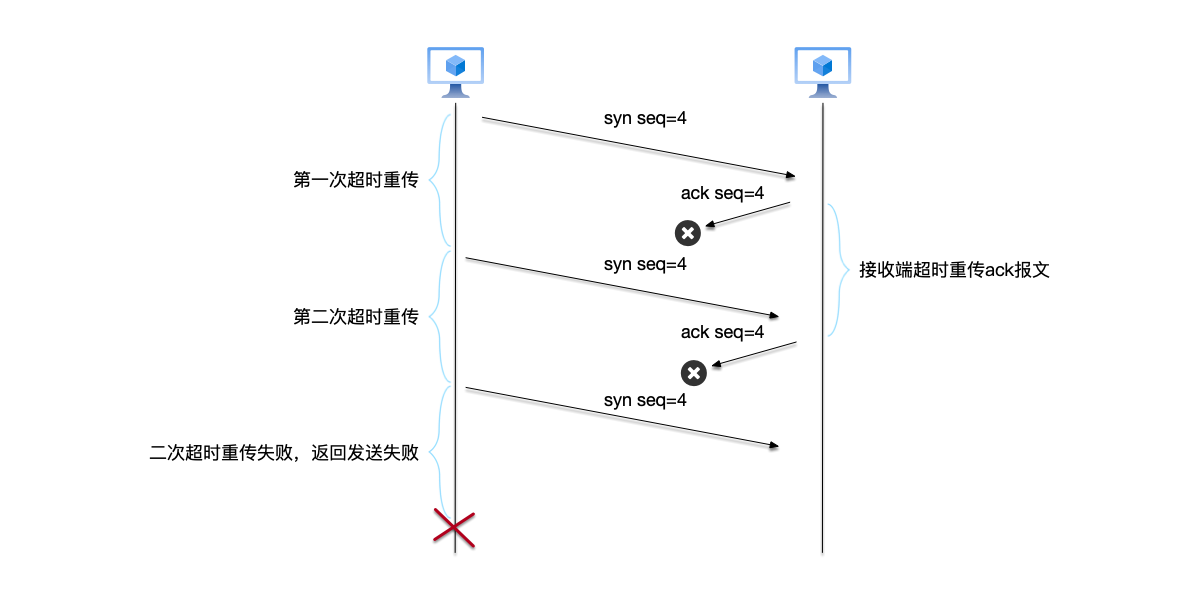
我们看到了TCP协议通过序列号机制来解决乱序,以及通过重传机制尽力让每个数据包都能发送成功,这些机制都极大地提高了通信的可靠性。但是TCP协议仍然没有办法完全解决两将军问题,只能说是工程实现上的部分解法。例如,如果有人拔掉网线,无论重传多少次,数据肯定也无法被发送或者接收成功。
备注
在上图中我们可以看到,接收端发送ACK应答报文时也需要超时重传,这意味这发送端同样需要有针对ACK应答报文的应答。上面针对TCP协议的讲解中,为了简单起见,省略了很多细节,感兴趣的读者可以进一步参考前面推荐的书籍。
另外,在上图中,两次重传失败就认为发送失败,这也是一个简化的表达。
拜占庭将军问题 #
拜占庭将军问题(Byzantine Generals’ Problem)3最早由Lamport在论文《The Byzantine generals problem》中提出,同样是一个关于分布式系统的思想实验。两将军问题讨论的是分布式系统中网络通信上的原因,导致系统会出现的问题;而拜占庭将军问题,则讨论的是分布式系统中的节点会出现的问题。
和两将军问题类似,拜占庭将军问题也假设了一个军队协调攻击城市的场景。拜占庭将军问题中,军队的行动除了有进攻之外,还有撤退,部分军队进攻,或者部分军队撤退,都有可能导致失败。除此以外,与两将军问题不同的是:
- 在拜占庭将军问题中,参与进攻的军队可能超过两个;
- 在拜占庭将军问题中,假设了军队之间通信的消息,总是会被正确接收,不会出现两将军问题中信使被俘获导致消息无法到达的情况。即可以认为在拜占庭将军问题中,通信都是可靠的。
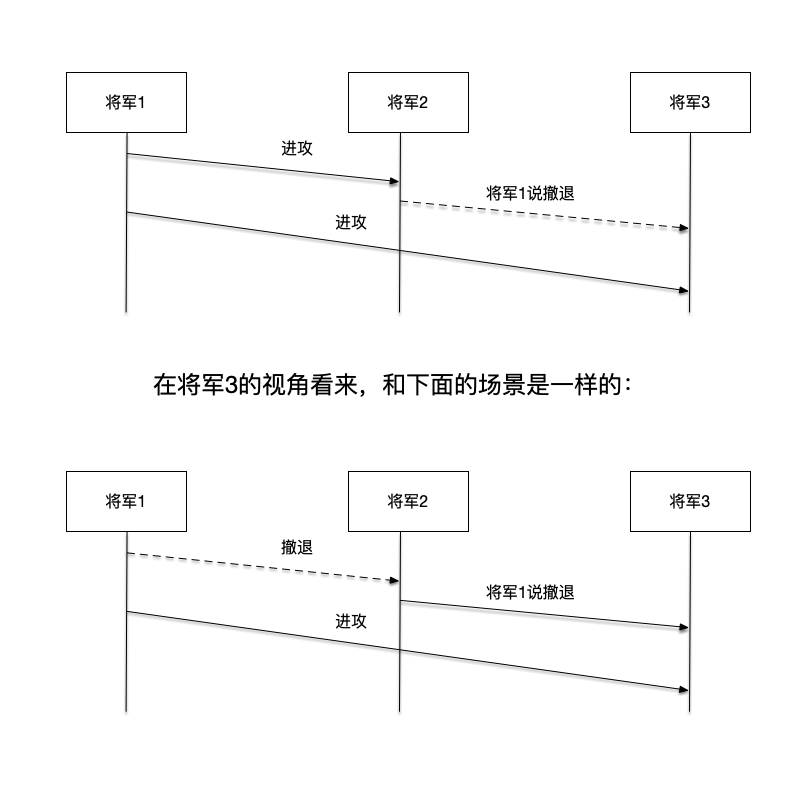
拜占庭将军问题中,假设了不会存在两将军问题中的不可靠通信问题,但是它引入了新的问题模型:参与进攻的将军里,可能出现叛徒。这些叛徒可能会篡改消息,也可能会故意发出误导消息。
如图中所示,举了两个例子说明出现叛徒时的情况,在图中,正常的消息使用实线表示,而叛徒发出的恶意消息使用虚线表示。图中的上半部分,将军2在收到将军1的进攻消息之后,向将军3传递被篡改后的恶意消息:将军1说撤退,而将军3随后收到了将军1发出的进攻消息,这两个相互矛盾的消息让将军3陷入了疑惑:到底是谁说了谎话。在这个场景里,叛徒节点在传递消息时,恶意篡改消息的内容。
同样的,在图中的下半部分里,叛徒变成了将军1,他对将军2说撤退,而对将军3说进攻。在这个场景里,叛徒节点恶意给不同的节点传递误导性的消息。
虽然这是两个不同的场景,但是在将军3看来,看到的是两条同样矛盾的消息。
将拜占庭将军问题映射到分布式系统里,将军便是分布式系统中的节点,信使就是节点之间的通信链路,拜占庭故障的模型描述的是:在一个分布式系统中,可能存在某些恶意节点,这些节点会篡改、或者发送误导性的消息,引发系统的故障。
在Cynthia Dwork等人的论文《Consensus in the presence of partial synchrony》中,论证了在一个有恶意节点和不可预测通信延迟的系统中,拜占庭将军问题只有在严格少于三分之一的节点是恶意的情况下,才能得到解决。也就是说,在一个具有$3f+1$个节点的系统中,不超过f个节点是恶意的。例如一个有4个节点的系统,最多能容忍1个恶意节点。
在某些分布式系统中,需要考虑系统中可能存在某些恶意节点的情况,这样的系统被称为拜占庭容错系统(Byzantine fault tolerant),例如在区块链和加密货币领域。这样的系统中,需要提供保证,即使存在恶意节点的情况下,系统也能正常运行。我们将在本章后面继续讨论这个话题。
系统模型 #
在本章的前两个小节,分别讨论了两个分布式系统的思想实验:
- 两将军问题:该实验演示的是网络通信可能导致的故障;
- 拜占庭将军问题:该实验演示的节点行为可能导致的故障。
这两个思想实验都过于"理想化"了,它们都假设系统之后只有一种类型的故障来讨论问题。现实的分布式系统中,通常会同时存在多种类型的故障。在设计一个分布式系统前,需要首先明确系统所处的环境,需要容忍什么类型的故障,满足什么类型的数据一致性要求。例如,在后面共识算法中描述的Paxos、Raft算法,就不是一个能够在拜占庭故障环境下工作的共识算法。
分布式系统模型讨论的是描述和分析分布式系统行为的理论框架和抽象概念,旨在帮助理解、设计和优化分布式系统。它主要包含以下内容:
- 通信模型:描述节点间如何交换信息。
- 故障模式:描述节点会出现怎样的故障。
- 时间模型:时间模型定义了我们在设计算法时,对"延迟"这件事到底有多大的把握。
- 一致性模型:分布式系统的不同节点之间,对数据的一致性满足什么要求。
本章中讨论前面三种模型,一致性模型在第X章进行讨论。
通信模型 #
“网络是可靠的”,高居分布式计算的八大谬误之首。在《The Network is Reliable》一文中,列举了各种可能导致网络故障的原因,其中不乏线上的真实例子:网络维护、路由器故障、电源故障等,甚至可能由于不小心拔掉电源或者挖断光缆都可能导致网络故障。
在讨论网络模型时,我们采取更抽象的视角,忽略这些故障的细节。大部分分布式算法假设每个节点之间提供双向消息传递,这被称为点对点(point to point)或单播通信(unicast communication)。
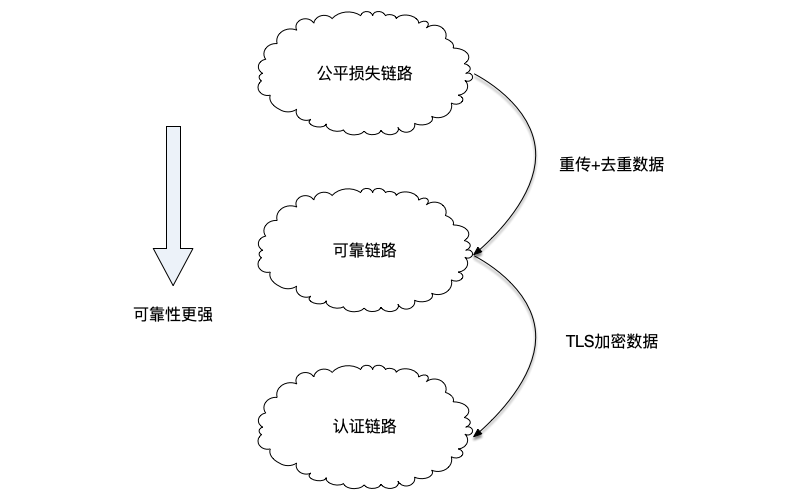
通常而言,有以下几种链接可靠性的保证:公平损失链路(Fair-Loss Link)、可靠链路(Reliable Link)和认证链路 (Authenticated Link)。
公平损失链路 #
在公平损失链路中,消息可能会丢失,某些消息可能会被重排、重发,但是公平损失链路有以下几个核心特性:
- 有限丢失:消息可能会丢,但不会丢得干干净净。如果你发送一条消息无限次,接收方最终会收到无限次。也就是说,只要物理线路没断,成功的概率大于0。
- 消息不会凭空产生:如果接收方收到了一条消息m,那么发送方一定真的发送了m,排除了拜占庭式的恶意伪造。
公平损失链路假设了消息最终会在多次重复后被送达,这条假设意味着,网络分区只会持续一段有限的时间,而不是永远无法恢复。因此只要发送方不崩溃,总可以通过无限重试保证消息最终被接收;然而,如果发送方在消息送达之前崩溃,将无法重试。但它有不少的问题:丢包是常态、消息会重复、乱序。它可以做为所有高级链路的基础,但是却不能基于它直接实现业务逻辑。
可靠链路 #
可靠链路也被称为完美链路(Perfect Link),它具有以下特性:
- 增加消息重传机制,确保消息最终被送达;
- 增加检测和抑制重复消息的机制。
可靠链路保证了所发送的每条消息的可靠传递:如果一个进程发送了一条消息,它最终会得到正确的传递。可靠链路还可以保证不会多次传递任何消息。总之,可靠的传递和无重复的消息意味着由正确进程发送的每条消息都只传递一次。
可靠链路是正是TCP协议试图提供的通信模型,也是Raft、Paxos等算法通常假设的环境,它是我们在分布式系统中追求的标准抽象。
认证链路 #
当系统运行在不可信环境(如公网、区块链等)中,面临拜占庭故障时,仅仅"可靠"是不够的,还需要"安全”。这其中面对的挑战有:
- 中间人攻击:黑客截获了发送消息,修改了内容再发给接收方。
- 伪造数据:黑客伪装成消息发送方,给接收方发消息。
认证链路正是为解决问题而被提出的,它的特性有:
- 完整性(Integrity):消息在传输过程中未被篡改。
- 认证性 (Authenticity):接收方能确信消息确实是发送方发的。
常见的SSL协议,通过建立加密通道的方式实现了认证链路。
这几种网络链路中,可以通过在模型之上增加一些技术手段,将更弱的网络链路转换为更强的网络链路,如下图所示:
- 通过不断重传丢失的消息,直到消息被送达,并且在接收端过滤掉重复的消息,可以将公平链路转换为可靠链路。
- 使用加密技术,将任意链路转换为公平损失链路。例如HTTPS协议,就是通过在HTTP协议上增加TLS加密(HTTPS中的S),防止黑客监听和篡改消息。然而,加密技术无法防止消息被接收端丢弃,因此只有当我们假设接收端用于不会阻断消息通信时,任意链路才能转换为公平损失链路。
备注
尽管TCP协议试图提供可靠链路保证,但是在设计分布式系统时,不要天真地认为TCP就是"可靠链路"。虽然TCP在连接存活时提供了"可靠链路"的抽象,但一旦连接断开(Connection Reset)或机器重启,TCP的上下文就丢失了。因此,真正的分布式系统必须在应用层再实现一套"可靠链路":
- 应用层有自己的请求ID用于去重。
- 应用层有自己的ACK 机制,确认业务处理成功,而不仅仅是 TCP 包收到。
- 应用层有自己的重试策略。
这就是为什么会在Raft论文里看到RPC包含Term和Index:这些就是应用层用来构建跨越TCP连接周期的、真正的可靠链路的工具。
故障模型 #
在真实的系统运行中,可能同时出现节点、网络的故障。如下图所示,节点A向节点B发出请求,要求查询变量x的值,节点B收到请求之后向节点A应答变量x的值为5。
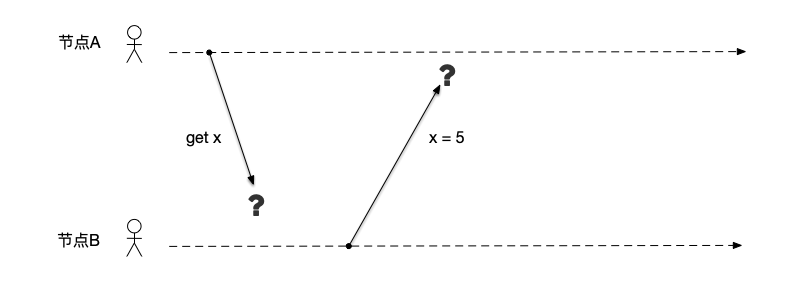
以下是这个简单的通信过程中可能出现的各种故障:
- 节点B由于通信故障,没有收到节点A的请求;
- 节点B收到消息之后,在处理消息的过程中出现宕机而无法应答;
- 由于网络通信延迟,节点B过了很久才收到请求;
- 节点B过于繁忙(例如在处理其他事务),以至于无法应答消息;
- 节点B恶意应答了错误的数据给节点A;
- 消息在收发过程中丢失;
- 节点B应答消息时,节点A发生了宕机,无法收到应答;
- 等等。
可见在这个最简单的场景中,也不可能列举出所有可能发生的错误。然而,可以对故障进行分类,不同的故障模型的设计难度不一样,在设计系统时基于某种故障类型来进行设计。
故障模型(Failure Models)用于定义在分布式系统的工作环境中,机器、网络、软件等到底能"坏"到什么程度。在分布式系统的理论与实践中,故障模型是一个层级结构(Hierarchy)。从最简单的"宕机",到最复杂的"篡改",处理难度呈指数级上升。
崩溃模型 #
在*崩溃故障(crash fault)中,节点会由于各种原因宕机崩溃,例如:硬件故障、软件bug等。按照节点是否能够在崩溃后恢复执行,又分为崩溃-停止(crash-stop)故障和崩溃-恢复(crash-recover)*故障。
崩溃-停止模型
在*崩溃-停止(crash-stop)*故障中,假设一个节点在崩溃之后,永远不再恢复执行。这是最理想化的模型,通常只存在于理论推导或极度受控的硬件环境中。在这个崩溃模型下,节点一旦发生故障,就会立即停止所有操作;系统中其他活着的节点可以准确地检测到该节点已经死亡。处理这个崩溃模型的算法非常简单,比如做主备切换,一旦检测到主节点挂了,备节点立刻接管。
这种故障适用于不可恢复的硬件错误,以及一些*无状态(stateless)*的服务。
例如,某些简单分层的Web服务,包括一个前端的API服务和后端的数据库服务。如果流量增加,一种扩展方案就是在负载均衡器后面添加额外的前端API服务。通过新增API服务器,可以接收更多的用户请求。类似这类系统的设计中,遵循的一个原则就是使前端服务无状态(stateless)。顾名思义,术语"无状态"意味着在创建进程实例时,不会存储过去的数据或状态,也不需要持久化数据。使用无状态的API服务,意味着每个单独的API服务中,不会在单个请求的上下文之外跟踪用户的任何信息。无状态服务的一个优点就是可以随时停止,也可以随意启动,启动时不需要尝试恢复状态,这给系统的扩缩容提供了便利。
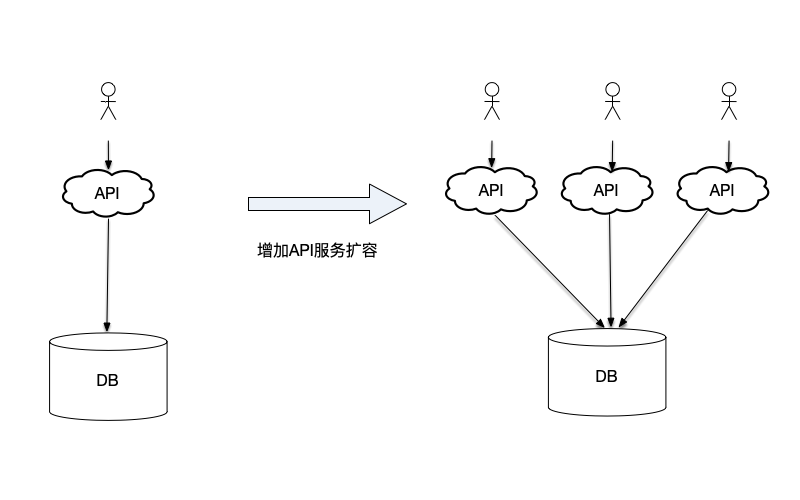
另一个例子,在Kubernetes中的无状态服务。在Kubernetes的无状态节点模式中,服务由多个Pod组成。每个Pod在其生命周期内仅运行一次,一旦Pod被重启,可能被调度到另外的节点去运行。每次创建一个Pod,分配一个唯一的ID,如果一个节点宕机,调度到该节点的Pod将在超时后被删除。如果配置Pod为遇到故障后重启,在故障发生时Pod将丢弃内存中的所有数据,重启Pod时也不会尝试恢复崩溃之前的状态。
崩溃-恢复模型
*崩溃-恢复(crash-recover)*故障,指一个节点在崩溃之后,通过重新启动,继续执行后续的操作。在这种故障里,我们假设节点会崩溃,但是总可以在一段时间内恢复,如果需要恢复到崩溃之前的状态继续执行,可以通过读取持久化存储数据等手段来恢复数据。这是工业界分布式存储系统最核心的假设模型。在这种模型下,可能出现以下的现象:
- 节点可能会在任意时刻崩溃,停止响应。
- 节点可能会在一段时间后重启并重新加入集群。
- 节点的"记忆"可能会丧失:内存中的可变数据(Volatile State),如锁、缓存、未提交的的事务等,会全部丢失。
因此,这类系统的核心挑战在于,节点在崩溃恢复后,如何获得当前集群的最新状态,例如:
- 节点重启后,它的状态是旧的(Stale)。它必须知道自己落后了多少,并从其他节点那里"补课"。
- 一个节点如果是Leader节点,在它宕机后,集群选出了新的Leader节点。过了一会儿旧Leader节点重启了,它还以为自己是Leader节点,试图发号施令。
数据库服务,就是最典型的崩溃-恢复故障类型的服务。在进程发生故障时,数据库会通过加载崩溃之前的快照数据、重放预写日志(Write Ahead Logging)4等方式来加载之前的状态,以恢复崩溃前的数据。
在Kubernetes中,开发者可以使用类型为StatefulSet的方式来创建应用程序,这种方式创建的Pod,可以提供唯一性保证,这个保证即使在重启、再调度后都能被保持。在单个Pod发生故障时,使用Pod标识符可以从现有的数据卷中读取数据,以恢复状态。
遗漏模型 #
遗漏故障(Omission Fault),这类型故障指的是某种情况下,节点会遗漏发送或者接收一些消息。导致遗漏故障的原因,通常有网络不稳定导致的数据包丢失、系统资源耗尽等。
这个模型比崩溃模型的问题更隐蔽。节点还在运行,但它无法正常收发消息。它的核心挑战是:
- 故障检测失效:节点的心跳包可能发不出来,被误判为"死亡"。但实际上它还在写磁盘,还在处理本地逻辑。这极易引发数据不一致。
- 非对称网络:节点A能发给节点B,但节点B不能发消息给节点A。
为了更直观地理解遗漏故障,我们可以深入到操作系统的内核与网络硬件层面。在工程实践中,遗漏故障往往表现为一种"隐性丢包(Silent Drop)",这比明确的报错更难排查:
- 接收端遗漏:当一个节点负载极高(例如 CPU 100% 满载)时,虽然操作系统内核仍在运行,但它可能无法及时处理网卡中断。此时,网卡的硬件缓冲区(Ring Buffer)或操作系统的内核接收队列会迅速填满。一旦溢出,网卡会直接在硬件层面静默丢弃后续到达的数据包。应用层在这种情况下完全感知不到有消息到达,而在发送端看来,就像是消息石沉大海。此时节点还在处理本地磁盘 I/O,但在集群网络中它已经是一个’黑洞’。
- 发送端遗漏:在交换机或路由器等中间设备层面,如果发生瞬时的微突发流量(Micro-burst),导致交换机端口的缓冲区耗尽,数据包也会被中间设备丢弃。节点 A 成功调用了 send() 接口并获得了成功返回(因为数据写入了本地 socket 缓冲区),但数据包从未真正抵达节点 B。
常见的技术方案有:
- 重试与确认:要求消息都要在得到接收端确认后才能接收成功,如果一直没有收到确认消息,将尝试重传消息,把"遗漏"转化为"延迟"。
- 租约:如果要执行写操作,必须持有有效的租约。如果发生遗漏故障导致无法续租,租约过期,节点被迫停止服务(即使它觉得自己还活着)。
拜占庭模型 #
在*拜占庭故障(Byzantine fault)*模型中,节点可以执行任意操作,包括崩溃或者恶意行为。当为这类模型设计算法时,算法不能对故障过程中的行为做出任何假设。
这类模型是最为通用的模型,也是最难设计算法的。就性能和存储成本而言,这类模型是成本最高的。但是,当可能会发生未知或不可预测的故障时,这类模型是唯一合理的选择。
注意这里提到的"任意故障",不一定都是恶意或者故意造成的,也可能是由于实现时的考虑不完善、框架或者系统的Bug、硬件故障导致的故障。
例如比特币5这样的去中心化网络,其中可能存在一些试图欺诈以谋取利益的参与者,在这样的系统里,信任其它节点的消息或者数据是不安全的。在比特币中,通过工作量证明(Proof Of Work,简称POW)6来规避这一问题。
在《A Byzantine failure in the real world》7一文中,Cloudflare团队提到了在2020年线上项目由于交换机异常导致的故障。
故障层次
故障之间有如下图所示的层次关系,最内层的崩溃-停止模型是最容易处理的,最外层的拜占庭模型是最难处理的。如果一个系统能够处理在外层中更难的故障类型,自然也可以处理内层中的故障类型,例如能处理崩溃-恢复模型的系统,就一定可以处理崩溃-停止模型的系统。我们从内到外逐一做解释。
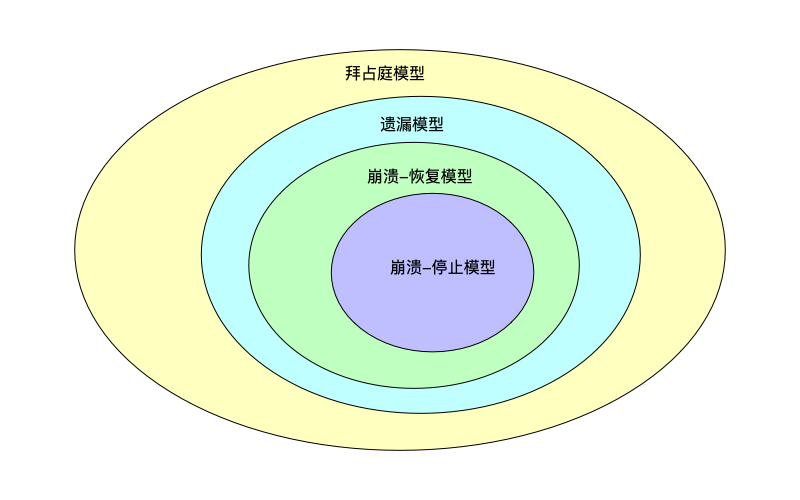
崩溃-停止模型
在崩溃-停止模型中,节点在宕机后将停止运行,不再恢复运行。因此,它的故障行为集合非常小,只有$\{Stop\}$。
崩溃-恢复模型
在崩溃-恢复模型中,节点在宕机后将可以恢复运行。因此,可以把崩溃-停止模型视作它的特例:节点崩溃了,但是在重新启动的这段时间内,恰好还没有恢复(或者恢复时间无穷大)。它的故障行为集合,有$\{Stop, Restart\}$。
遗漏模型
遗漏模型中,节点可能丢弃发送的消息,也可能丢弃接收的消息。从这个特性来看,崩溃模型本质上就是一种极端情况下的遗漏模型。当一个节点崩溃时,它不再发送消息,也不再处理接收的消息。这在外部观察者看来,就是100%的发送遗漏 和100%的接收遗漏。除此以外,遗漏模型还允许节点处于某些中间的状态,比如网卡坏了,它能收消息但发不出去;比如CPU繁忙的情况下丢弃部分包。
在崩溃模型中,节点一旦没有响应消息,就知道节点宕机或者在重启恢复。但在遗漏模型中,同样的节点没有响应消息,它可能还活着,甚至还在写磁盘,只是网络包丢了。系统如果误判节点宕机而选新主,可能会导致双主。
综上,遗漏故障的行为集合,有$\{Stop, Restart, Drop\_Send, Drop\_Receive\}$。
拜占庭模型
拜占庭模型的行为模式是:节点可以发送任意数据,包括谎言、伪造、矛盾的消息。从这个特征看,遗漏模型只是其中一种特殊的情况:一个拜占庭节点可以选择"假装没收到节点的消息"(模拟接收遗漏),或者"假装作发不出消息"(模拟发送遗漏),或者"我直接宕机"(模拟崩溃)。除此之外,拜占庭节点还可以做遗漏模型做不到的事:它不丢消息,但它可以篡改消息,例如把消息里的Agree改成Reject再发给节点。
遗漏模型虽然丢包,但只要收到了包,包的内容是可以信任的;但在拜占庭模型中,节点即使收到包也不能信任,必须校验签名、防篡改。
综上,拜占庭故障的行为集合,有$\{Stop, Restart, Drop, Lie, Forge, ...\}$,是一个所有可能出现的故障合集。
工程师需要了解不同的故障模型,以及其兼容关系,以确保设计的系统能够正确应对系统所处环境可能出现的故障,同时也避免过度设计,因为不同的故障模型设计难度大不相同。例如,在一个可信赖的内网中搭建的系统,就不必设计为一个满足拜占庭故障的系统;反之,系统如果暴露在外网,任意节点都可能接入这个系统,就要将其设计为一个满足拜占庭故障的系统。
时间模型 #
系统假设的时间界限和通信延迟,在很大程度上决定了解决问题的最终算法。一般分为以下三种时间模型:同步模型(synchronous)、异步模型(asynchronous),以及半同步模型(partially synchronous),这三类模型,决定了对"延迟"这件事到底有多大的把握,这是理论界(如 FLP 不可能定理)与工业界(如 Raft/Paxos)分道扬镳的分水岭。
同步模型
同步模型是最理想、最简单,但在互联网环境下几乎不存在的模型。它表示在一个系统中,对三个物理属性有严格的*上限 (Upper Bound)*限制:
- 消息传输延迟有上限:如果节点发送一条消息,知道它最晚会在 $\Delta$ 时间内到达。如果 $\Delta$ 时间没到,系统就能 100% 断定网络断了或者对方宕机了。
- 处理器速度有下限:每台机器执行一步指令的时间是可预测的,不会无限慢。
- 时钟漂移有上限:两台机器的时钟误差不会超过 $\epsilon$。
这些假设都意味着,对这样的系统进行故障检测是非常简单的。
异步模型
异步模型则走到了和同步模型之外的另一个极端,它表示在一个系统中,对三个物理属性没有任何限制:
- 消息延迟无上限:消息可能会在网络里游荡1毫秒,也可能是 100 年,只要它最终能到,就算符合模型。
- 处理速度无下限:一台机器可能突然被操作系统挂起(Sleep)或者进入长时间GC,暂停个几分钟再醒来。
在异步模型中,这些假设意味着:
- 无法区分"慢"与"死":如果节点A发给节点B的消息没回音,你永远不知道节点B是宕机了(Crash),还是仅仅是网络极慢,或者是节点B正在处理复杂的计算。
- FLP 不可能定理 (FLP Impossibility):在异步系统中,只要有一个节点可能崩溃,就不存在一个确定性的共识算法能保证总是达成一致。
半同步模型
同步和异步模型都过于极端,更多的情况下,系统处于半同步模型下,这是工业界的主战场。它的核心特征是:系统在大部分时间表现得像同步系统,但在不可预测的、有限的时间段内表现得像异步系统。
系统可能违反同步假设的原因有很多,我们在下面列举一些常见的原因:
- 消息丢失后需要进行重传,尤其在发生网络分区的情况下,延迟的上限可能是无限的;
- 网络拥塞也会导致消息延迟,这会导致数据包在交换机缓冲区中排队;
- 网络重新配置也可能导致较大的延迟,Github在2012年的一次事故中8,单数据中心内显示出现了数据包被延迟超过一分钟的情况;
- 在节点上执行算法时,预期速度是恒定的,毕竟每条指令都有固定数量的CPU时钟周期。但是同样也有可能导致运行的程序暂停较长的时间,以下是一些可能的原因:
- 操作系统的内核调度机制,可能会抢占某些正在运行的进程暂停执行,而让其他进程运行;
- 在Java这样的GC类语言中,由于垃圾回收器运行导致的系统暂停(Stop-The-World,简称STW);
- 在剩余内存空间不足的情况下,程序向内核申请内存时可能会发生的缺页中断、内存交换等,都可能导致进程被挂起。
本章小结 #
本章作为全书的理论基石,重点探讨了如何对复杂的分布式系统环境进行抽象和建模。我们认识到,与单机系统不同,分布式系统没有共享内存和全局时钟,且面临着网络和节点的各种不确定性。为了应对这些挑战,我们通过思想实验和理论模型,界定了系统设计时必须考虑的边界条件。
本章首先通过两个经典的将军问题,揭示了分布式系统中最本质的两类困难:
- 两将军问题(网络的不确定性):演示了在信道不可靠的情况下,试图达成共识会遇到的"无限确认"陷阱。它证明了在不可靠通信环境下,无法通过有限次消息交换达成绝对共识。虽然TCP协议通过序列号和重传机制缓解了这一问题,但它只是工程上的部分解,而非理论上的完全解。
- 拜占庭将军问题(节点的不可信性):演示了当系统中存在恶意节点(叛徒)篡改或伪造消息时带来的挑战。理论证明,在一个包含恶意节点的系统中,只有当恶意节点数量少于1/3 时,共识才可能达成。
为了更精确地分析系统行为,我们定义了三种核心模型,它们共同构成了分布式算法设计的环境假设:
- 通信模型:我们介绍了公平损失链路、可靠链路和认证链路。虽然TCP提供了连接存活期间的可靠传输,但真正的分布式"可靠链路"必须在应用层实现,包含请求 ID 去重、业务层ACK和重试策略,以应对连接断开和机器重启后的上下文丢失。
- 故障模型:我们构建了一个从简单到复杂的故障层级结构
- 崩溃-停止:最简单的模型,适用于无状态服务。
- 崩溃-恢复:工业界最常见的模型(如数据库、Kubernetes),节点可能重启,面临状态丢失和"补课"的问题。
- 遗漏故障:节点可能丢失消息或没发出消息,故障检测极难。
- 拜占庭故障:最复杂的故障模型,节点可以任意撒谎或表现出恶意行为,包含上述所有故障类型 。
- 时间模型:时间模型决定了算法对"超时"的判断依据
- 同步模型:对延迟、速度和时钟漂移有严格上限,现实中极其罕见。
- 异步模型:消息延迟无上限,导致无法区分节点是"慢"还是"死"。
- 半同步模型:工业界的主战场,假设系统大部分时间是同步的,但允许短暂的异步状态(如网络拥塞、GC 导致的 STW) 。
通过本章的学习,我们不仅掌握了理论名词,更重要的是理解了模型之间的权衡。工程师在设计系统时,必须明确所处的环境模型:是在可信内网中处理崩溃恢复(如 Raft),还是在开放网络中防御拜占庭攻击(如区块链)。