在分布式系统中,多个节点协同工作。客户端请求会发送不同的节点上处理,这些请求就成为了一个一个的节点上的事件。我们将看到,系统的状态由这些一个一个的事件按照特定的顺序执行之后形成。因此,事件的顺序尤为重要。不同的节点中,看到的事件先后顺序可能会有差别,这也造成了这些节点可能形成不同的状态。
由此可见,处理多个事件时,事件的先后顺序将影响节点的状态,因此如何测量事件的顺序就成了分布式系统中的一个核心问题。一个自然的想法是,按照事件发生的物理时间排序即可。我们将在后续章节了解物理时钟原理,从而遗憾地发现:在一个分布式系统中,通过对比多个节点之间的物理时间来判断事件发生的先后顺序并不精确,甚至有时候会发生错误,而一旦事件的顺序错乱,整个分布式集群的状态也就错乱了。
如果物理时间不可行,那么还有什么办法决定一个分布式系统中事件的先后顺序?答案是逻辑时钟。
令人惊讶的是,前面我们一再谈及事件的先后顺序尤为重要,但是在分布式系统中,还可能出现两个事件无法判断其发生先后顺序的情况,这样的事件称为*“并发事件”*。为了解释事件的顺序,我们还需要了解两个数学中的定义:偏序和全序。事实上,这两个数学定义应该深植在每个分布式系统工程师的心里,在后面我们还会一再见到这两个定义在分布式系统中的应用。
我们将在本章中讨论以下的主题:
- 事件发生的先后顺序是如何影响系统的状态的;
- 物理时间为何不能在分布式系统中用来衡量事件的先后顺序;
- 逻辑时钟的理论基础和计算规则;
- 偏序和全序的直观解释和定义;
- 基于逻辑时钟延伸出来的向量时钟。
状态、事件和快照 #
在一些刑侦片里,经常看到这样的桥段:警方跟踪的一个嫌疑人,在某一天突然发生了一些变化,于是警方就会调取记录,来查看过去这一天里,嫌疑人去过的地方、见过的人、做过的事情,以了解到底是什么原因导致了嫌疑人的变化。
在这里,“去过的地方、见过的人、做过的事情"就是一个一个的事件,如果把嫌疑人看成一个系统,昨天的嫌疑人,和经历了前面这些事件的嫌疑人,就是这个系统在不同时间的状态。(由此我们不妨思考一个哲学问题,如图1所示:过去的"我”,在经历一系列事件之后,才成为现在的"我",这两个"我"是同一个"我"吗?)

我们用一个简单的存储服务来继续解释状态和事件。如图2所示的一个存储服务,最初的状态为$\{x = 1\}$,在顺序执行了命令$set \ x = 2$和$set \ x = 3$之后,新的状态变成了$\{x = 3\}$。在这里,这两个命令的执行顺序尤为重要,如果调换这两个事件的执行顺序就变成了另一个状态$\{x = 2\}$。
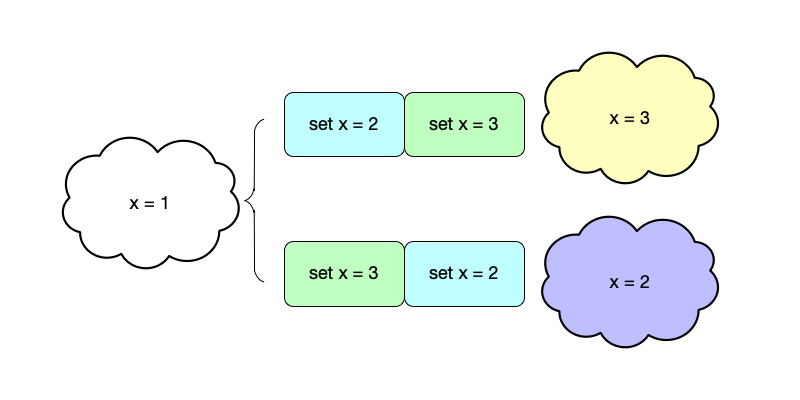
从以上的例子中我们也可以看到,在这里并没有提及事件执行的物理时间,而是更关注事件执行的顺序。之所以更关注事件之间的相对顺序而不是物理时间,是因为在分布式系统中,并不存在全局统一的物理时间,我们将在后续章节继续深入讨论物理时间。如果把系统看做一个大的状态机,事件就是改变这个状态机状态的操作。在一个状态机中,只要保证每一次能够按照同样的顺序来执行事件,就能保证这个系统总是能到达同样的状态。
按照相同顺序执行同样的事件就能得到相同的结果,这也是*状态机复制(state machine replication)*的核心思想:
如果两个不同的进程,以同样的初始状态开始运行,按照相同的顺序来处理输入的数据,将得到同样的输出结果。
备注:我们在讨论了逻辑时钟以后,可以看到事件的执行顺序就是某种意义上的逻辑时间。
另一方面,在不同时间节点上该存储的瞬时状态,就被称为在这个时间点的快照(snapshot)。例如,在车水马龙的街道上,拍下一张照片,就是这个街道在那一瞬时时间点的快照。做为对比,事件是用于改变系统状态的动态数据,而快照就是系统状态的静态数据。
到了这里,我们可以给出状态、事件和快照的直观解释:
- 状态(status):一个系统中所有数据的值,状态会随着事件发生改变;
- 事件(event):能够改变系统状态的操作。在一个服务中,所有写请求(写入、更新、删除等),都可以称为事件;
- 快照(snapshot):快照是一种特殊的状态,快照是静止的状态,一旦确定了快照的时间,也就确定了快照的内容。
如下图所示,如果分别在初始时、执行命令$set \ x = 2$之后和执行命令$set \ x = 3$之后,获取系统的快照数据,则会分别得到$\{x = 1\}$、$\{x = 2\}$和$\{x = 3\}$。
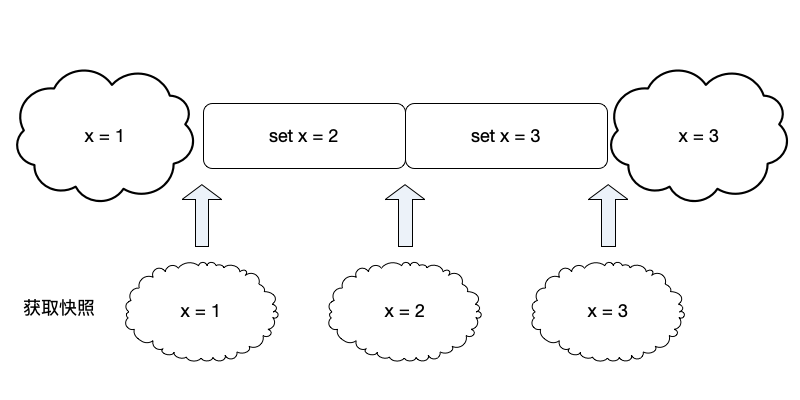
从以上对状态、事件、快照的讲解可以看到,这几个概念都与时间强相关,尤其是事件与时间顺序相关。我们接下来看,如何在分布式系统中衡量在不同节点上事件的先后顺序。
备注:将保存系统的相关数据划分为状态、事件、快照这三类数据,也是分布式系统中进行数据复制时的做法,我们在这里强调了在分布式系统中,事件要在多个副本之间保持同样的顺序,比这个条件更强的要求是确定性,我们将在讨论副本间数据复制时继续讨论这个话题。我们还将在后续章节中看到,共识算法本质上就是在多个副本之间维护同样顺序的日志系统。
物理时钟 #
物理时间源和表示法 #
如今的大多数计算机时钟采用的是石英钟(Quartz clocks)。石英钟通常由电池供电,核心是一个石英晶体(通常是音叉形状)。当对石英晶体施加电压时,它会因压电效应产生机械振动,频率非常稳定(通常为32,768 Hz)。这种高精度振荡是石英钟计时的基础。石英钟每振荡H次,计算机内的定时器芯片就中断一次(被称为时钟滴答(clock tick))。中断处理程序会递增一个计数器,该计数器会记录从过去(纪元)开始的刻度数。知道了每秒的刻度数,我们就可以计算出年、月、日和时间等。
石英钟价格便宜,但是却不够准确。由于制造工艺的差异,每个石英晶体的振荡频率并不相同。其次,石英晶体的工作温度是室温,温度的升高/降低会改变其振动频率。由于每台计算机都配有石英钟,振动的差异意味着不同计算机主机中的时钟可能会发生漂移,一个节点运行缓慢,而另一个节点运行快速。
石英钟可能会由于环境因素导致振动频率被改变,导致石英钟的运行速度就会发生变化。那么能不能找到这样一种物质,如果这个物质能够一直以一个恒定的频率来振动,那么就可以将时间表示为物质振动的次数。20世纪30年代,伊西多·艾萨克·拉比和他的学生们在哥伦比亚大学的实验室里研究原子和原子核的基本特性。最终他发现某些原子的共振频率的准确性非常之高,可以用来制造高精度的时钟。*原子时钟(atomic clocks)*正是基于原子的共振来设计的计时设备:它基于量子力学原理构建,是目前人类掌握的最为精确的计时技术,其误差在数百万年内仅为一秒。这种极致的精度源于原子内部电子在特定能级间跃迁时所辐射的电磁波频率。该频率具有极高的稳定性,几乎完全免疫于温度、压力等外界环境的干扰。
实际上,国际原子时(International Atomic Time,简称TAI) 正是基于此原理定义了时间的基准单位:1秒被定义为铯-133原子基态的两个超精细能级间跃迁辐射震荡 9,192,631,770 个周期的持续时间。尽管原子时钟造价高昂,但凭借其无可比拟的准确性,它已成为科学研究、现代通信及全球定位系统(GPS)等关键领域不可或缺的基础设施。
原子时钟看起来工作得很好,但是却忽略了天文学概念中时间的概念。人们对一天时间的感受是日出而作日落而息,“一天"在天文学概念中指的是地球自转一周的时间,由于潮汐、地震、冰川变化等因素影响,地球自转的速度并不是恒定的,例如在2025年8月5日这一天,地球自转速度加速,成为了有史以来最短的一天,这一天的时长比86400秒少了1.25毫秒。
这样看来在"一天到底有多长时间"这个问题上,我们遇到两个不同的定义:一个是基于量子力学机制的原子时钟,另一个是基于天文学的定义,而这两者定义的一天时间并不一直都能精准匹配上。
为了解决这个问题,1972年*协调世界时(Coordinated Universal Time,简称UTC)*面世,它基于原子时钟,定义了世界时间标准,由两部分构成:
- 原子时间TAI,它是全球数百个原子时钟的加权平均值。
- 在原子时间的基础上,通过时间的微调整与*世界时(Universal Time,简称UT)*保持大致同步。
为了使UTC与地球自转时间保持在0.9秒以内,国际地球自转和参考系统服务(International Earth Rotation and Reference System Service,简称IERS)会根据需要插入或删除闰秒(leap second)。闰秒通常在6月30日或12月31日的最后一秒实施,将UTC时间调整为23:59:60。这种调整使UTC既保持原子时的精度,又大致与地球自转的"太阳时"同步。如果需要进行闰秒调整,会提前一年会由相关的机构公布下一年的闰秒调整时间,例如在2016年12月,中国国家授时中心发布的《国家授时中心闰秒公告》中提到:
2016年7月6日,巴黎国际地球自转服务组织IERS在第52期C公报向全球负责标准时间测量和发播的机构发布闰秒公告:国际标准时间UTC(Coordinated Universal Time,协调世界时)将在2017年1月1日实施一个正闰秒,即增加1秒。7月11日国际权度局时间部BIPM向全球参加国际原子时TAI归算的各守时实验室发布了闰秒调整预报。由于时差的原因,我国将在北京时间2017年1月1日的7时59分59秒和全球同步进行闰秒调整,届时会出现7:59:60的特殊现象。

备注:协调世界时的缩写是UTC,这显然不是"Coordinated Universal Time"的首字母缩写。背后是一个妥协的故事:国际电信联盟希望协调世界时能够在所有语言有单一的缩写。英语和法语区的人同时希望各自的语言缩写-CUT和TUC能够成为国际标准,结果最后妥协使用UTC。
在军事中,协调世界时区会使用"Z"来表示。而在航空上,所有使用的时间划一规定是协调世界时。而且Z在无线电中应以北约音标字母读作"Zulu”,协调世界时也会被称为"Zulu time"。比如说飞机在北京时间(UTC+8)18:00整起飞,就会写成1000z,又或者读作"1000Zulu"。
UTC时间的出现,统一了世界时间的标准,不同国家和地区的时区也以UTC来定义。如果本地时间比UTC时间快,例如中国的时间比UTC快8小时,就会写作UTC+8,俗称东八区。相反,如果本地时间比UTC时间慢,例如夏威夷的时间比UTC慢10小时,就会写作UTC-10,俗称西十区。
闰秒的出现给某些计算机程序带来了复杂度和潜在问题的可能性。因为根据闰秒的概念,一天的时间并不见得总是有86400秒,也有可能是86399秒(删除一个闰秒)或者86401秒(增加一个闰秒)。闰秒给计算机系统的时间测量带来了新的问题,要了解这一点,我们需要先了解计算机系统中的时钟系统。
墙上时钟和单调时钟 #
现代计算机系统中,有两套时钟系统:墙上时钟(Wall Clock)和单调时钟(Monotonic Clock),这两套时钟分别用来回答不同的问题,搞清这两个时钟系统的区别,有助于加深理解分布式系统中的时间问题。
墙上时钟
顾名思义,“墙上时钟"可以理解为挂在墙上的时钟,它用于回答"现在是什么时间”。计算机领域最常用的Unix时间,表示自从1970年1月1日开始所经过的秒数。Linux系统下的clock_gettime(CLOCK_REALTIME)和Java语言里的System.currentTimeMillis()都可以用来获得系统的Unix时间。
Unix时间不考虑闰秒,因此任何使用Unix时间计量时间差的代码,都要额外考虑是否需要关注闰秒问题。历史上由于闰秒导致了不少互联网领域的大故障,例如2012年6月30日,全球时间多出一秒,引发互联网大混乱。LinkedIn、 Reddit 和 Mozilla 等主流平台遭遇部分中断,无数 Linux 服务器(包括众多 Red Hat 、 Debian 和 Ubuntu 厂商的服务器)CPU 利用率飙升至 100%,开始死机。
备注:从Unix时间的定义可以知道,这个时间表示法的单位是秒,但是也有某些API提供另外单位的Unix时间。例如Java的System.currentTimeMillis()函数,提供的是自从1970年1月1日开始所经过的毫秒数。
除了闰秒问题,我们在后面还会看到,在采用NTP协议进行时间同步时,墙上时钟还会发生回跳等现象。
单调时钟
与墙上时钟不同的是,单调时钟回答的是时间差问题,即:“时间过去了多久”,它就像计算机系统中的秒表,告诉开发者系统已经运行了多长时间。它表示的是从"某个任意时间点"(通常是操作系统启动那一刻)开始经过的时间。这个绝对数值(比如 43567890 纳秒)本身没有意义,只有两个单调时钟的差值才有意义。
正因为单调时钟满足单调递增的特性,无论NTP协议如何调整系统时间,单调时钟只会一直往前走,不会发生回退。即使在NTP协议发现本地时钟跑太快了,它也不会简单粗暴地把单调时钟拨回去,而是会微调时钟的频率(Slewing),让它走慢一点点,直到追平标准时间,但单调时钟的数值依然是增加的。
需要强调的是,由于单调时钟的起始时间通常是操作系统启动的时间,因此两台不同的机器之间的单调时钟不能进行对比。也就是说,单调时钟不能够跨节点对比。
有了对这两种时钟系统的了解,我们可以接下来看系统如何进行物理时间的同步。
物理时间同步 #
基于量子物理学构建的原子钟精度更高,但价格昂贵。为了解决计算机上时间精度不高的问题,计算机定期通过时钟同步协议与高精度的时间系统同步时间。*NTP(Network Time Protocol)*是目前最主流的时钟同步协议,几乎所有的个人计算机、智能设备、移动设备都使用NTP进行时钟同步。
NTP协议分为多个层次来组织结构,层级中的每一层被称为stratum,通常将从最权威的时钟获得时钟同步的NTP服务器层数设置为stratum 1,将其做为主时间服务器,为网络中其它设备提供时钟同步。stratum 1层次以下的stratum 2则从stratum 1获取时间,类似地,stratum 3从stratum 2获取时间,以此类推。时钟层次的取值范围为1~16,取值越小,时间精度越大。
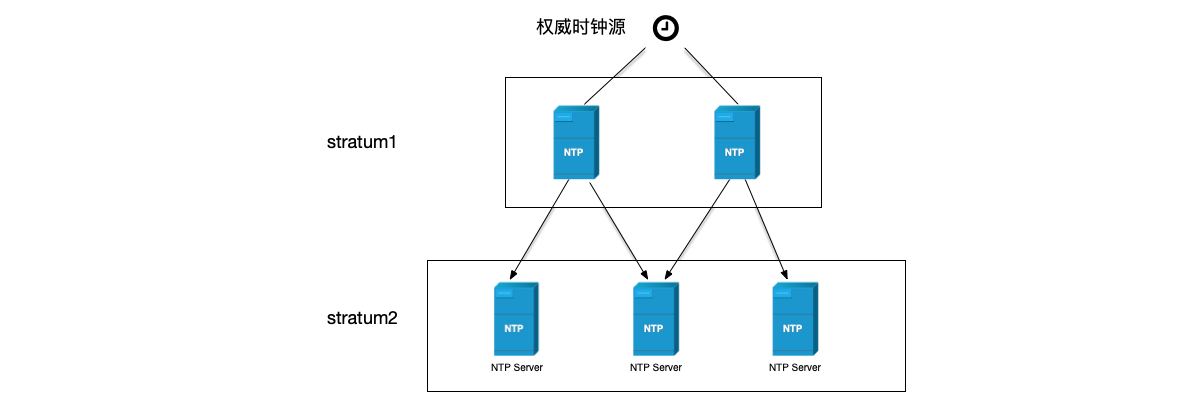
NTP协议是典型的客户端/服务器架构协议,NTP服务器在收到NTP客户端请求之后,应答当前的NTP服务器时间来纠正NTP客户端时间。由于存在网络延迟、CPU处理速度差异等原因,要精确同步时钟,在给NTP客户端的应答中,需要返回服务器接收和发送应答的时间,以便客户端估算延迟时间。
如图是一个完整的NTP请求流程:
- 客户端在时间$t_1$向服务器发送了一个NTP请求报文,其中包含该报文离开客户端的时间$t_1$。
- NTP请求报文在时间$t_2$到达服务器。当服务器收到该报文并且处理之后,于时刻$t_3$发出应答报文。在应答报文中,携带了报文离开客户端的时间$t_1$、服务器收到请求报文的时间$t_2$,以及应答报文离开服务器的时间$t_3$。
- 客户端在时间$t_4$收到来自服务器的应答报文。
可见,如果能计算出客户端与服务器之间的延迟时间差,那么根据服务器应答时间$t_3$,就能推断出当前客户端的时间。
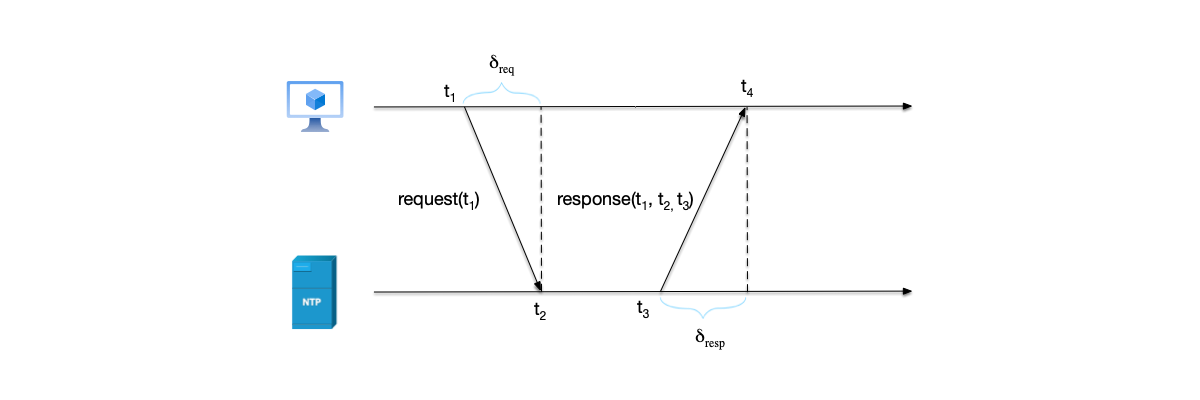
在上面的流程中,存在两个和网络延迟的时间差:
$$ \begin{aligned} \delta_{req} &= t_2 - t_1 \text{,请求延迟}\\ \delta_{resp} &= t_4 - t_3 \text{,应答延迟} \end{aligned} $$总的往返流程的延迟就是两者之和:
$$\delta = \delta_{req} + \delta_{resp}$$NTP协议认为,往返时间差除以2就是一个NTP消息的延迟时间,这个时间加上服务器的应答时间$t_3$就是NTP客户端的时间,即NTP客户端在收到应答之后应该设置的时间$\theta$为:
$$\theta = t_3 + \frac{\delta}{2} = t_3 + \frac{\delta_{req} + \delta_{resp}}{2}$$仔细观察 NTP 的时间偏差计算公式 $\theta = t_3 + \frac{\delta}{2}$,我们会发现这个公式背后隐藏着一个巨大的假设:请求的延迟和响应的延迟是相等的,即 $\delta_{req} = \delta_{resp}$。NTP 协议假设网络是对称的,去程和回程走了相同的路径,花费了相同的时间。
然而,在实际的广域网(公网)环境中,这个假设往往是不成立的,这就是网络非对称性(Network Asymmetry):
- 路由路径不同: 互联网复杂的路由策略使得数据包从 A 到 B 的路径,往往不同于从 B 回到 A 的路径。去程可能走了光纤,回程可能绕了远路甚至走了拥堵的链路。
- 带宽与排队不同: 即使路径相同,上下行带宽的不一致(如常见的家用宽带 ADSL 或云服务器带宽限制)也会导致请求和响应在路由器排队等待的时间截然不同。
这种非对称性给 NTP 带来了无法消除的系统性误差。如果请求用了 100ms,而响应只用了 10ms,NTP 却粗暴地认为单程都是 55ms,这就直接导致计算出的时间 $\theta$ 产生了 45ms 的偏差。
此外,NTP 的 Stratum 层级结构进一步放大了这种不确定性。处于 Stratum 3 的服务器需要从 Stratum 2 同步,而 Stratum 2 又是从 Stratum 1 同步的。每一层级的同步都伴随着网络非对称性的风险,这种误差会随着层级逐级累积。这就好比传话游戏,传的人越多,最后听到的"时间"失真就越严重。
正是由于这些物理网络中不可避免的物理特性,使得我们在分布式系统中,永远无法获得一个真正精准的全局物理时钟。
除了误差以外,我们还要看到:做为NTP客户端的计算机,它们的时间会被NTP协议的时间调整。例如,在某一个时间,系统的时钟与NTP时间同步,但是在另一个时间,由于网络延迟等原因导致前面估算的网络延迟不一样,导致了系统突然向前或者向后调整时间。这个NTP客户端的时间会被突然往前或者往后调整的现象,也可能导致线上的问题。Cloudflare在2017年1月报道过一起线上故障,故障的核心原因是某些关键逻辑依赖于时间差的计算结果,但是没有考虑时间会被往后调整(也就是不保证单调性)。
从以上分析可以看到,如果只对测量时间差感兴趣(例如测量请求响应的时间差),可以考虑采用单调时钟(monotonic clock)。单调时钟不需要全局同步,总是向前移动,表示从主机启动之后开始的时长,因此不会出现时间回拨的情况。相对应的,*墙上时间(wall clock)*则会和NTP服务器进行时间的同步,在时间校准后可能出现回拨的情况。
物理时钟的缺陷 #
至此,我们已经了解了计算机系统物理时间的几种不同的来源、两套不同的物理时钟系统,以及物理时间的同步机制,物理时间存在两个两个缺陷:时间偏差(Clock Skew)和时间漂移(Clock Drift),以至于不能在分布式系统中采用物理时间来判断分布式事件的先后顺序。
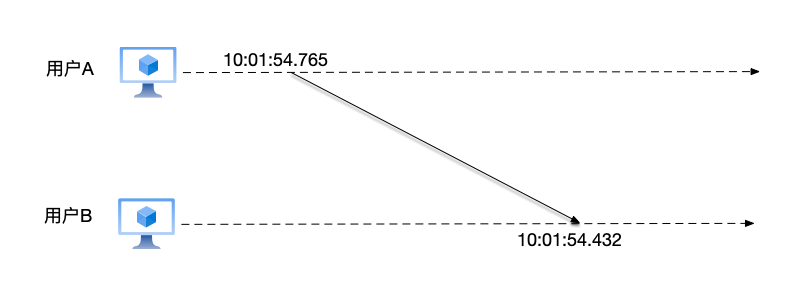
时间偏差指的是多个设备的时钟之间的时间差。例如,在分布式系统中,节点A的时钟显示12:00:00,而节点B显示12:00:01,这就是这两个节点之间的时间偏差。
由于时间偏差,所以在不同的物理设备上,不能通过对比各自的墙上时间来判断事件的顺序。如图,用户A在时间10:01:54.765发送的消息,在用户B的本地时间10:01:54.432收到,这样在用户B看来,就好像收到了来自"未来"的消息。
时间漂移指的是设备的本地时钟与标准时间之间的速度不同,随着时间推移,本地时钟的计时速度可能略快或略慢,导致与标准时间的差距越来越大。例如,某设备时钟每天可能快或慢几毫秒,长时间累积后,可能导致分钟级的偏差。为了校正设备的本地时钟,就需要与NTP服务器进行时间同步。但是在发生时间校正时,时间可能出现向前或者向后的漂移。
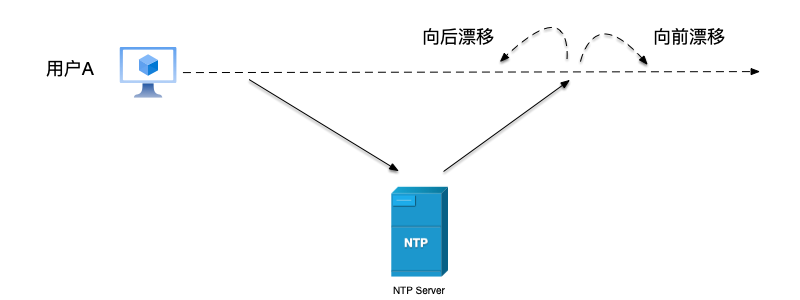
由于墙上时间可能在随机某个时刻发生向后漂移,因此如果不能使用墙上时钟在系统中测量两个事件之间的时间差,而应该使用单调时钟。
同时,由于不同的节点和NTP服务器同步校正时间时,可能由于各种原因(网络、延迟、节点本身的时钟频率等)导致不同节点的墙上时间不一致,因此在一个由多节点构成的分布式系统中,不存在一个全局唯一的时钟,不能像单机系统那样,采用物理时间来衡量事件的先后顺序。
那么,如何解决分布式系统中的事件先后顺序问题,我们需要重新审视分布式系统中事件之间的关系。
备注:值得注意的是,尽管 NTP 和普通石英钟无法满足强一致性系统的要求,但近年来硬件辅助的时钟同步技术取得了突破性进展。最著名的例子是 Google Spanner 使用的 TrueTime API。它利用数据中心的 GPS 接收器和原子钟,将时钟误差压缩到了极小的毫秒级范围,并且最关键地——它能明确告知调用者这个误差的上下界。
这种"将物理时间的误差纳入因果推断"的设计,使得 Spanner 能够在不完全依赖逻辑时钟的情况下实现外部一致性。TrueTime 代表了分布式系统设计的另一种哲学:硬件与软件的协同设计。我们将在后续探讨分布式事务时,专门深入这一技术。但在那之前,我们需要先掌握更普适的基础工具:逻辑时钟。
因果关系和事件先后顺序 #
前面已经了解了物理时钟,现在回到分布式系统中,来看一个典型的问题,在这里消息m1由用户A发出,广播给用户B和用户C,内容为"我们今天去哪儿玩?";消息m2是用户B在收到消息m1之后的回复,这条消息将广播给用户A和用户C,内容为"去看电影吧"。
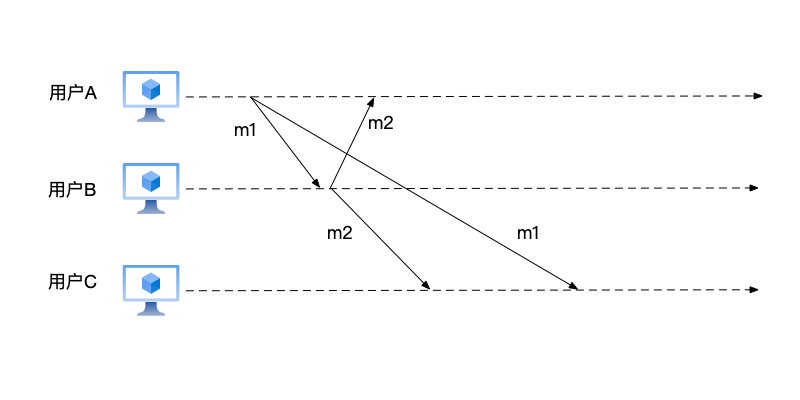
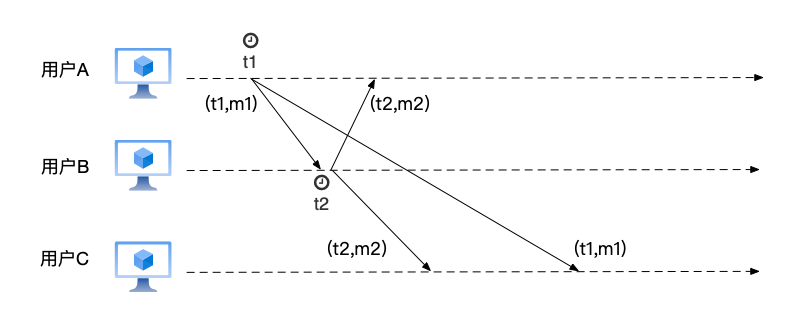
从m1和m2的关系来看,两者属于因果关系:即先有用户A的提问(消息m1),才有了用户B的应答(消息m2)。可是,用户C却首先看到了消息m2,再看到消息m1,这个顺序违反了因果关系:因为先看到了应答,才看到回复。
把上面换成一个更为技术的例子,假如消息m1是一个创建新对象的指令,消息m2是更新这个对象值的指令,显然消息m1也应该先于消息m2发生,因为先有创建新对象才能修改对象的值。如果这两个消息顺序在某个节点上相反,将导致先执行的更新操作失败,因为创建对象的消息还未到来,因此该对象此时在该节点上还不存在;而当收到创建对象的消息之后执行,却再也不会更新该对象的值,因为在前面已经处理过更新对象的指令了。
回到问题中来,我们考虑给每个消息加上一个时间,即原先的协议格式为"(消息体)",现在改为"(时间戳,消息体)",通过在协议中增加时间戳来解决这里的因果序问题。那么,应该如何选择这个时间戳?
首先我们排除单调时钟这个选项,因为单调时钟的值不能跨越不同的节点进行比较。
选用墙上时钟也不行。即使采用类似NTP这样的协议来同步不同节点的时间,特别是当不同节点与NTP服务器之间的网络延迟不对称的情况下,也不能保证多个节点的墙上时钟是一致的。如下图中所示,用户A在发出消息m1时的时间是t1,用户B在发出消息m2的时间是t2,这里并不能保证A上的时间t1就一定小于用户B上的时间t2,因此如果使用墙上时钟来对事件排序,仍然可能出错。
时间回到1975年,Paul Johnson和Bob Thomas发表了一篇论文,同样试图以时间戳来解决上面的问题。Leslie Lamport很快发现了论文中的问题,在Lamport的自述中谈到:
I realized that the essence of Johnson and Thomas’s algorithm was the use of timestamps to provide a total ordering of events that was consistent with the causal order.(我意识到Johnson和Thomas算法的本质,是使用时间戳来提供与因果顺序一致的事件总顺序。)
Lamport将这些洞见写成了论文《Time, Clocks, and the Ordering of Events in a Distributed System》,我们来看论文中如何解决事件的顺序问题。
在论文中,Lamport引入了Happen Before关系(中文翻译为"先于"),用于表达分布式系统中多节点事件的顺序,事件A先于事件B表示为$A \to B$,它的核心点是将一个分布式系统中的事件分为以下三类:本地事件、消息发送事件和消息接收事件,在这三类事件中定义了先后顺序。
以下是判断事件之间满足Happen Before关系的三个条件:
- 本地事件:事件A和事件B在同一个节点上先后发生,那么$A \to B$。
- 发送消息事件:如果事件A是发生在一个节点上的发送消息的事件,而事件B是接收节点上接收该消息的事件,那么$A \to B$。这是因为满足因果关系的事件一定有先后顺序,先有因(消息发送事件)才有果(接收消息事件)。
- 满足传递性:对于三个事件A、B、C,如果同时满足$A \to B$和$B \to C$,也有$A \to C$。
如果两个事件A和B,既不满足$A \to B$也不满足$B \to A$,就称这两个事件是并发事件(concurrent event),记作$A \vert\vert B$。用数学语言表达并发事件就是:
$$a \vert \vert b \iff \neg (a \to b) \ and \ \neg (b \to a)$$从上面Happen Before的三个条件可以看出,两个并发事件一定位于不同的节点上,同时相互之间是不存在消息传递的,因为没有消息传递,所以无法确认其顺序关系。
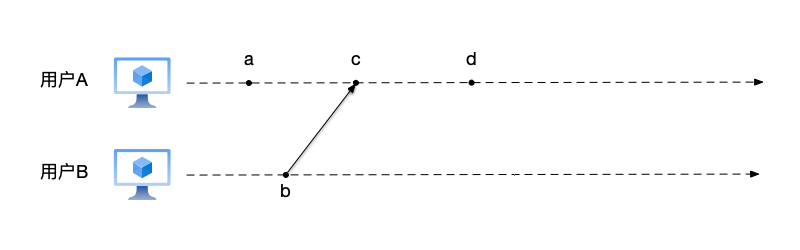
以图为例来讲解事件的顺序,在图中事件b和事件c之间的连线和箭头,指的是两者是同一个消息的发送和接收事件:
- 根据规则1,事件a、c、d在节点A上顺序发生,因此有$a \to c$,$c \to d$;
- 根据规则2,事件b是节点B上发送消息给节点A的事件,而事件c是节点A上对应的接收消息事件,因此有$b \to c$;
- 根据规则3,$a \to d$,$b \to d$;
- 对于事件a和b而言,既不满足$a \to b$也不满足$b \to a$,因此两者是并发事件。
下面把上面的图例再做一个扩展,引入几个称为"观察者"的节点,这些观察者节点能够看到节点A和节点B上的事件,同时将这些事件在同一个观察者节点的时间线上进行排序,相当于把多个节点的事件时间线"合并"到观察者节点的时间线上。
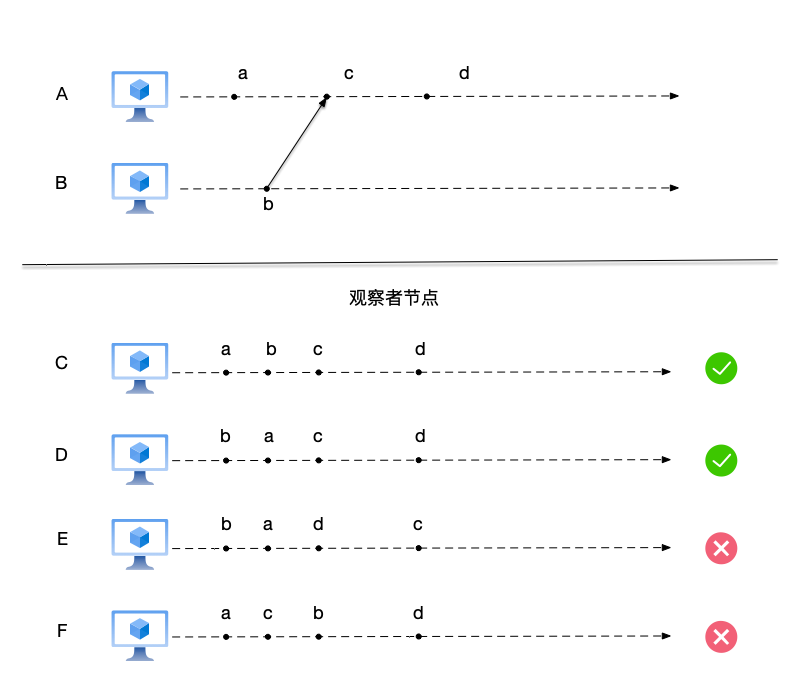
在图中:
- 节点C观察到的事件顺序为(a,b,c,d),这个排列没有违反Happen Before关系。
- 节点D观察到的事件顺序为(b,a,c,d),这个排列没有违反Happen Before关系。
- 节点E观察到的事件顺序为(b,a,d,c),在这里事件d排在事件c之前,我们在前面已经提到了这两个事件满足$c \to d$,所以这个排列是不对的。
- 节点F观察到的事件顺序为(a,c,b,d),在这里事件c排在事件b之前,我们在前面已经提到了这两个事件满足$b \to c$,所以这个排列是不对的。
这里值得说明的是:节点C和节点D的区别,就是事件a和b的顺序如何排列。前面已经提到过,这两个事件是并发事件,在某些一致性模型中,两个不同的节点对于并发事件可以任意排列,这并不会导致数据的错乱,我们将在后面讲到一致性模型时,重新回到这个问题的讨论。
备注:可以使用社交媒体类的产品来理解上面的"合并"操作。观察者节点和产生事件的节点,相当于社交媒体上的账号,每个观察者账号关注了多个账号(上例中的节点A和节点B),这些账号在各自的时间线发出不同的消息,但是在它们的关注者看来,这些消息最终要汇总在自己的时间线上有一个合理的排序。
对于并发的事件而言,在同一个账号上看到的顺序可以任意排列,但是对于满足Happen Before关系的事件,就必须保证其先后顺序。
全序和偏序 #
在上一节中,引入了事件的Happen Before关系,还存在某些不满足这个关系的并发事件,为了更深入理解这类关系,我们需要了解两个数学概念:偏序(Partial Order) 和全序(Total Order)。
很多工程师看到数学定义往往会心生畏惧,但实际上,这两个概念在我们的日常生活中随处可见。在进入严格的数学描述之前,我们先用两个生活场景来建立直观的理解。
全序:银行柜台前的队伍
想象你在银行柜台前排队办理业务。队伍里的人是一个接一个的。对于队伍中的任意两个人(比如张三和李四),我们一定能断定出他们的先后关系:
- 要么张三排在李四前面;
- 要么李四排在张三前面。
这种**“任意两个元素都能比较出先后”**的关系,就是全序。在单机系统中,因为只有一个 CPU 时钟,所有事件就像排队一样,一定能分出绝对的先后,因此单机事件通常满足全序关系。
偏序:公司的汇报关系
现在,我们把场景切换到一个大型公司的组织架构图上。我们要定义一种关系叫"汇报给"(即下级汇报给上级)。
- 纵向比较(可比): 程序员小王汇报给技术经理,技术经理汇报给 CTO。在这个链条上,我们可以明确地说:小王在职级序列上"后于"CTO。这种关系是清晰的。
- 横向比较(不可比): 现在通过这种"汇报关系"来比较技术经理和财务经理。你会发现无法比较——技术经理不汇报给财务经理,财务经理也不汇报给技术经理。他们在各自的部门里并行工作,互不隶属。
在这种系统中,只有"部分"成员之间存在明确的层级关系,而其他成员(如不同部门的同级经理)之间无法通过该关系进行比较。这种**“仅在部分成员间存在顺序,且允许存在无法比较的并发成员”**的关系,就是偏序。
映射到分布式系统:
- 汇报关系 $\Longleftrightarrow$ Happen Before(先于)。
- 互不隶属的跨部门经理 $\Longleftrightarrow$ 并发事件(Concurrent Events)。
理解了这一点,我们再来看数学家是如何用严谨的语言来描述这两类关系的。
偏序
偏序表示一种二元关系R,集合里只有部分成员能使用这种二元关系进行比较。在这里用于比较集合成员关系的二元关系R,在数学上要满足以下三个规则:
- 自反性(Reflexivity):对于集合中的任意成员$x$,都有$xRx$;
- 反对称性(Anti symmetry):对于集合中的任意成员$x$和$y$,如果满足$xRy$和$yRx$,则有$x=y$;
- 传递性(Transitivity):对于集合中的任意成员$x$、$y$和$z$,如果满足$xRy$和$yRz$,则有$xRz$。
我们举一个例子来理解偏序,对于集合$\{a, b, c\}$,它的所有子集组成的集合是$\{\{\},\{a\}, \{b\}, \{c\}, \{a, b\}, \{a, c\}, \{b, c\}, \{a, b, c\}\}$。所有这些成员都是原集合的子集,可以通过$\subseteq$关系相关联:
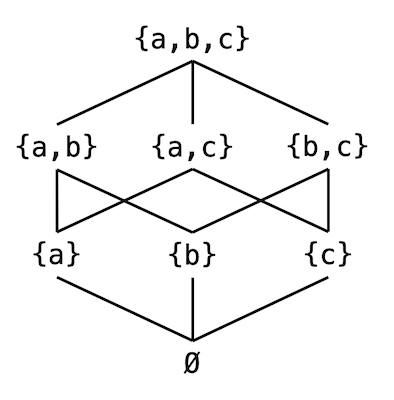
我们注意到,在这里$\subseteq$关系满足上面的三个规则。但并不是这里的所有成员都满足$\subseteq$关系,例如$\{a, b\} \nsubseteq \{b,c\}$且$\{b,c\} \nsubseteq \{a,b\}$。
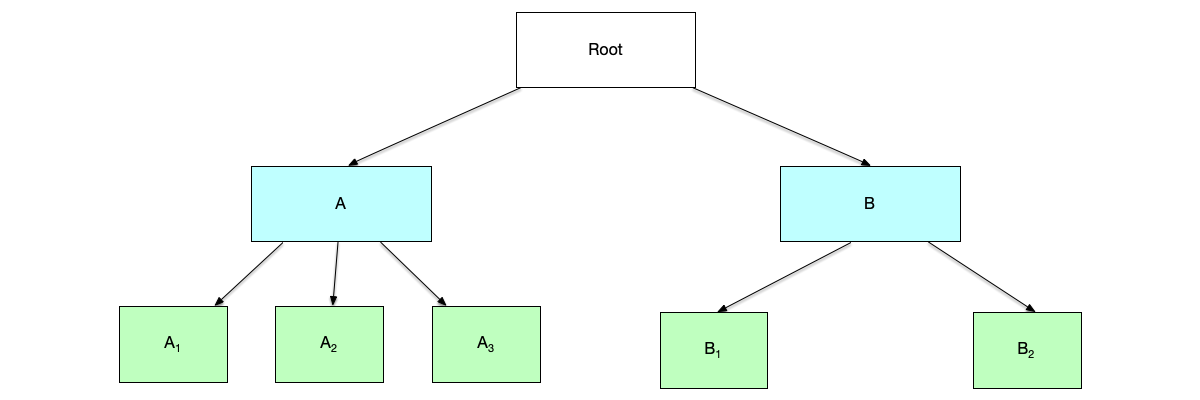
树形关系也是一种常见的偏序关系。如图所示的树中,位于同一层的节点之间,不能比较大小,因为就"层次"这个关系而言,同一层的节点是一样的,例如节点A和节点B的层次一样。
全序
另一方面,如果一个集合里的所有成员都能使用一种二元关系进行比较,这种二元关系就称为全序关系。形式化地说,全序关系在偏序关系的基础上,增加了一个完全性约束,即全序关系$R$要求满足以下四个规则:
- 自反性(Reflexivity):对于集合中的任意成员$x$,都有$xRx$;
- 反对称性(Anti symmetry):对于集合中的任意成员$x$和$y$,如果满足$xRy$和$yRx$,则有$x=y$;
- 传递性(Transitivity):对于集合中的任意成员$x$、$y$和$z$,如果满足$xRy$和$yRz$,则有$xRz$。
- 完全性(Total):对于集合中的任意成员$x$和$y$,有$x \leq y$或者$y \leq x$成立。
例如整数集合中的任意两个元素,都能使用二元关系$\leq$来进行比较,这个关系对于这个集合就是一种全序关系。
可以看到偏序和全序的区别是:偏序关系要求集合中的元素是部分有序的,而全序关系则要求集合中的元素是完全有序的。
从以上对全序和偏序关系的解释可以看到,Happen Before关系是一种偏序关系,那些并发的事件,就是无法对比其先后关系的事件。
备注:然而,Happen Before关系并不满足自反性,因为对于一个事件A而言,不能说"A Happen Before A"。所以从严格意义上说,Happen Before关系被称为*“非自反的偏序关系”(irreflexive partial order)*。简单起见,我们后面还是认为Happen Before关系就是一种偏序关系,不再特别强调违反自反性了。
在一个单机系统上,由于存在唯一的全局时钟,系统上的事件按时间顺序依次发生,一个事件结束了才发生下一个事件,所以单机系统上对事件进行全序排序是容易的。但是在一个分布式系统上,对事件进行全序排序就很困难了,理由有两点:
- 多节点上的事件并发进行;
- 分布式系统上没有全局时钟,而是每个节点有自己的时钟。
以图为例,我们将事件使用开始和结束时间来表示为"[开始时间,结束时间]"。可以看到,在单机系统中,事件依次执行,事件之间满足全序关系;在分布式系统里,多个节点的事件并发执行,例如节点A上的事件[1,3]和节点B上的事件[2,4],并不满足全序关系。
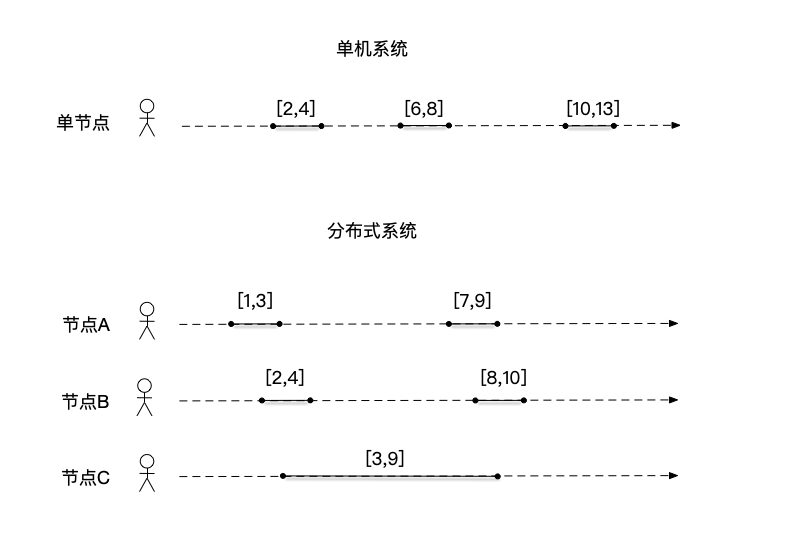
上面的图例中还暗含了一个假设:存在一个对于分布式系统而言的全局时钟,系统中的所有节点,可以基于这个全局时钟,在记录事件的开始和结束时间。在现实中,维护这个每个节点物理时钟的工作,一般交由类似NTP这样的服务来提供。但是考虑到各节点与NTP服务之间的网络延迟,以及节点的运行情况等,导致这个全局时钟与各节点之间的时间同步有不同的误差。所以在一个分布式系统上,并不存在全局时钟,而是各节点上有各自的时钟,这是导致在分布式系统上难以进行全局排序的第二个原因。
日常生活中,我们已经习惯了发生在自己周边的事件都是全序排列的。例如:
- 排队购买电影票,或者排队通过红绿灯;
- 购物时,首先将物品放入购物车,再进行购物结算。
但是,在涉及到多人交互的时候,存在大量难以对事件进行全序排序的场景,例如:
- 在一个群聊里,有多个用户在发言,这些发言之间的顺序,在不同的账号里看到可能是不一样的;
- 去社交媒体下对同一条发言的多条评论,可能也不是只有一个排序。
人们之所以习惯了自己周围的事件都是有序排列的,更多的原因是只有个体的单一视角,但是在分布式视角下,并不是所有发生在不同节点的事件都是有序排列的。
我们后面将在一致性模型章节里看到,在很多场景下没有必要实现一个全序关系,要保持事件之间的全序关系,要付出极大的代价:更多的资源消耗、更少的事件并发等等。相反,在很多时候,实现*因果一致性(causal consistency)*就够了,即只对于有因果关系的事件保持其顺序,其它多节点之间的并发事件可以任意排序。我们将在一致性模型里继续深入探讨这个问题。
因果性与Happen Before的关系 #
现实生活中的因果关系,是基于松散同步的时钟(手表、挂钟),在存在全球时钟的错觉下确定的,例如:
- 做时间计划:计划在六点十分到车站,赶上六点三十分的班车;
- 不在犯罪现场证明:一个嫌疑人在六点出现在某地的视频里,那么他就不可能在六点十分在距离此地十公里以外的地方作案。
在这类生活场景里,对时间的精度要求相对粗糙,能容忍几秒甚至几十秒的误差。这是因为在现实生活中,信息的流动很慢,因此时钟微小的误差,不会带来严重的问题。但是在一个分布式系统里,事件发生的频率和速度要更高,同时事件的持续时间对比现实生活里的事件要短好多数量级,如果分布式系统中的物理时钟没有精确同步,那么就难以判断事件之间的因果关系。
我们回顾一下满足Happen Before关系的三种情况,其中的第二种情况暗含了因果性:发送消息事件是因,接收消息事件是果。Happen Before是对分布式系统中因果关系进行推理的一种方式,在Happen Before的第二种情况中,考虑了信息是否从一个事件流向另一个事件,这表示一个事件是否可能影响另一个事件。所以Happen Before关系可以很方便的来表达事件之间的因果性:如果一个事件A导致了另一个事件B,那么一定有事件A Happen Before 事件B。
但是Happen Before的另外两种情况,就不一定有因果性了。情况一是说,同一个节点内的事件,先后发生时有Happen Before关系;情况三是说,Happen Before关系具有传递性。这两种情况中,满足Happen Before关系的事件之间,都不一定有因果性。因此我们说,如果事件A Happen Before 事件B,那么事件A可能导致了事件B(if event A Happen Before event B, then A might cause B)。
最后,对于并发事件,则一定不存在因果关系。如图中的事件a和事件b。
总结下来,因果性和Happen Before关系有以下三个关系:
- 如果一个事件A导致了另一个事件B,那么一定有事件A Happen Before 事件B(if event A causes event B, then $A \to B$);
- 事件A Happen Before 事件B,那么事件A可能导致了事件B(if $A \to B$, then A might causes B);
- 两个并发事件之间,一定不存在因果关系(if $A \vert \vert B$, then event A MUST NOT causes event B, and event B MUST NOT causes event A)。
备注:请大家注意上面的表述中,哪些使用了可能,哪些使用了一定。
逻辑时钟 #
既然在分布式系统中,物理时间不能做为衡量事件先后顺序的依据,Lamport接着在论文中引入了*“逻辑时钟(logical clock)"*的概念来解决该问题。
所谓逻辑时钟,可以理解为一个计数器,每个事件对应单独的计数。这个计数有多种实现方式,但是无论哪一种,都要求满足以下的时钟条件(Clock Condition)(以下设事件的逻辑时钟函数为C(e),其中参数e为事件):
如果事件a发生先于事件b,那么有C(a) < C(b)。
在前面讲解Happen Before的时候,我们用符号$a \to b$表示事件a先于事件b,因此时钟条件可以用数学语言表达式表述如下:
$$a \to b \Rightarrow C(a) < C(b)$$注意,在逻辑时钟里,时钟条件的反向并不成立,即:
如果C(a) < C(b),并不确定事件a发生先于事件b。
用数学语言表示为:
$$C(a) < C(b) \nRightarrow a \to b$$注意,“并不确定事件a发生先于事件b"的意思是:可能事件a发生先于事件b,也可能两个事件是并发事件。即:$C(a) < C(b) \Rightarrow (a \to b) \ or \ (a \ \vert \vert \ b)$
如果能同时满足以上两个条件,即$a \to b \iff C(a) < C(b)$,称为*“强一致条件(strong consistency condition)"*。
备注:在强一致条件里的"一致”,和我们后面会提到的"一致性模型"中的一致并不一样。强一致条件说的是,在逻辑时间和事件先后顺序之间,有一致的关系:根据对比逻辑时间,可以推导出事件之间的先后关系;反之如果知道事件之间的先后关系,也能得出两者逻辑时间的大小关系。
虽然有多种不同的逻辑时钟实现,但是总的来说,逻辑时钟的实现有两个主要的部分:
- 用于表示逻辑时钟的数据结构;
- 用于在节点间有消息传递时,更新表示逻辑时钟的协议。
每个节点维护以下的数据:
- 节点内的逻辑时钟,用于节点测量本节点内的事件顺序;
- 节点视角下的全局逻辑时钟。
协议包括以下两条规则:
- 规则1:描述节点执行一个事件时,如何更新本地的逻辑时钟;
- 规则2:描述节点如何更新本节点视角下的逻辑时钟。
不同的逻辑时钟实现,使用不同的数据结构来表示逻辑时钟,有不同的更新本节点和全局逻辑时钟的逻辑,但是总体上来说,都包含以上的核心点。
了解了逻辑时钟的概念后,我们来看两种逻辑时钟的实现:Lamport时钟和向量时钟。其中,Lamport时钟只满足基本的时钟条件,而向量时钟则满足强一致条件。
Lamport时钟 #
在Lamport时钟里,每个节点维护一个从0开始的计数器,同时按照以下规则来更新计数器的值:
- 规则1:执行一个本地事件(事件包括接收、发送消息,或者本地事件)之前,将计数器递增1:$C_i = C_i + 1$,该事件对应的逻辑时钟就是这个更新之后的计数;
- 规则2:发送消息时,按照以下顺序执行操作:
- 根据规则1,递增计数器,即$C_i = C_i + 1$;
- 在消息体里带上本节点当前的逻辑时钟;
- 规则3:接收消息时,按照以下顺序执行操作:
- 使用消息中的逻辑时钟来更新本地的逻辑时钟,规则为:$C_i = max(C_i,C_{msg})$;
- 根据规则1,递增计数器,即$C_i = C_i + 1$。
我们通过一个例子来理解计算Lamport时钟的流程。在下面图例中,使用"LC"表示Lamport时钟(LC是Lamport Clock的简写),大写字母表示节点的名称,大写字母加数字表示该节点上的第几个事件。例如,LC(A) = 1表示目前节点A的Lamport时钟是1,LC(A1) = 2表示节点A上的第一个事件的Lamport时钟是2。
-
初始情况 如图所示,此时节点A、B、C的Lamport时钟值都为0,即LC(A) = LC(B) = LC(C) = 0;

-
节点A向节点B发送消息 如图所示,
- 节点A:节点A执行发送消息事件之前,将计数器递增为LC(A) = LC(A) + 1 = 1,然后将当前计数值做为消息的一部分发送给节点B,因此该发送消息的事件LC(A1)对应的逻辑时钟是1;
- 节点B:收到节点A发来的消息,更新本节点计数器为LC(B) = max(LC(B), $C_{msg}$) = 1,然后将计数器递增为LC(B) = LC(B) + 1 = 2,因此该接收消息的事件LC(B1)对应的逻辑时钟是2;
- 节点C:节点C上发生一个本地事件,LC(C1) = 1。

-
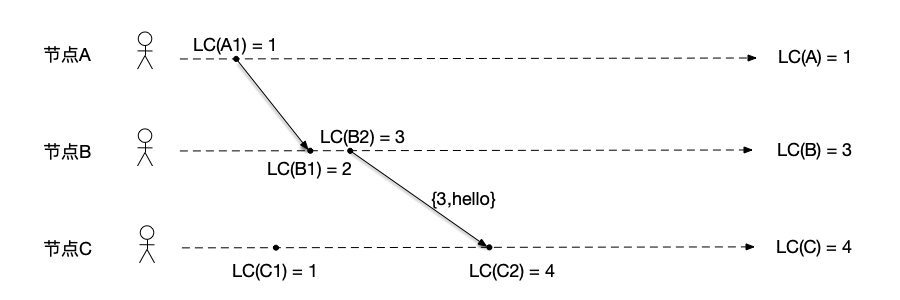
节点B向节点C发送消息 如图所示,
- 节点A:因为没有新的事件发生,节点A保持LC(A) = 1;
- 节点B:节点B执行发送消息事件之前,将计数器递增为LC(B) = LC(B) + 1 = 3,然后将当前计数值做为消息的一部分发送给节点C,因此该发送消息的事件LC(B2)对应的逻辑时钟是3;
- 节点C:收到节点B发来的消息,更新本节点计数器为LC(C) = max(LC(C), $C_{msg}$) = 3,然后将计数器递增为LC(C) = LC(C) + 1 = 4,因此该接收消息的事件LC(C2)对应的逻辑时钟是4。
-
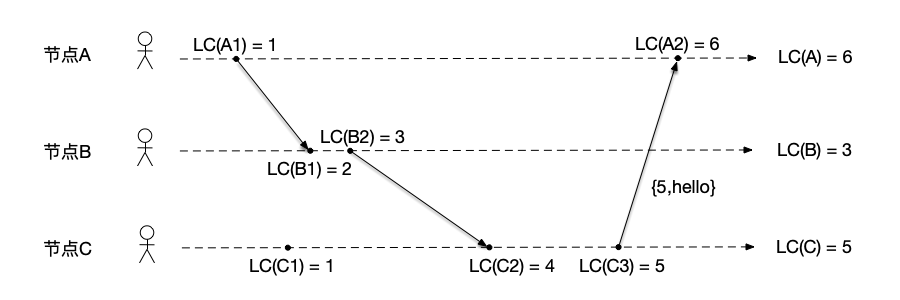
节点C向节点A发送消息 如图所示,
- 节点A:收到节点C发来的消息,更新本节点计数器为LC(A) = max(LC(A), $C_{msg}$) = 5,然后将计数器递增为LC(A) = LC(A) + 1 = 6,因此该接收消息的事件LC(A2)对应的逻辑时钟是6;
- 节点B:因为没有新的事件发生,节点B保持LC(B) = 3;
- 节点C:节点C执行发送消息事件之前,将计数器递增为LC(C) = LC(C) + 1 = 5,然后将当前计数值做为消息的一部分发送给节点A,因此该发送消息的事件LC(C3)对应的逻辑时钟是5。
容易看出,Lamport时钟的计算规则,满足前面提到的任何逻辑时钟实现都需要满足的时钟条件。它通过以下方式保证了时钟条件:
- 本地事件:节点每次执行一个事件之前,都将本地的Lamport时钟递增1,这样在节点内先后发生的事件,能通过Lamport时钟体现顺序,例如图中的事件B1和事件B2,LC(B1) = 2 < LC(B2) = 3;
- 消息收发事件:节点发送消息时,在消息体内带上该发送消息对应的Lamport时钟,接收消息时取当前本地的Lamport时钟及消息Lamport时钟的较大者,然后递增1为接收消息的事件时间。例如图中的事件B2和事件C1,为对应的消息发送和接收事件,LC(B2) = 3 < LC(C1) = 4。
反过来,两个事件的Lamport时钟大小,并不能反映出事件的顺序,例如图中的LC(C1) = 1 < LC(B2) = 3,但是这两个事件是并发事件。
可见,Lamport时钟虽然保持了逻辑时钟要求的时钟条件,但是却不能通过该时间来确定事件之间的因果关系,而下面介绍向量时钟能解决这一问题。
备注:尽管Lamport在这篇论文里提到的Lamport时钟,并不满足强一致条件,但是并不妨碍这篇论文成为分布式领域最重要的一篇论文之一。论文中除了提出Happen Before关系的定义、Lamport逻辑时钟的计算方法,更重要的是:它提出了任何一个分布式系统,都可以描述为一个使用特定顺序的事件构成的状态机。构成一个分布式系统的多个节点,如果按照同样的顺序执行同样的事件,就可以形成同样的状态机,而决定事件顺序的就是这里提到的逻辑时钟。这种思想也是后面提到的Paxos、Raft等共识算法的基础。
向量时钟 #
Lamport时钟的问题在于:使用单一整数来同时表示本地的逻辑时间和全局逻辑时间,这就导致了不足以用于跟踪事件的因果关系。如图中,LC(A1)和LC(C1)之所以都是1,是因为此时在节点A和节点C的视角下,看到的本地逻辑时间和全局逻辑时间都是1。
向量时钟在1988年由Friedemann Mattern提出,它的思想是:每个节点的有自己的本地逻辑时间,所有节点的逻辑时间合在一起形成一个向量,这个时间向量就是全局的逻辑时间。为了同步这个全局的逻辑时间,在节点中通信的时候,除了同步本节点的时间值,还同步本节点上保存的其它节点的时间值,这样就能维护一个全局唯一的全局逻辑时间。
向量时钟可以很方便得用于追踪事件的因果历史(causal history),仍然以图为例,事件C2的因果历史为:$\{A1,B1,B2,C1\}$,所有在这个集合里的事件都先于事件C2发生。除此以外,向量时钟还满足强一致条件,即如果有$VC_i[j] < VC_m[n]$,那么一定有$e_{i,j} \to e_{m,n}$;而两个事件如果是并发事件,说明不能对比两个事件的向量时钟大小,反之亦然。
下面来介绍向量时钟的具体实现。每个节点i维护一个时钟向量$VC_i$,该向量的长度是分布式系统中的节点数量,向量初始值为$[0,\cdots,0]$。$VC_i[j]$表示节点i上保存的节点j的逻辑时间,这里的$i$、$j$表示节点的序号。向量时钟的计算规则如下:
- 规则1:节点i上执行一个事件(事件包括接收、发送消息,或者本地事件)之前,将本节点的逻辑时间递增1,即:$VC_i[i] = VC_i[i] + 1$;
- 规则2:发送消息时,按照以下顺序执行操作:
- 根据规则1:递增向量时钟本节点的逻辑时间,即$VC_i[i] = VC_i[i] + 1$;
- 在消息体内带上本节点的向量时钟$VC_i$;
- 规则3:接收消息时,按照以下顺序执行操作:
- 根据消息里的向量时钟来更新本地的向量时钟,对于向量中的每个分量k,有$VC_i[k] = max(VC_i[k], VC_j[k])$;
- 根据规则1:递增向量时钟本节点的逻辑时间,即$VC_i[i] = VC_i[i] + 1$;
由于用向量来表达逻辑时钟,所以需要定义一下向量比较的规则。$VC_i < VC_j$当且仅当同时满足以下条件:
- 对于向量中的每个分量k,都有$VC_i[k] \leq VC_j[k]$;
- 至少有一个分量k,满足$VC_i[k] < VC_j[k]$。
例如,$VC_i = [0,1,2] < VC_j = [1,1,2]$,而向量$[1,2,3]$和向量$[1,3,2]$却无法比较大小。
做为对比,前面Lamport时钟的例子重新使用向量时钟来实现一遍。在下面图例中,使用"VC"表示向量时钟(VC是Vector Clock的简写),大写字母表示节点的名称,大写字母加数字表示该节点上的第几个事件,"[k]“表示取向量时钟的第k个分量的值。例如,VC(A) = [0,0,1]表示目前节点A的向量时钟是[1,0,0],LC(A1) = [2,0,0]表示节点A上的第一个事件的向量时钟是[2,0,0]。
-
初始情况 如图所示,此时节点A、B、C的Lamport时钟值都为0,即VC(A) = VC(B) = VC(C) = [0,0,0];

-
节点A向节点B发送消息 如图所示,
- 节点A:节点A执行发送消息事件之前,将本地向量时钟中,本节点对应的向量计数器递增,即$VC(A)[1] = VC(A)[1] + 1 = 1$,得到新的向量时钟$VC(A) = [1,0,0]$,然后将当前向量时钟做为消息的一部分发送给节点B,因此该发送消息的事件VC(A1)对应的向量时钟是[1,0,0];
- 节点B:收到节点A发来的消息,更新本节点计数器为VC(B)[1] = max(VC(B)[1], $VC_{msg}[1]$) = 1,然后将本地向量时钟的本节点计数递增为$VC(B)[1] = VC(B)[1] + 1 = 1$,因此该接收消息的事件VC(B1)对应的逻辑时钟是[1,1,0];
- 节点C:节点C上发生一个本地事件,VC(C1) = [0,0,1]。

-
节点B向节点C发送消息 如图所示,
- 节点A:因为没有新的事件发生,节点A保持VC(A) = [1,0,0];
- 节点B:节点B执行发送消息事件之前,将计数器递增为VC(B)[2] = VC(B)[2] + 1 = 2,然后将当前向量时钟做为消息的一部分发送给节点C,因此该发送消息的事件VC(B2)对应的向量时钟是[1,2,0];
- 节点C:收到节点B发来的消息,更新本节点计数器为VC(C)[1] = max(VC(C)[1], $VC_{msg}[1]$) = 1和VC(C)[2] = max(VC(C)[2], $VC_{msg}[2]$) = 2,然后将计数器递增为$VC(C)[3] = VC(C)[3] + 1 = 2$,因此该接收消息的事件VC(C2)对应的逻辑时钟是[1,2,2]。
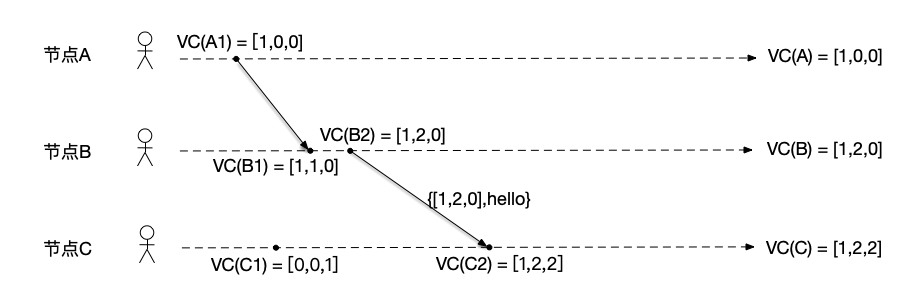
-
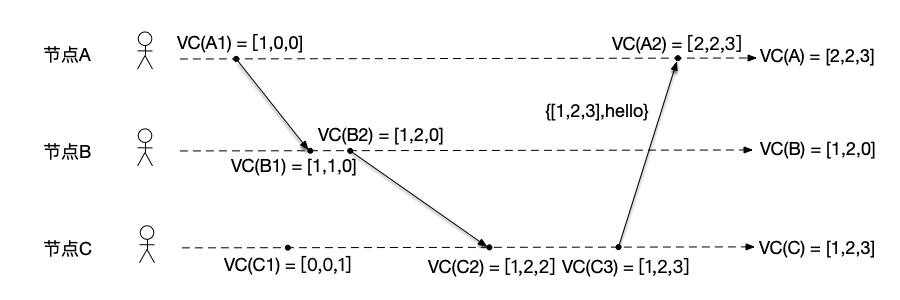
节点C向节点A发送消息 如图所示,
- 节点A:收到节点C发来的消息,更新本节点计数器为VC(A)[3] = max(VC(A)[2], $C_{msg}$[2]) = 3,然后将计数器递增为VC(A)[1] = VC(A)[1] + 1 = 2,因此该接收消息的事件VC(A2)对应的物理时钟是[2,2,3];
- 节点B:因为没有新的事件发生,节点B保持VC(B) = [1,2,0];
- 节点C:节点C执行发送消息事件之前,将计数器递增为VC(C)[3] = VC(C)[3] + 1 = 3,然后将当前计数值做为消息的一部分发送给节点A,因此该发送消息的事件VC(C3)对应的物理时钟是[1,2,3]。
我们前面提到过,事件C2的因果历史为:$\{A1,B1,B2,C1\}$,集合里的事件都先于事件C2发生,因为这些事件的向量时钟都大于事件C2的向量时钟。
另外,在前面图中,LC(C1) = 1 < LC(B2) = 2,但是我们并不能根据这个断言两者的因果关系,即当LC(a) < LC(b)的时候,既有可能事件a先于事件b发生,也可能两者是并发事件。即在Lamport时钟的算法里:$LC(a) < LC(b) \Rightarrow (a \to b) \ or \ (a \vert \vert b)$。
而在向量时钟示例图中,VC(C1) = [0,0,1],VC(B2) = [1,2,0],根据向量时钟的比较算法,两者不能比较大小,因此我们能断言两个事件是并发事件。
虽然向量时钟完美解决了 Lamport 时钟无法识别并发事件的问题,并满足了强一致条件,但天下没有免费的午餐。向量时钟的"完美"是建立在存储成本之上的。
我们注意到,向量时钟 $VC$ 的长度取决于系统中节点的数量 $N$。这意味着:
- 网络带宽消耗:每一次消息传递,都需要附带这个长度为 $N$ 的向量。如果是在一个拥有成百上千个节点的集群中,或者是在微服务架构下动辄数千个服务实例的场景里,这个向量的数据量可能会变得非常大,甚至超过消息体本身的大小,占用宝贵的网络带宽。
- 存储空间消耗:每个节点都需要在本地维护并存储这个日益增长的向量。
- 动态性支持差:向量时钟通常假设系统中的节点数量是固定的。如果系统频繁地进行动态扩容或缩容(节点上下线),维护一个固定长度的向量将变得极其困难且低效。
备注:我们将在后续章节中,看到向量时钟如何用来保证事件之间的因果顺序;在详解介绍亚马逊的Dynamo系统如何利用向量时钟来解决数据冲突问题。
分布式系统中的全局快照 #
做为逻辑时钟的一种应用,我们来看如何分布式系统中如何获取全局快照。
在分布式系统中,快照有以下的用途:
- 故障恢复与检查点:分布式系统中的计算任务通常涉及多个节点,任务可能非常耗时或依赖于不确定的输入(如网络请求)。如果系统发生故障,快照可以保存系统的全局状态,从而在故障恢复时从最近的检查点重新开始,避免从头计算,减少计算资源的浪费和数据丢失。
- 一致性检查与全局状态捕获:分布式系统的状态分散在多个节点上,快照可以帮助捕获系统的全局一致性状态。这对于调试、验证系统行为或检测数据一致性非常有用。例如,通过快照可以检查分布式事务是否满足一致性要求。
- 死锁检测:在分布式系统中,死锁可能涉及多个节点之间的相互等待。快照可以捕获系统中所有节点的状态,帮助检测是否存在死锁情况,从而为解决问题提供依据。
- 分布式调试与性能分析:快照可以记录分布式系统在某一时刻的状态,帮助开发者分析系统的运行情况,定位性能瓶颈或逻辑错误。
- 日志压缩与状态恢复:在分布式系统中,日志可能非常庞大。通过定期创建快照,可以将日志压缩到快照点,减少日志存储的开销,并在恢复时基于快照和后续日志快速重建系统状态。
- 分布式算法验证:某些分布式算法(如共识算法、分布式锁等)的正确性依赖于系统的全局状态。快照可以用于验证这些算法在执行过程中是否满足预期的性质。
- 容错与高可用性:快照是实现容错和高可用性的关键技术之一。通过定期保存系统状态,可以在节点故障或网络分区时快速恢复服务,减少停机时间。
在本章的开头,简单解释了状态、事件、快照这几个概念,在有了Happen Before关系的定义之后,可以给出快照需要满足的性质:
如果$A \to B$,且B是一个保存在生成快照中的事件,那么事件A也必须在快照B中。
这个性质要求:快照不能出现*遗失因果历史(missing causal history)*的情况,即一个事件如果出现在快照中,所有先于该事件的事件也都应该出现在快照中。
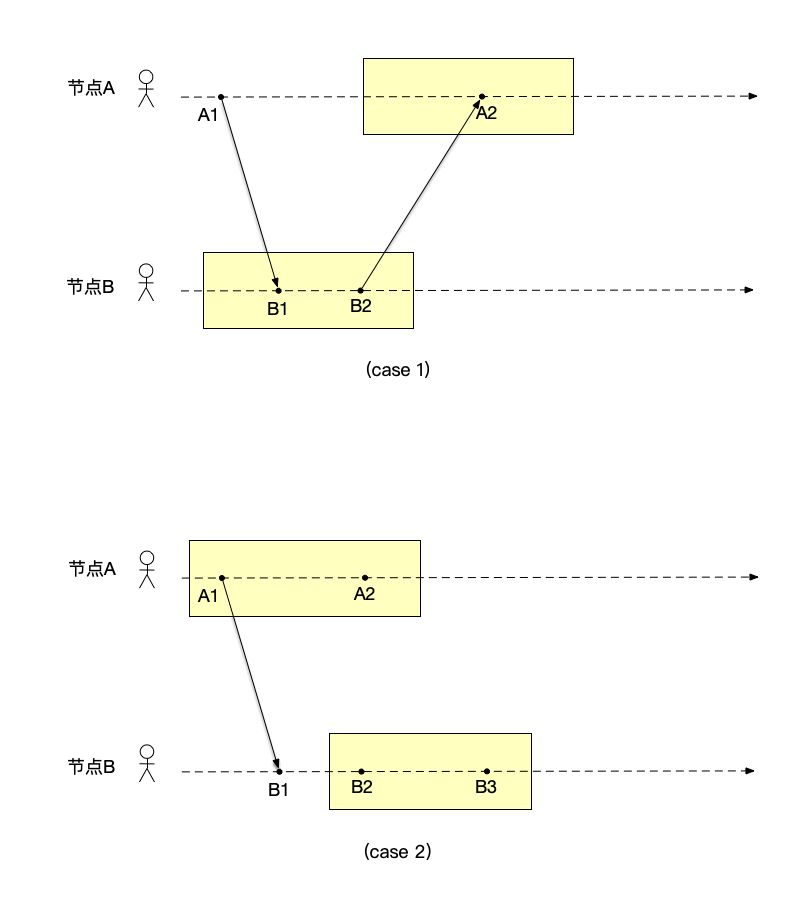
只有满足这一性质的快照,才能被称为一致的快照。例如图中的快照(快照由被矩形内的事件组成)就不是一致快照:
- 情况1:事件$A1 \to B1$,且节点B的快照有事件B1,但是事件A1却不在节点A的快照中;
- 情况2:事件$B1 \to B2$,且节点B的快照有事件B2,但是事件B1却不在节点B的快照中;
以上两种情况,都属于遗失因果历史问题,即:某个事件被记录到了快照中,但是先于该事件的一些其它事件没有被记录到快照中。
如果系统以单机状态运行,那么获取系统的全局快照是相对简单的:只需要取得特定时间上,该节点的所有变量和事件组合的状态生成快照即可。但是当系统以多节点的状态运行时,事情就变得复杂了:每个节点有自身的状态,同时节点之间的事件又会影响节点的状态。
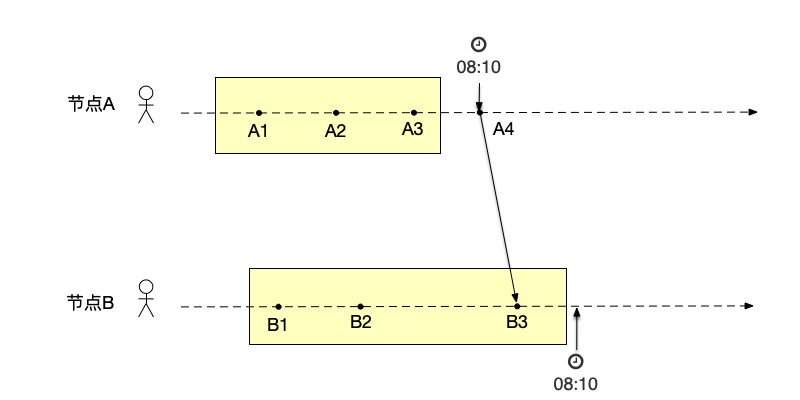
一个直观的方式是使用"全局时钟"来通知其它节点,节点收到消息后,以该时间之前的状态返回。正如前面介绍过的,节点间以物理时钟来进行同步是不可靠的。如图所示,节点A在8:10分记录自己当前的快照(包括事件$\{A1,A2,A3\}$),同时向节点B发送消息(发送消息的事件是A4),要求节点B记录自己的状态。由于时钟倾斜的原因,节点B在收到消息之后,时间才来到8:10,于是接收消息的事件B3也被记录到节点B的状态中,即节点B的快照由事件$\{B1,B2,B3\}$构成。请注意,节点A上的快照中并不包括导致事件B3发生的事件A4,所以这一快照并不是一致的,因为凭空出现了一个事件B3。根据前面提到的快照需要满足的性质,事件B3出现在快照里,先于该事件的所有事件都应该在快照里,而事件A4并不在节点A的快照中,违反了快照的性质。导致这一问题的原因,是以物理时间做为记录快照的依据。
Lamport和Chandy在论文《Distributed Snapshots: Determining Global States of Distributed Systems》提出了一种用于在分布式系统中记录全局状态的算法(该算法以两位作者的名字命名为Chandy–Lamport算法)。
在论文中,为了让读者更好理解该算法的思想,Lamport用给鸟群摄影来举例。当摄影师想给天空中的鸟群拍照时,由于鸟的数量众多,也不可能让鸟在拍摄的时候保持不动,因此摄影师的做法是拍摄多张照片,最后将这些照片拼接成一幅整体的场景图。在这里,鸟可以类比为分布式系统中的节点。
但是分布式系统与鸟群的区别在于,分布式系统中的节点会相互发送消息进行通信,这些消息可能会改变节点的状态。因此算法除了要记录节点自身的状态,还要记录该节点收到的消息,这样就能得到一个节点的局部快照。系统中所有节点的局部快照,合在一起就是系统的全局快照。此外,为了不干扰分布式系统中的节点的消息发送,算法中还定义了一个Marker消息,该消息不会改变节点的内部状态,用于通知节点记录局部快照的开始和结束。
在正式介绍算法步骤之前,我们需要先解决一个棘手的问题:如何记录那些正在飞行途中的消息?
想象我们在观看一场足球比赛的视频录像。如果在某一秒,我们按下了暂停键(快照),场上所有球员的位置就被定格了(节点状态)。但是,球场上可能还有一个足球正飞在空中(通道中的消息),它刚被球员 A 踢出,但还没被球员 B 接到。
如果我们只记录球员的位置,而不记录这个飞在空中的足球,那么当我们恢复比赛(从快照恢复)时,这个球就凭空消失了——球员 A 觉得我已经踢出去了,球员 B 还没收到,系统状态就丢失了数据。这显然是错误的。
因此,一个完美的全局快照,不仅要记录所有球员的站位(节点状态),还要把所有飞在空中的足球(通道消息)都给"抓"下来,放进快照里。
Chandy-Lamport 算法巧妙地利用 Marker(标记)消息来解决这个问题。这里的逻辑是这样的:
- 红线划分(一致性割集): 想象 Marker 是一条看不见的红色分割线。
- 红线前: Marker 之前发送的消息,属于"过去”,应该被包含在快照里。
- 红线后: Marker 之后发送的消息,属于"未来”,不应该出现在这次快照里。
当节点 A 记录完自己的状态并发出了 Marker 给节点 B,此时节点 A 已经进入了"快照后"的世界。但是,节点 B 还没有收到这个 Marker,它还活在"快照前"的世界里。
在这段时间差内(A 发出 Marker 后,B 收到 Marker 前),如果有任何消息从 A 飞向 B:
- 对 A 来说,这消息是在它记录状态之后发出的(属于未来);
- 但对 B 来说,它是在自己记录状态之前收到的吗?不,算法要求 B 收到 Marker 才能"定格”。
让我们换个角度看接收端。假设节点 B 此时已经记录了自己的状态(因为它可能先收到了来自 C 的 Marker 从而触发了快照),但它还没有收到来自 A 的 Marker。
此时,A 和 B 都在录制快照的过程中。如果 A 在发出 Marker 之前发了一条消息 m1 给 B,这条消息 m1 显然属于"过去"。
- 如果 m1 在 B 记录状态之前到达,B 会更新自己的状态(x=x+m1),这没问题。
- 关键点:如果 m1 飞得慢,在 B 已经记录完自己的本地状态(拍了照)之后才到达,但此时 B 还没有收到 A 的 Marker。这意味着 m1 是属于"红线前"的(A 在发 Marker 前发的),但它错过了 B 的"拍照时刻"。
为了不丢失这个"迟到"的 m1,算法要求:节点 B 在记录完自己的状态后,必须开启录像机,专门记录从 A 通道传来的所有消息,直到收到 A 的 Marker 为止。 这些消息,就是那些"明明属于过去,却因为网络延迟没赶上拍照"的补漏数据。
理解了录制通道消息是为了捕获那些迟到的、属于过去状态的在途消息,我们来看具体的算法流程。算法有如下的假设:
- 节点之间的消息不会丢失,最终会抵达接收端;
- 节点之间的消息管道是先入先出队列,即消息不会乱序;
- 节点上的消息管道分为两类,出边管道(outbound channel)和入边管道(inbound channel);
- 节点不会出现宕机现象。
有了以上的假设之后,接着来看算法的实现。
-
负责初始化快照的节点,有以下几个工作:
- 记录本节点当前的状态;
- 通过本节点上的出边管道向其它节点广播marker消息;
- 开始记录入边管道上收到的消息;
-
如果一个开始记录快照的节点收到的不是marker消息,需要记录这些消息,直到收到marker消息为止;
-
当一个节点(包括负责初始化快照的节点)收到marker消息之后,根据之前是否曾经收到过marker消息,有以下不同的处理:
- 如果之前没有收到marker消息:
- 节点开始记录本节点上的状态;
- 将收到marker消息的管道标记为空;
- 通过本节点上的出边管道(outbound channel)向其它节点广播marker消息。
- 如果之前收到了marker消息,停止记录来自收到marker消息管道的事件。
- 如果之前没有收到marker消息:
-
当所有节点的入边管道都收到了marker消息,代表所有节点都记录了自己的快照。所有节点上的局部快照,会构成一个全局快照。
以一个例子来说明Chandy–Lamport算法的运行流程:
-
初始情况 如图所示,系统中有两个节点A、B,状态分别是$\{x=1\}$、$\{y=2\}$;
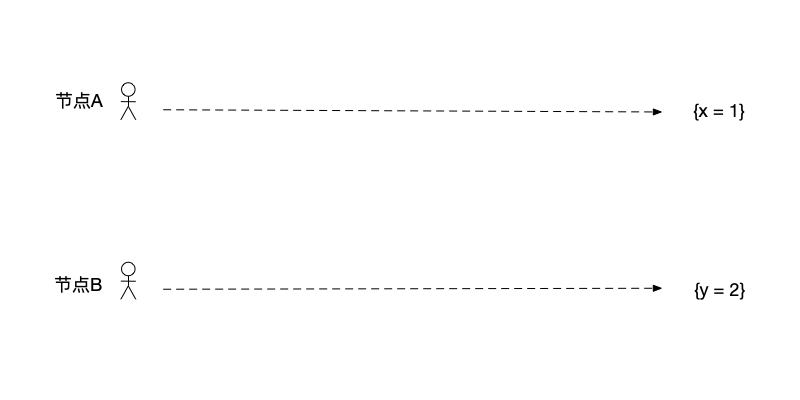
-
开始记录快照 如图所示,节点A记录当前本节点的快照为$\{x=1\}$,然后向节点B发出marker消息,通知它开始记录快照。在节点B收到marker消息以前,节点B还向节点A发送了一条修改数据的消息。
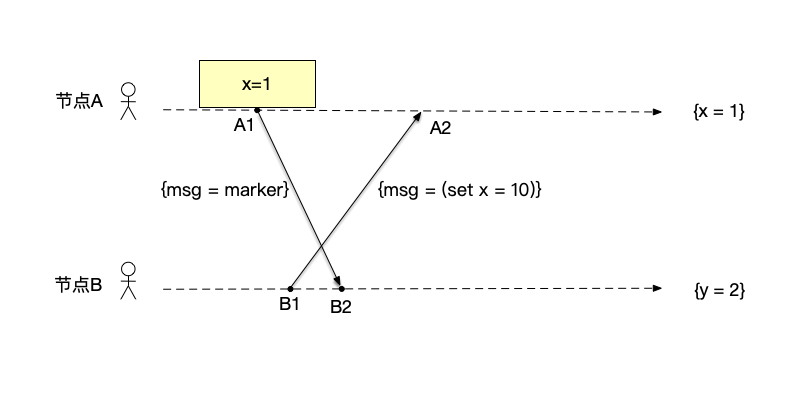
-
记录收到的非marker事件 如图所示,节点A收到节点B的修改数据消息,由于这条消息不是marker消息,所以节点A需要记录下来这条消息。节点B在收到节点A的marker消息之后,需要记录下当前的快照为$\{y=2\}$。
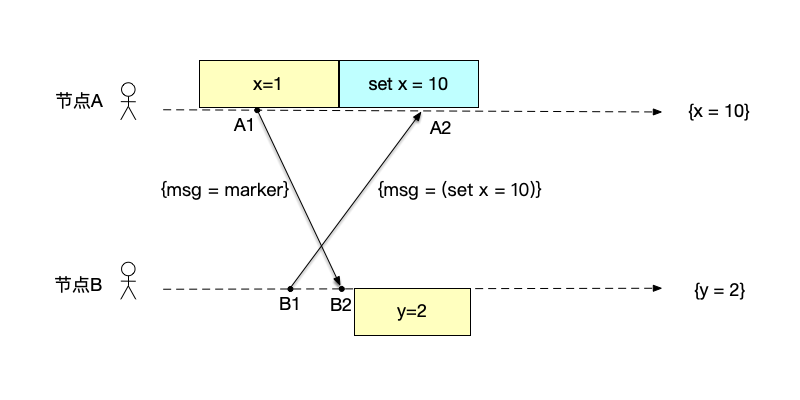
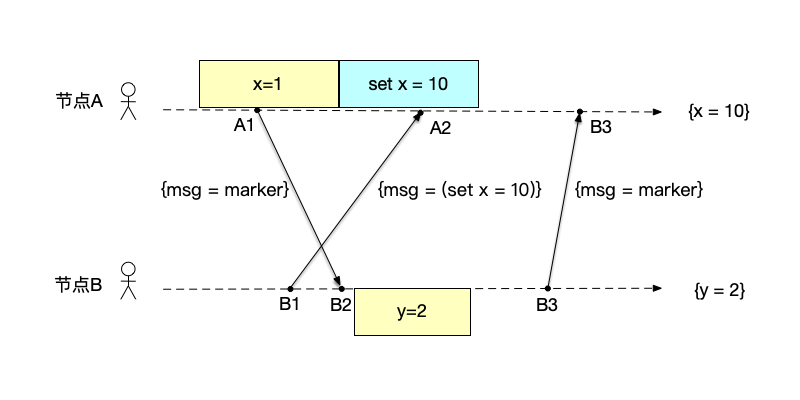
-
完成全局快照记录 如图所示,节点B记录快照之后,向节点A发送marker消息。节点A收到节点B的marker消息之后,知道节点B已经完成了局部快照。由于该系统上只有两个节点,此时生成全局快照。局部快照分别为:节点A上的快照$\{x=1\}$和事件$set \ x=10$,以及节点B上的快照$\{y=2\}$,这些局部快照合在一起构成的全局快照是$\{x=10,y=2\}$。
本章小结 #
本章我们从分布式系统中最基础、却又最令人困惑的概念——“时间"出发,探讨了如何在一个没有全局时钟的系统中确定事件的顺序。
我们首先认识到,顺序决定状态。如果将分布式系统视为一个状态机,那么只有保证各个副本按照相同的顺序执行相同的事件,才能最终达到一致的状态。然而,试图通过物理时钟(Physical Clock)来寻找这种顺序是不可靠的。无论是墙上时钟(Wall Clock)还是单调时钟(Monotonic Clock),受限于石英震荡的物理特性、NTP 协议的网络非对称性以及层级同步的累积误差,物理时间在跨节点通信时总是存在偏差(Skew)和漂移(Drift),无法作为衡量事件先后顺序的绝对标尺。
为了摆脱物理时间的束缚,我们引入了 Lamport 的 Happen Before 关系($\to$),这是理解分布式顺序的基石。它将事件之间的关系划分为具有因果性的"先后关系"和无法比较的"并发关系”。基于此,我们区分了全序(Total Order)和偏序(Partial Order)这两个重要的数学概念:单机系统通常满足全序,而分布式系统在引入并发后本质上是一个偏序系统。
在逻辑时钟(Logical Clock)的探索中,我们介绍了两种实现:
- Lamport 时钟:利用简单的计数器满足了基本的时钟条件($a \to b \Rightarrow C(a) < C(b)$),它为所有事件强加了一个全序关系,但却丢失了部分因果信息,无法反推事件关系。
- 向量时钟(Vector Clock):通过维护因果历史(Causal History),实现了强一致条件($a \to b \iff V(a) < V(b)$)。它能够精准地识别并发事件,但代价是随着节点数量增加而线性增长的存储和网络开销。
最后,作为逻辑时钟的重要应用,我们学习了 Chandy-Lamport 全局快照算法。该算法巧妙地利用 Marker 消息作为节点间的"分割线",在不停止系统运行(非阻塞)的情况下,捕捉到了一个满足因果一致性的全局状态(Global State)。这让我们明白,分布式系统的"快照"并非物理时间上的同一时刻,而是逻辑上的一致割集。
通过本章的学习,我们建立了一个核心观念:在分布式系统中,因果关系(Causality)比物理时间(Physical Time)更重要。
理解了"时间和顺序",我们就掌握了打开分布式系统大门的钥匙。在接下来的章节中,我们将看到这些理论如何转化为工程实践:从副本之间的数据复制,到解决并发冲突,再到实现共识算法(如 Paxos 和 Raft),它们无一不依赖于本章建立的这些关于"序"的基础理论。