第五章 数据复制 #
主从复制 #
集群中有一个主节点,写操作都必须经过主节点完成,读操作主从节点都可以处理。
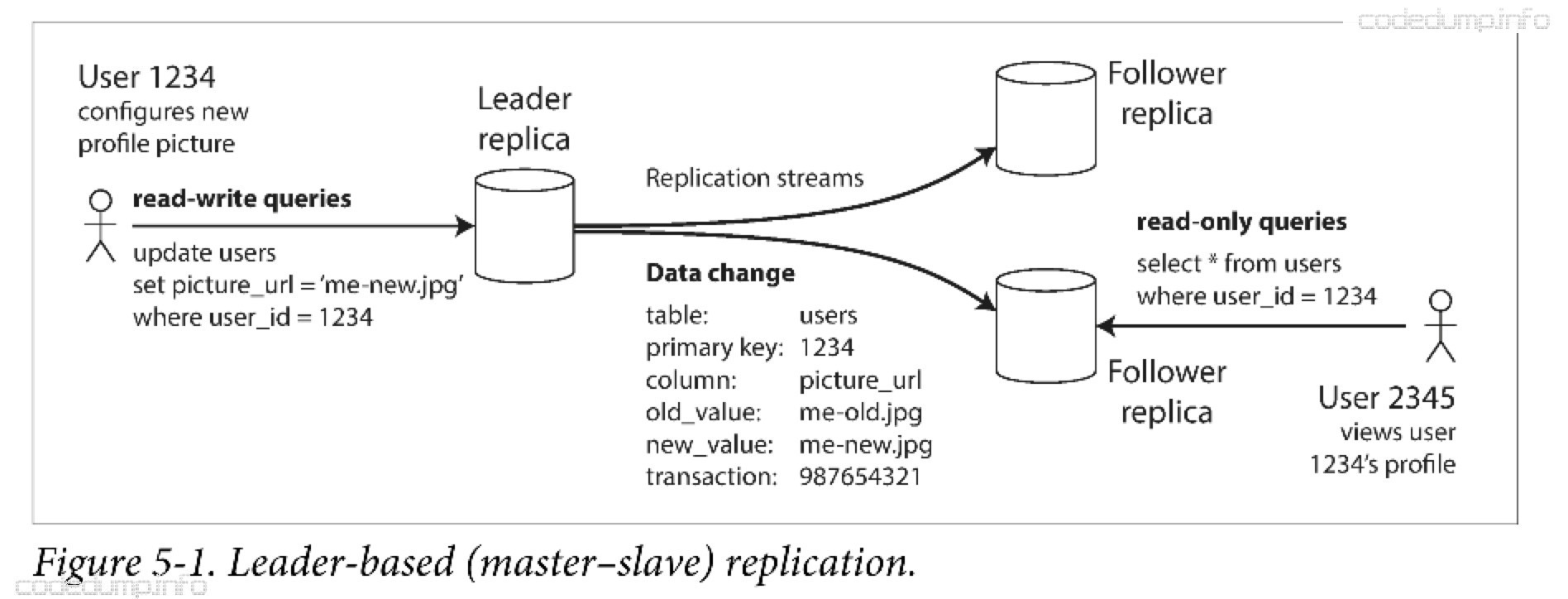
同步复制和异步复制 #
同步复制 #
数据在副本上落盘才返回。
- 优点:保证在副本上的数据是最新数据。
- 缺点:延迟高,响应慢。
异步复制 #
数据不保证在副本上落盘。
- 优点:延迟低
- 不能保证在副本上的数据最新。
新增新的从节点 #
- 主节点生成快照数据
- 主节点将快照数据发送到从节点。
- 从节点请求主节点快照数据之后的数据。
- 重复上面三步直到从节点追上主节点的进度。 不能把集群中所有节点设置为同步节点,因为这样的话任何一个节点的停滞都会导致整个集群的不可用。像Paxos、Raft算法,都要求集群中大多数节点返回就可以了。部分同步、部分异步的集群配置成为半同步(semi-sync)的集群配置。
处理节点失效 #
从节点失效 #
从节点崩溃恢复之后按照前面新增新的从节点的步骤来追上主节点的数据进度。
主节点失效 #
主节点失败时需要提升某个从节点为新的主节点,同时需要通知客户端新的主节点。
自动切换主节点的步骤通常如下:
- 确认主节点失效。大部分系统采用基于超时的机制,主从节点直接发送心跳消息,主节点在某个时间内都没有响应,则认为主节点已经失效。
- 选举新的主节点。通过选举的方式(超过半数以上的从节点达成共识)来选举新的主节点,新的主节点是与旧的主节点数据差异最小的一个,最小化数据丢失的风险。
- 重新配置使新的主节点上线。
除了以上步骤之外,还有以下问题需要考虑:
- 如果使用异步复制机制,而且在失效之前,新的主节点并没有收到旧的主节点的所有数据,那么在旧的主节点重新上线之后,未完成复制的数据将被丢弃。
- 可能会出现集群同时存在两个主节点的情况,也就是所谓的脑裂(split brain)现象,此时两个主节点都认为自己是主节点并且都能接收客户端的写数据请求,会导致数据丢失或者破坏。
- 如何设置合理的超时时间来判断主节点失效?如果太大意味着总体恢复时间长,如果太小意味着某些情况下可能主节点并未失效但是被误判为失效了,比如网络峰值导致延迟高等原因,这样会导致很多不必要的主节点切换。
上述的问题,包括节点失效、网络不可靠、副本一致性、持久性、可用性与延迟之间的各种细微的权衡,正是分布式系统核心的基本问题。
复制日志的实现 #
基于语句的复制 #
主节点记录所执行的每个写请求并将该语句做为日志发送给从节点。但是有些场景并不适合这么做,比如:
- 调用任何非确定函数的语句,比如NOW()获得当前时间,RAND()返回一个随机数。
- 语句中使用了自增列,或者依赖于当前数据库的数据。
- 有副作用的语句,在每个副本上面执行的效果不一样。
基于预写日志(WAL) #
将对数据库的操作写入日志,传送到从节点上然后执行,得到与主节点相同的数据副本。
基于行的逻辑日志复制 #
所谓的逻辑日志,就是复制与存储引擎采用不同的日志格式,这样复制与存储逻辑剥离,这种日志称为逻辑日志,与物理存储引擎的数据区分开。由于逻辑日志与存储引擎逻辑上解耦,因此可以更好的向后兼容,也更好的能被外部程序解析。
对于关系型数据库,其逻辑日志是一系列用来描述数据表行级别的写请求:
- 插入行:日志包括所有相关列的新值。
- 删除行:日志中保证要有足够的信息来唯一标识待删除的行,通常是主键。
- 更新行:日志中保证要有足够的信息来唯一标识待更新的行,同时也有所有列的新值。
复制滞后(replication lag)问题 #
如果一个应用正好从一个异步复制的从节点上读取数据,则可能读取不到最新的数据,这是因为主从节点的数据不一致导致的。理论上不一致状态在时间上并没有上限。以下描述几个复制滞后导致的问题。
读自己的写(reading your own writes) #
用户在写入数据不久就马上查看数据,而新数据并未到达从节点,这样在用户看来可能读到了旧的数据。这样情况需要“写后读一致性(read-after-write consistency)”,该机制保证每次用户读到的都是自己最近的更新数据,但是对其他用户则没有任何保证。
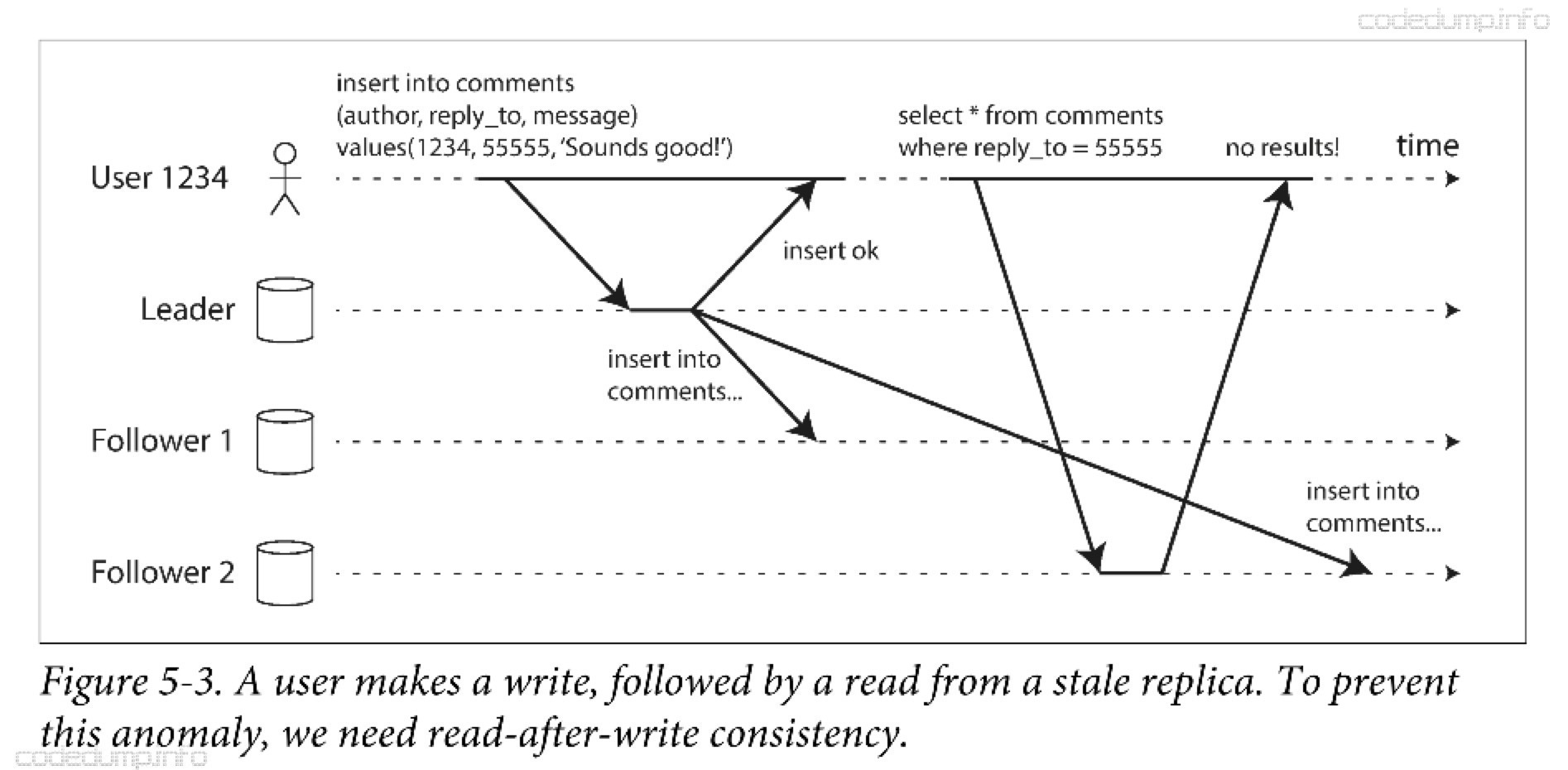
在上图中,用户1234首先向主节点写入数据,SQL执行成功之后返回,而此时用户再次向从节点2发起读刚才写入数据的请求,但是却读到了旧的数据。
有以下方案实现写后读一致性。
- 如果用户访问可能会被修改的内容,从主节点读取。比如社交网络的本用户首页信息只会被本人修改,访问用户自己的首页信息通过主节点,而访问其他用户的首页信息则走的从节点。
- 如果应用大部分内容都可能被所有用户修改,则上述方法不太适用。此时需要其他机制来判断哪些请求需要走主节点,比如更新后一分钟之内的请求都走的主节点。
- 客户端可以记住自己最近更新数据的时间戳,在请求数据时带上时间戳,如果副本上没有至少包含该时间戳的数据则转发给其他副本处理,直到能处理为止。但是在这里,“时间戳”可以是逻辑时钟(比如用来指示写入数据的日志序列号)或者实际系统时钟(而使用系统时间又将时间同步变成了一个关键点)。
- 如果副本分布在多数据中心,必须将请求路由到主节点所在的数据中心。
单调读(monotonic reads) #
单调读一致性保证不会发生多次读同一条数据出现回滚(moving backward)的现象。这个是比强一致性弱,但是比最终一致性强的保证。
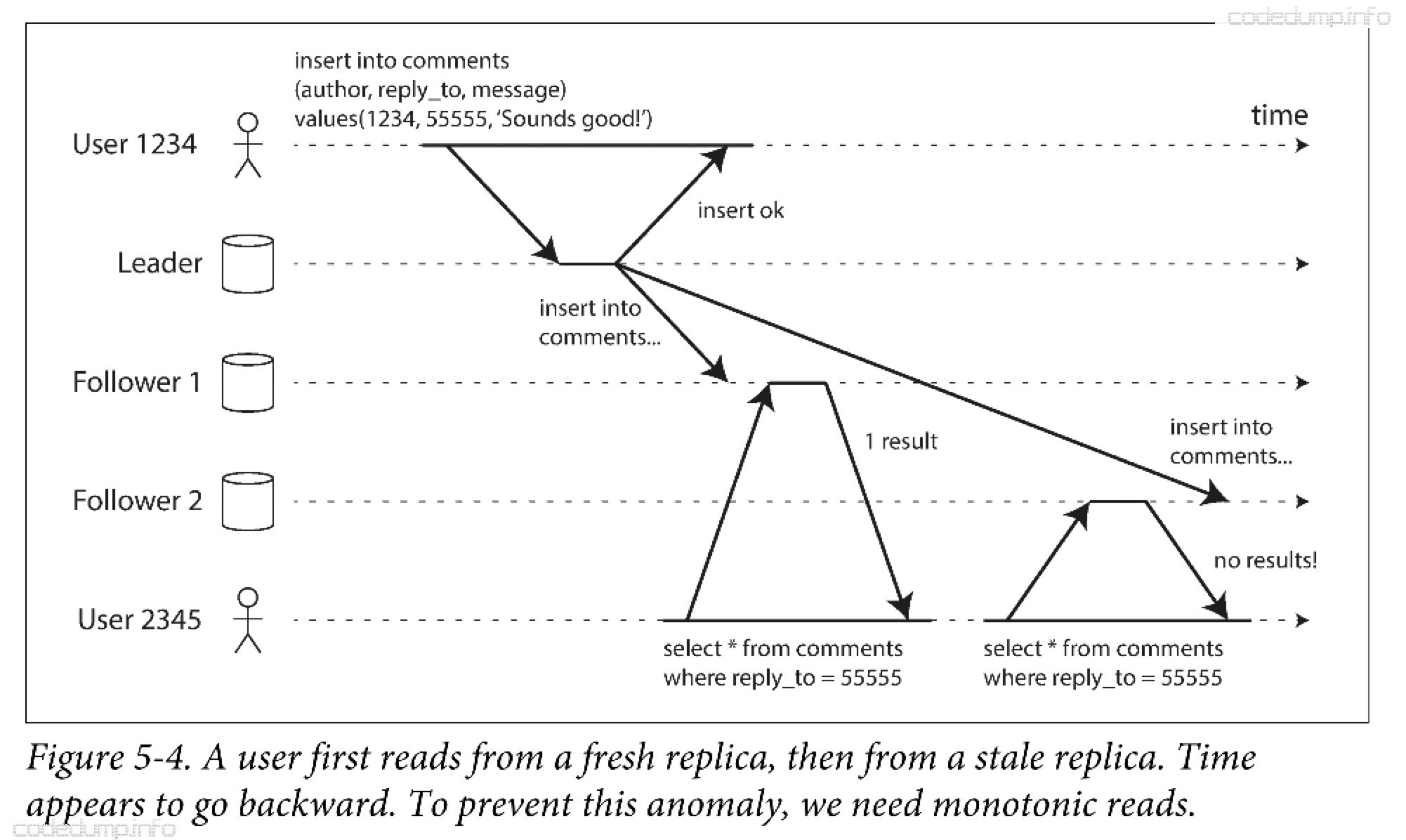
在上图中,用户2345发起了两次读请求,第一次向从节点1发起的请求拿到了最新的数据,但是第二次向从节点2发起的请求得到了旧的数据,这在用户看来,数据发生了“回滚”。
单调读一致性可以确保不会发生这种异常。当读取数据时,单调读保证:如果某个用户进行多次读取,则绝对不会看到数据回滚现象,即在读取到新值之后又发生读取到旧值的情况。
实现单调读一致性的一种方式每个用户的每次读取都从固定的同一副本上进行读取。
前缀一致读(consistent prefix reads) #
前缀一致性读保证,对于一系列按照某个顺序发生的写请求,读取这些内容时也会按照当时写入的顺序来。
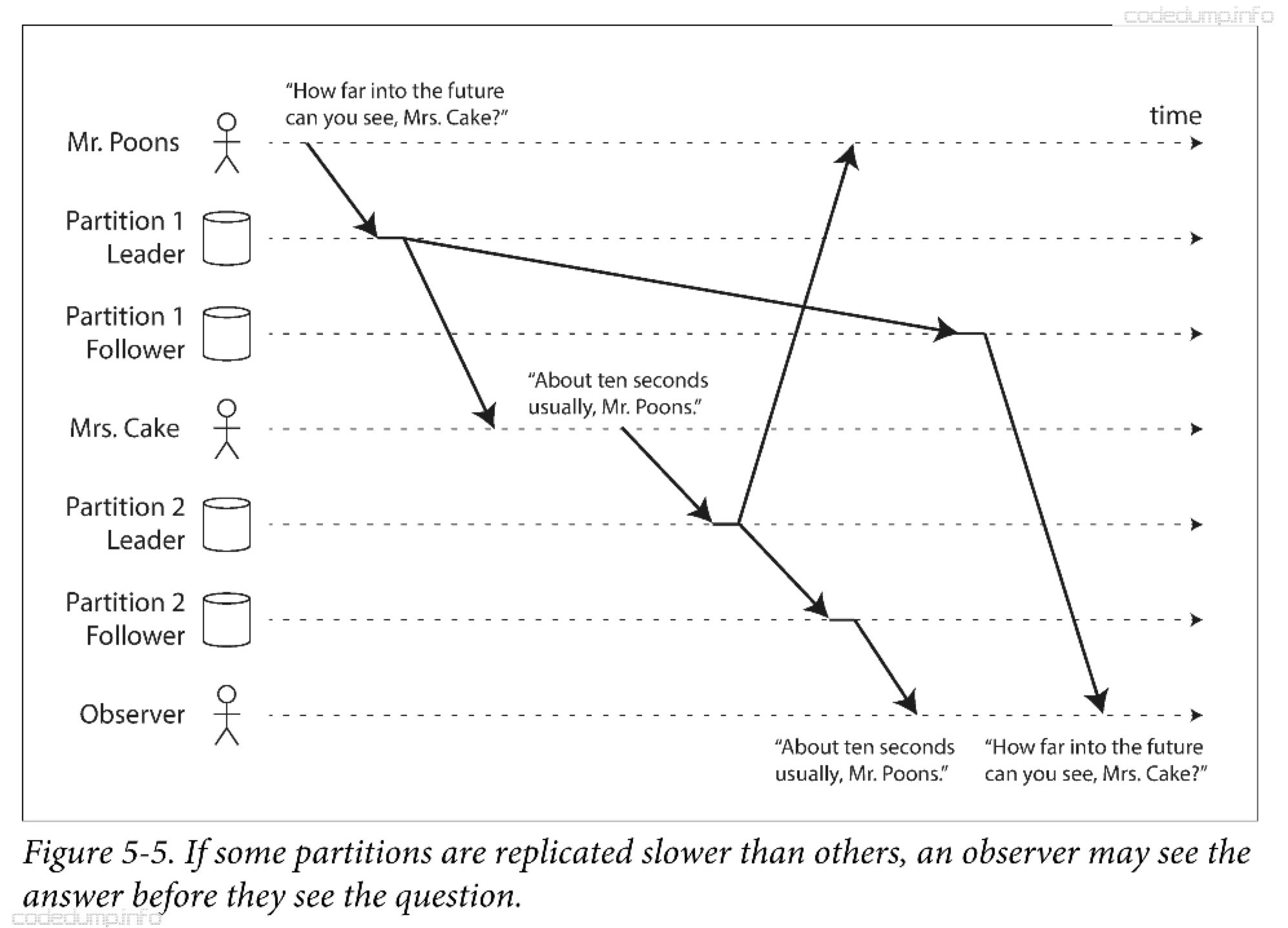
上图中,在观察者看来,数据的先后顺序发生了混淆,导致了逻辑上的混乱。
这种问题是分区情况下出现的特殊问题,在分布式数据库中,不同的分区独立运行,因此不存在全局写入顺序,这就导致用户从数据库中读取数据时,可能看到数据库某部分的旧值和一部分的新值。
实现前缀一致性的一种方案是确保任何具有因果顺序关系的写入都交给一个分区来完成,但是该方案真实实现起来效率不高。
复制滞后的解决方案 #
多主节点复制 #
适用场景 #
多数据中心 #
为了容忍整个数据中心级别故障或更接近用户,可以把数据库的副本横跨多个数据中心。在每个数据中心内,采用常规的主从复制方案;而在数据中心之间,由各个数据中心的主节点来负责同其他数据中心的主节点进行数据的交换、更新。
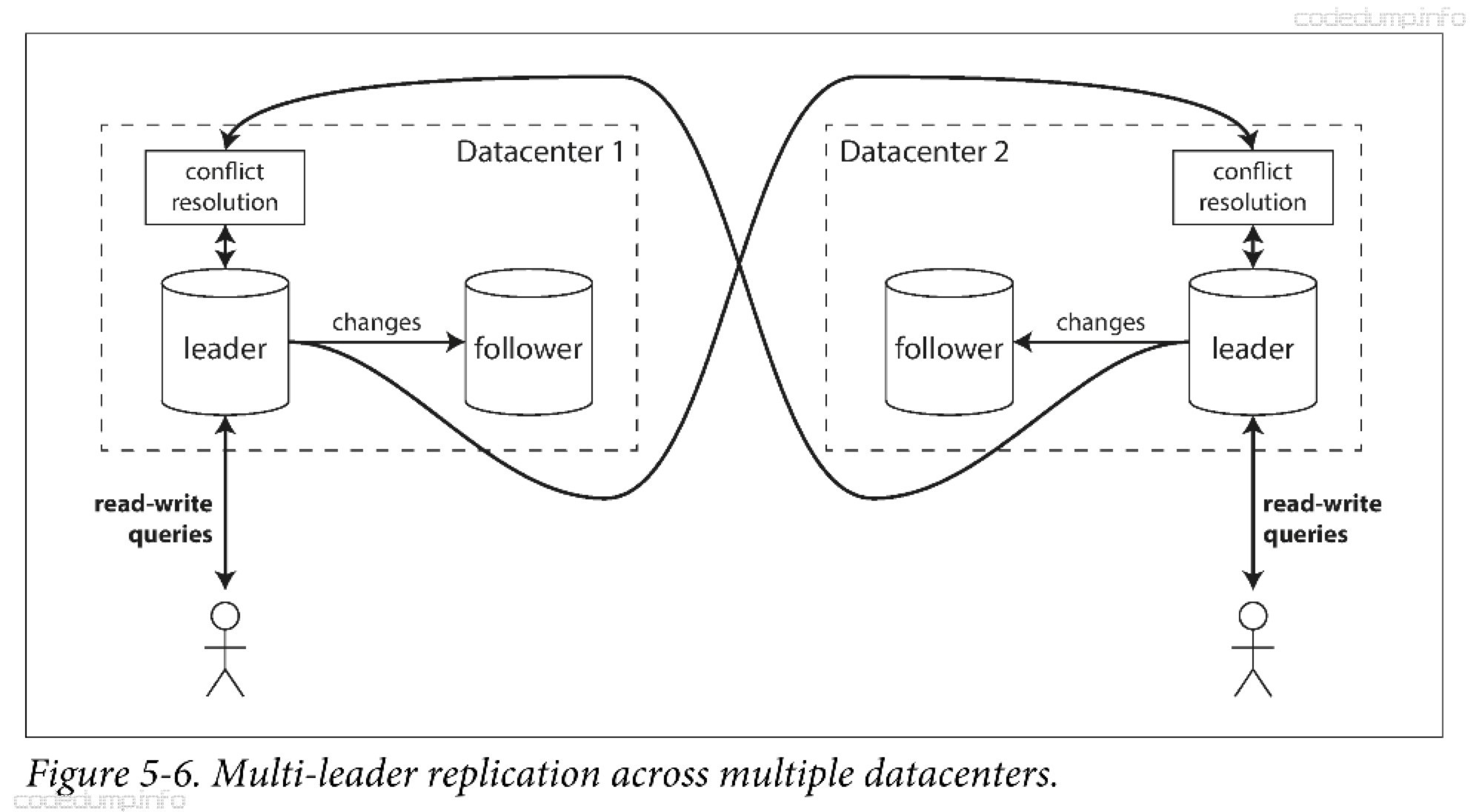
主从复制的优缺点:
-
优点
- 性能:每个写操作可以在本地数据中心就近快速响应,采用异步复制方式将变化同步到其他数据中心。
- 容忍数据中心失败:单个数据中心失败,不影响其他数据中心的继续运行。
- 容忍网络问题:主从复制模型中写操作是同步操作,对数据中心之间的网络性能和稳定性等要求更高。多主节点模型采用异步复制,可以更好的容忍这类问题。
-
缺点:多个数据中心可能同时修改同一份数据,造成写冲突。
离线客户端操作 #
每个客户端可以认为是一个独立的数据中心,这样用户就可以在离线的状态下使用客户端,而在网络恢复之后再将数据同步到服务器。
协作编辑 #
允许多个用户同时编辑文档,如google docs。这样每个用户就是一个独立的数据中心了。
处理写冲突 #
多主复制最大的问题就是要解决写冲突,如下图所示。
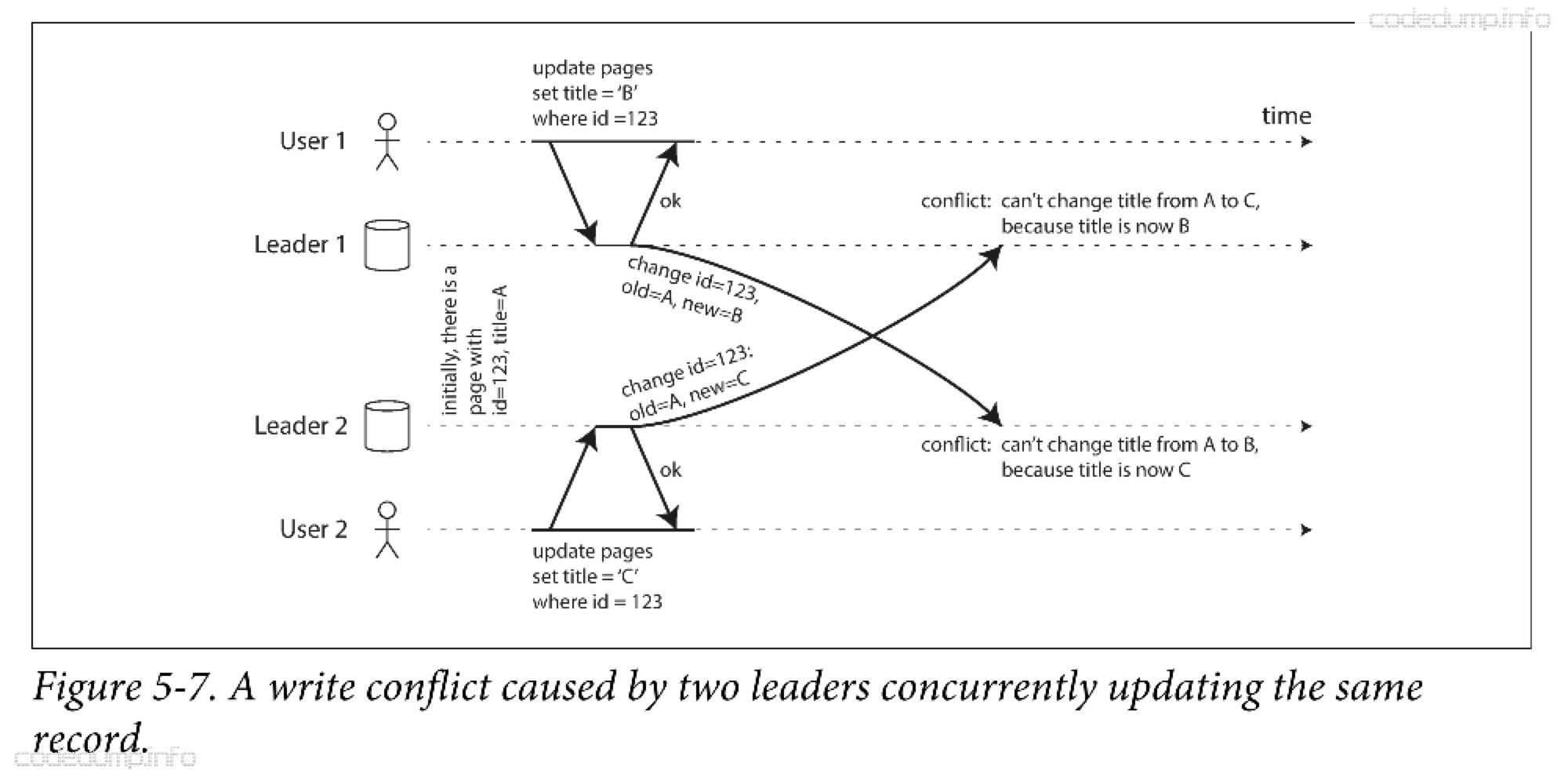
两个用户同时编辑wiki页面,发生了写冲突。
同步与异步冲突检测 #
如果是主从复制数据库,第二个写请求会被阻塞到第一个写请求完成。而在多主从复制模型下,两个写请求都是成功的,并且只有在之后才能检测到写冲突,而那时候要用户来解决冲突已经为时已晚了。
如果要多主从复制模型来做到同步检测冲突,又失去了多主节点的优势:允许每个主节点接受写请求。
因此如果确实想要做到同步检测写冲突,应该考虑使用单主节点的模型而不是多主从节点模型。
避免冲突 #
如果应用层能保证针对特定的一条记录,每次修改都经过同一个主节点,就能避免写冲突问题。
但是,在数据中心发生故障,不得不路由请求到另外的数据中心,或者用户漫游到了另一个位置,更靠近另一个数据中心等场景下,冲突避免不再有效。
收敛于一致状态 #
有以下方式解决冲突的收敛:
- 给每个写入分配唯一的ID,如时间戳、足够长的随机数、UUID等,规定只有高ID的写入做为胜利者。如果是基于时间戳的对比,这种技术被称为后写入者获胜(last write win),但是很容易造成数据丢失。
- 给每个副本分配一个唯一的ID,并制定规则比如最高ID的副本写入成功,这种方式也会导致数据丢失。
- 以某种方式将这些值合并在一起。
- 使用预定义的格式将这些冲突的值返回给应用层,由应用层来解决。
自定义冲突解决逻辑 #
解决冲突最合适的方式还是依靠应用层,可以在写入或者读取时执行。
第六章 数据分区 #
分区的定义:每一条数据只属于某个特定分区。分区的目的是为了提高可扩展性,这样不同的分区可以放在无共享集群的不同节点上。
数据分区与数据复制 #
键值数据的分区 #
基于关键字区间的分区 #
给每个分区分配一段连续的关键字或者关键字区间(以最小值和最大值来指示),从关键字区间的上下限可以确定哪个分区包含这些关键字。
关键字的区间段不一定要均匀分布,这是因为数据本身可能就不是均匀的。比如,某些分区包含以A和B开头字母的键,而某些分区包含了T、U、V、X、Y和Z开始的单词。
基于关键字的区间分区的缺点是某些访问模式会导致热点(hot spot)。比如关键字是时间戳,分区对应一个时间范围,那么可能会出现所有的写入操作都集中在同一个分区(比如当天的分区),而其他分区始终处于空闲状态。
为了避免类似的问题,需要使用时间戳以外的其他内容作为关键字的第一项。
基于关键字Hash值分区 #
基于关键字Hash值分区,可以解决上面提到的数据倾斜和热点问题,但是丧失了良好的区间查询特性。
负载倾斜和热点 #
基于关键字Hash值分区的办法,可以减轻数据热点问题,但是不能完全避免这类问题。一种常见的极端场景是,社交网络上某个名人有几百万的粉丝,当其发布一些热点事件时可能会引起访问风暴。此时,Hash起不到任何分流的作用。
大部分系统解决不了这个问题,只能通过应用层来解决这类问题。比如某个关键字被确认是热点,一个简单的技术就是在关键字的开头或结尾处添加随机数,这样将访问分配到不同的分区上。但是随之而来的问题就是,之后的任何读取都需要额外的工作,必须将这些分区上的读取数据进行合并。
分区与二级索引 #
键值类数据库的分区相对还简单一些,但是如果涉及到二级索引就变得复杂了。二级索引主要的挑战在于:它们不能规整的映射到分区中。
基于文档分区的二级索引 #
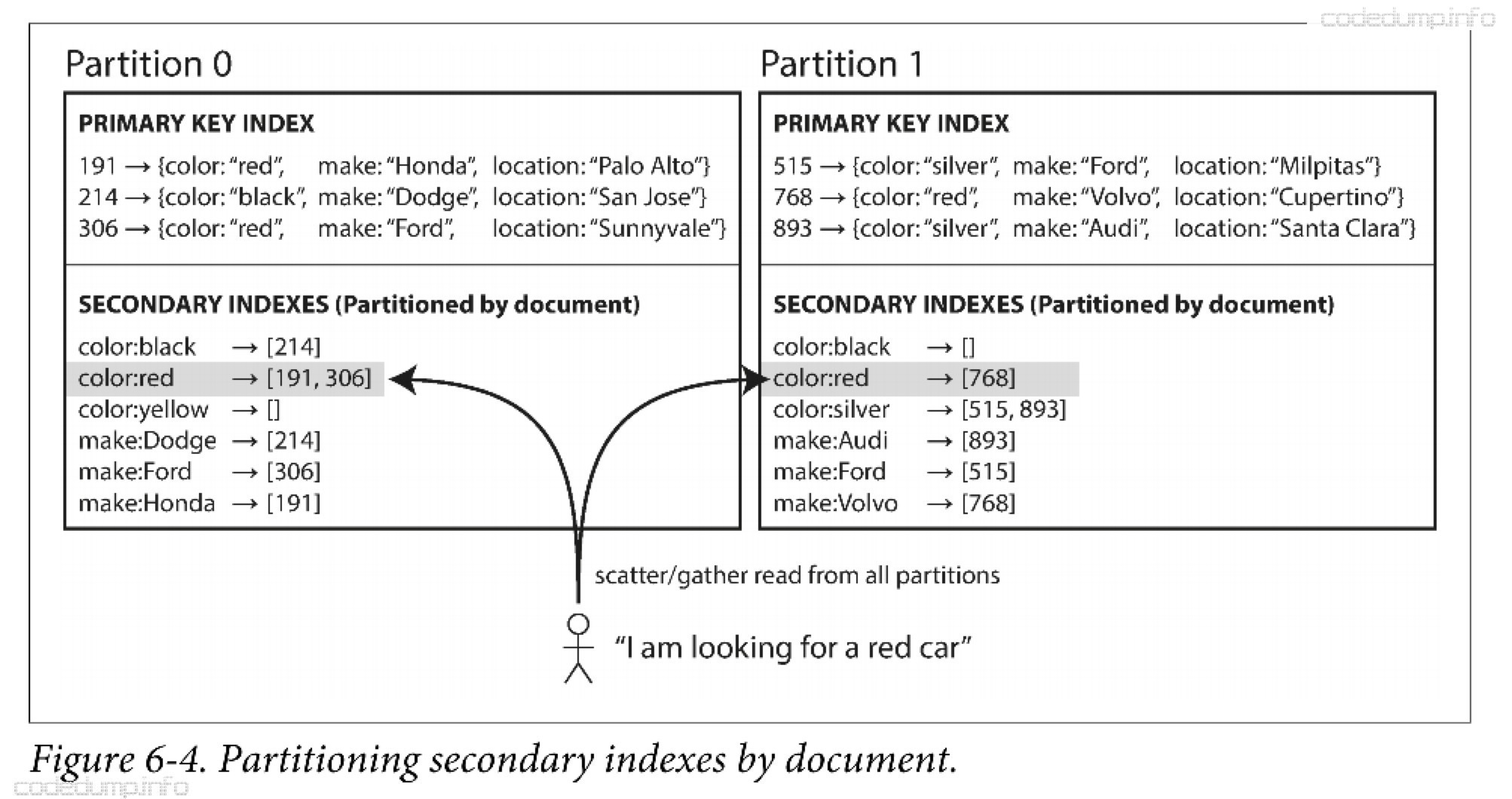
上图中,数据根据ID 进行分区,但是实际查询的时候,还可以按照颜色和厂商进行过滤,所以每个分区上面还创建了颜色和厂商的索引。每次往分区中写入新数据时,自动创建这些二级索引。
在这种索引方式中,每个分区完全独立。各自维护自己的二级索引。因此文档索引也成为本地索引,而不是全局索引。
但是读取的时候,需要查询所有的分区数据然后进行合并才返回给客户端,这种叫分散/聚集(scatter/gather)。
基于词条的二级索引 #
可以对所有的数据构建全局索引,而不是每个分区维护自己的本地索引。而且吧,为了避免成为瓶颈,不能将全局索引放在一个节点上,否则又破坏了分区均衡的目标,因此全局索引数据也需要进行分区。
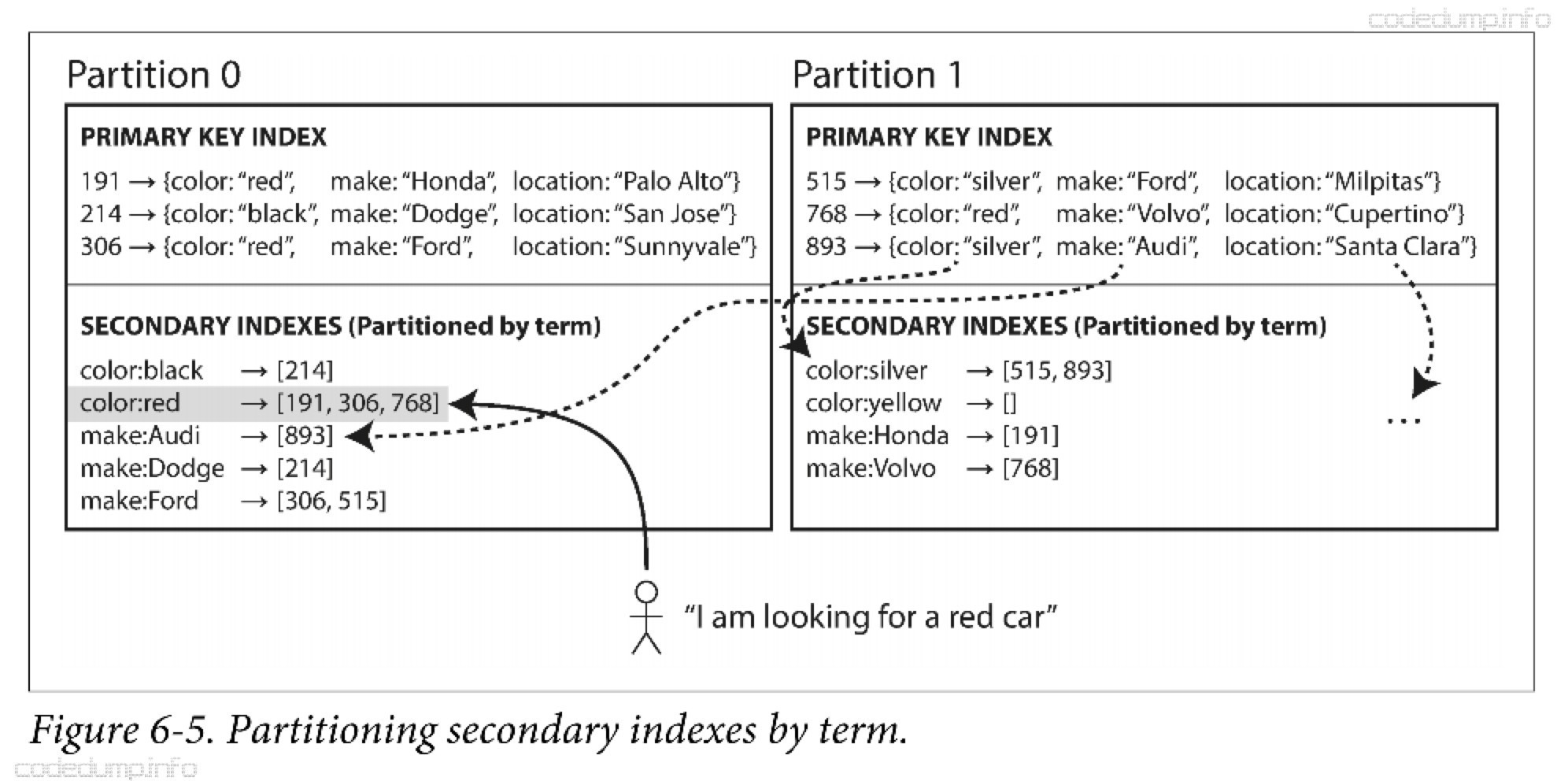
上图中,所有数据分区中的颜色进行了分区,比如从a到r开始的颜色放在了分区0中,从s到z的颜色放在了分区1中,类似的,厂商索引也被分区。这种索引方式成为词条分区(term-partitioned)。
优点:读取高效,不需要采用scatter/gather方式对所有分区都进行查询;缺点是写入速度慢并且非常复杂,主要是因为单个文档需要更新的时候,里面可能涉及多个二级索引,而二级索引又放在不同的节点上。
在实践中,对全局二级索引数据的更新一般都是异步进行的。
分区再平衡(Rebalancing Partitions) #
实际中,数据会发生某些变化,这时候需要将数据和请求从一个节点转移到另一个节点。这样的一个迁移负载的过程称为再平衡(rebalance)。
分区再平衡至少需要满足:
- 平衡之后,负载、数据存储、读写请求能够在集群范围内更均匀分布。
- 再平衡过程中,数据库可以继续处理客户端的读写请求。
- 避免不必要的负载迁移。
下面谈各种再平衡策略。
为什么不能用取模? #
对节点数进行取模的方式,最大的问题在于如果节点的数据发生了变化,会导致很多关键字从现有的节点迁移到另一个节点。
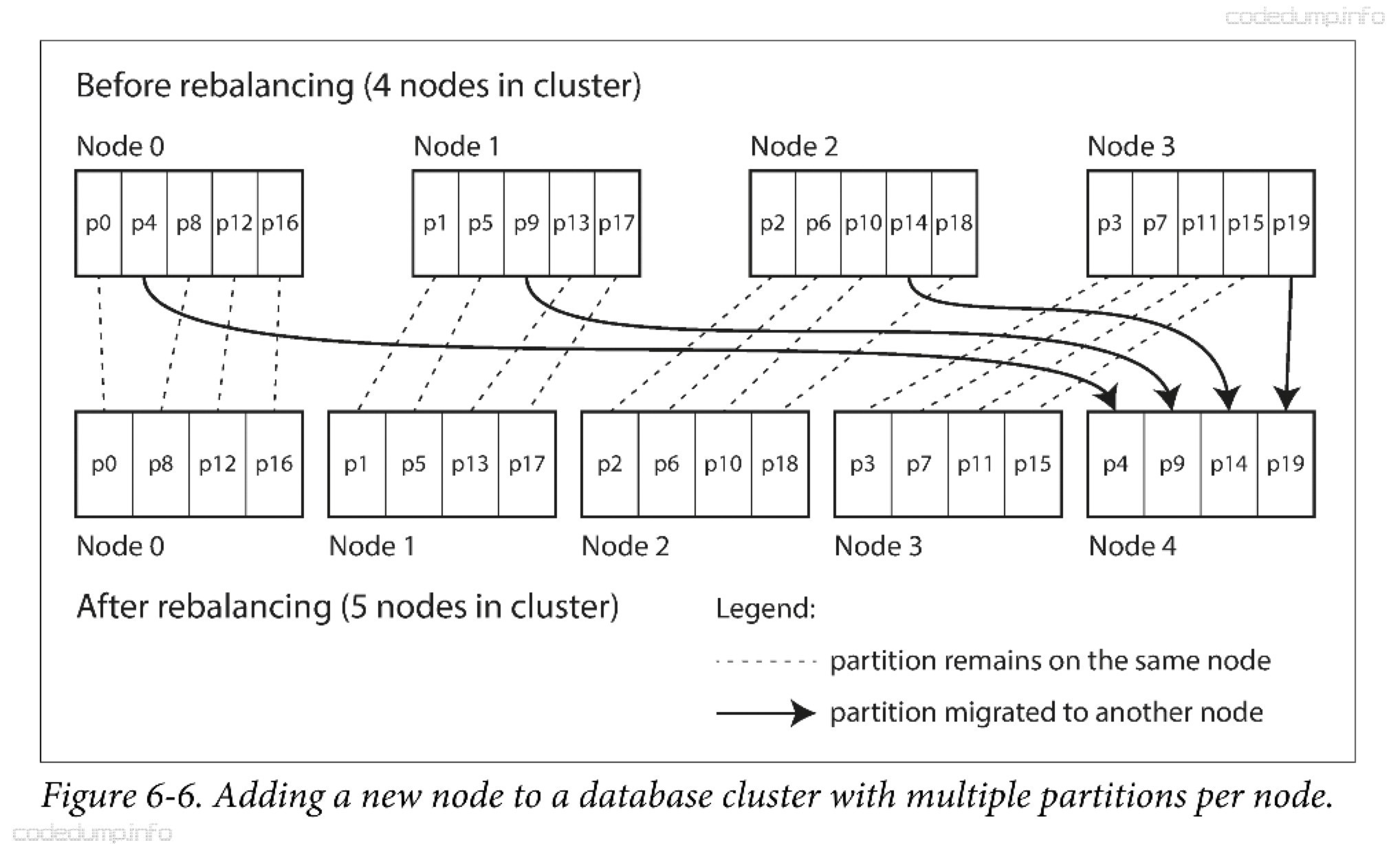
固定数量的分区 #
创建远超实际节点数的分区数,然后给每个节点分配多个分区。比如只有10个节点的集群,划分了1000个逻辑分区。
如果集群中添加了一个新节点,该新节点就可以从每个现有节点上匀走几个分区,直到分区再次达到全局平衡。
这个方式的优点在于,关键字与逻辑分区的映射关系一开始就固定下来了,节点数量的变更只是改变了逻辑分区分布在哪些节点上。节点间迁移分区数据需要时间,这个过程中,就分区依然可以处理客户端的读写请求。
第七章 事务 #
事务提供了一种机制,应用程序可以把一组读和写操作放在一个逻辑单元里,所有在一个事务的读和写操作会被视为一个操作:要么全部失败,要么全部成功,因此应用程序不需要担心部分失败(partial failure)问题,可以安全的重试。
深入理解事务 #
ACID #
A(Atomicity,原子性):在一个事务中的所有操作,要么全部成功,要么全部失败,不存在部分成功或者部分失败的情况。在出错时中断事务,前面成功的操作都会被丢弃。
C(Consistency,一致性):对数据有特定的预期状态,任何数据修改必须满足这些状态约束,比如针对一个账号,账号上的款项必须保持平衡。
I(Isolation,隔离性):并发执行的多个事务,不会相互影响。
D(Durability,持久性):一旦事务提交,数据将被持久化存储起来。
弱隔离级别 #
可串行化的隔离会影响性能,而很多业务不愿意牺牲性能,因而倾向于使用更弱的隔离级别。
以下介绍几个常见的弱隔离级别(非串行化)。
读提交(read committed) #
读提交是最基本的事务级别,提供两个保证:
- 读数据库时,只能读到被提交成功的数据(不会读到脏数据)。
- 写数据库时,只会覆盖已被提交成功的数据(不会脏写)。
防止脏读 #
如果一个事务被中断或者没有提交成功,而另一个事务能读取到这部分没有提交成功的数据,这就是“脏读”。
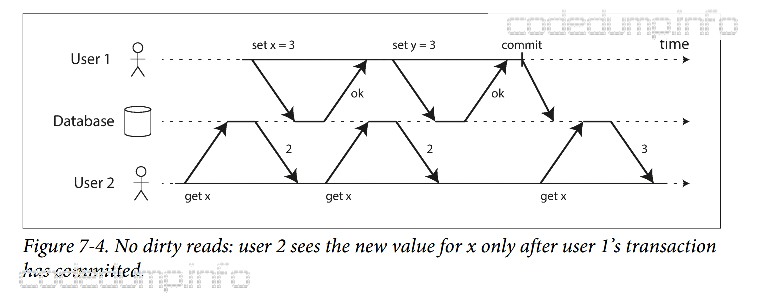
如上图,用户2仅在用户1的事务提交成功之后,才能读取到这次事务修改的新值x=3。
防止脏写 #
如果先前写入的数据是尚未提交事务的一部分,而被另一个事务的写操作覆盖了,这就是脏写。通常防止脏写的办法是推迟第二个写请求,等到前面的事务操作提交。

如上图,脏写问题导致alice和bob的数据混杂在一起了。
实现读提交 #
实现防脏写:数据库通常使用行级锁来防止脏写,事务想修改某个对象,必须首先获得该对象的锁,直到事务结束。
实现防脏读:也可以使用前面的防脏写来实现防脏读,但是这样代价太大了。一般的方式是保存这个值的两个版本,事务没有提交之前返回旧的值,提交之后才返回新的值。
快照隔离级别(Snapshot isolation)和重复读 #
尽管上面的读提交已经能解决一部分问题,但是还是有一些问题不能解决的,如下图:
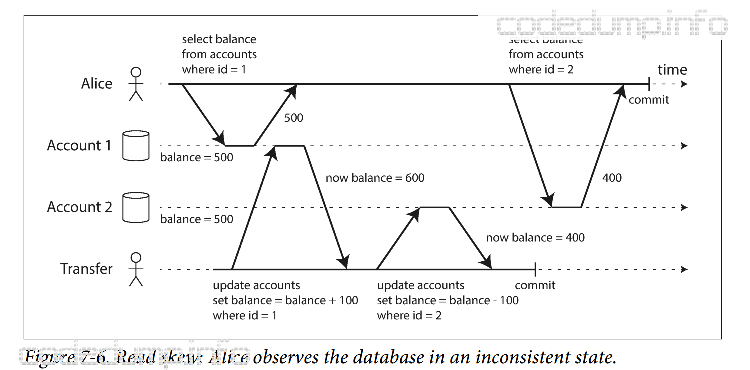
上图中,alice有两个账号,但是如果alice在转账过程中去查看账户,会发现少了100美元。
这种异常现象称为”不可重复读取(nonrepeatable read)“或者”读倾斜(read skew)“问题。
快照隔离级别是解决以上问题的常见手段。每个事物都从数据库的一致性快照中读取,事务一开始看到的是最近所提交的数据,即使数据随后可能被另一个事务修改,但保证事务都只能看到该特定时间点的旧数据。
实现快照隔离级别 #
考虑到多个正在进行的事务可能会在不同的时间点查看数据库状态,所以数据库保留了对象的多个不同的提交版本,称为MVCC(Multi Version Concurrency Control)。如下图所示:
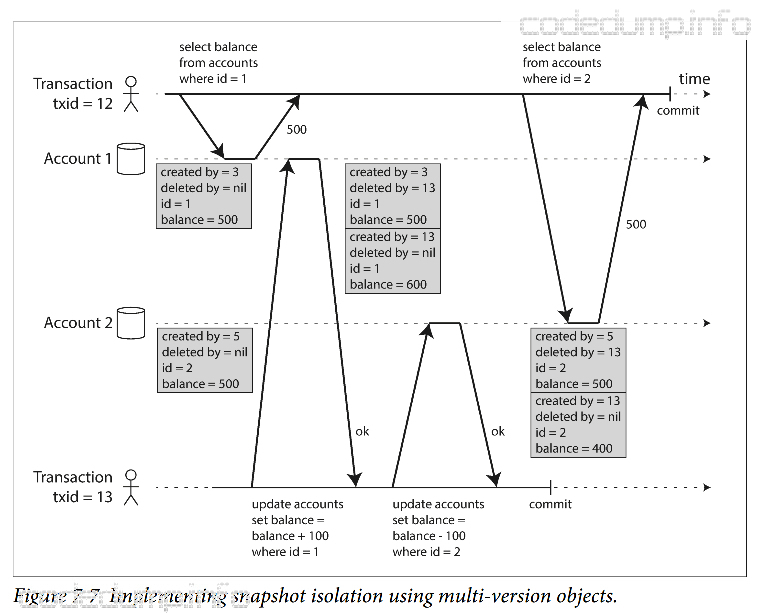
给每个事务一个唯一的、单调递增的事务ID(txid),每当事务写入新数据的时候,所写的数据都会带上写入者的事务ID。表中的每一行的created_by字段,用于保存创建该行的事务ID;deleted_by初始为空,用于保存请求删除该行的事务ID,仅用于标记为删除。事后,仅当确认没有其他事务引用该删除行的时候,才执行真正的删除操作。
一致性快照的可见性原则:
- 事务开始的时刻,创建该对象的事务已经完成了提交。
- 对象还没有被标记为删除,或者即使标记了,但是删除事务在当前事务开始时还没有完成提交。
写倾斜和幻读 #
如下图所示,开发一个医院轮班系统,在保证至少有一个医生在值班的情况下,可以申请休假,但是这还是会出现问题:
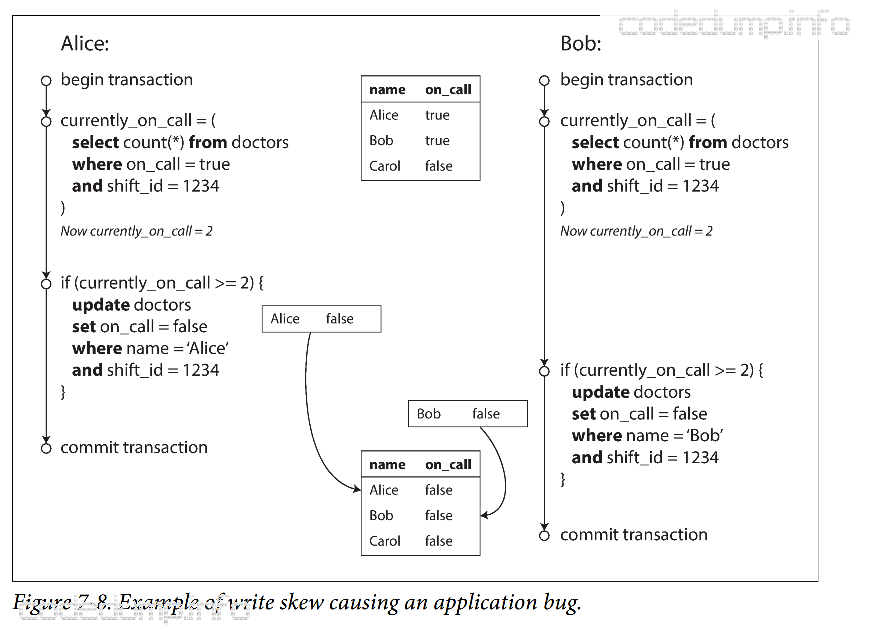
这种情况称为”写倾斜“,既不是脏写,也没有导致数据丢失。两次事务更新的是不同的对象,写冲突并不直接。
写倾斜都有类似的模式:
- 输入一些条件,按照条件查询出满足条件的行。
- 根据查询结果,应用层决定下一步操作。
- 应用程序需要更新一部分数据,而这个更新操作会改变步骤2的做出决定的前提条件,即写入之后再执行步骤1的查询操作将得到不同的结果。
这种在一个事务中的写入改变了另一个事务查询结果的现象,称为幻读(phantom)。
串行化 #
第八章 分布式系统的挑战 #
本章描述分布式系统中可能出现的各种问题。
故障与部分失效 #
单机上的程序,以一种确定性的方式运行:要么工作,要么出错。
然而涉及到多台节点时,会出现系统的一部分正常,一部分异常的情况,称为“部分故障(partial failure)”。
正是由于这种不确定性和部分失效大大提高了分布式系统的复杂性。
不可靠的网络 #
分布式系统中的多个节点以网络进行通信,但是网络并不保证什么时候到达以及是否一定到达。等待响应的过程中,很多事情可能出错:
- 请求可能丢失。
- 请求在某个队列里等待,无法马上发送。
- 远程节点因为崩溃、宕机等原因已经失效。
- 远程节点因为某些原因暂时无法响应。
- 远程节点接收并且处理了请求,但是回复却丢失了。
- 远程节点已经完成了请求,但是回复被延迟了。
如下图中:

在上图中,请求没有得到响应,但是无法区分是因为什么原因,可能有:请求丢失、远程节点关闭、响应丢失等情况。
从以上可以知道,异步网络中的消息没有得到响应,但是无法判断具体的原因。
处理这种问题通常采用超时机制:在等待一段时间之后,如果没有收到回复则选择放弃,并且认为响应不会到达。
检测网络故障 #
如果超时是检测网络故障的唯一可行方法,那么这个超时时间应该如何选择?
太小:出现误判的情况。太大:意味着要很长时间才能宣布节点失效了。
假设有一个虚拟的系统,网络可以保证数据报在一个最大延迟范围内:要么在时间d内交付完成,要么丢失。此外,非故障节点在时间r内完成请求的处理。此时,就可以确定成功的请求总是在2d+r时间内完成,因此这个时间是一个理想超时时间。
同步网络和异步网络 #
既然同步网络可以在规定的延迟时间内完成数据的发送,且不会丢失数据包,那么为什么分布式系统没有选择同步网络,在硬件层面就解决网络问题?
原因在于,固定电话网络中的电路与TCP连接存在很大的不同:电路方式总是预留固定带宽,在电路建立之后其他人无法使用;而TCP连接的数据包则会尝试使用所有可用的网络带宽。TCP可以传送任意大小可变的数据块,会尽力在最短时间内完成数据传送。
不可靠的时钟 #
很多操作依赖时间,但是时间也是靠不住的,本节就是说这部分的内容。
计算机的时钟分为两种,墙上时钟(time-of-day clock)和单调时钟(monotonic clock),但是两者在使用上是有区别的。
墙上时钟根据某个日历(也成为墙上时间,wall-clock time)返回当前的日期和时间。比如Linux的系统调用clock_gettime(CLOCK_REALTIME)返回自1970年1月1日以来的秒数和毫秒数。
单调时钟更适合用于测试持续时间段(时间间隔),Linux的系统调用clock_gettime(CLOCK_MONITONIC)返回的就是单调时钟。单调时钟的名字源于它们总是保证向前走而不会出现回拨现象。
可以在一个时间点读取单调时钟的值,完成某项工作然后再次检查时钟,时钟之间的插值就是两次检查的时间间隔。
但是,单调时钟的绝对值没有任何意义。
单调时钟不需要同步,而墙上时钟需要根据NTP服务器或外部时间源做调整。
依赖时钟的同步 #
某些操作强依赖时钟的同步,这里往往容易出现问题,这一节就是列举这些问题。
时间戳与事件顺序 #
一个常见的功能:跨节点的事件排序,如果高度依赖时钟计时,就存在一定的技术风险。比如,两个客户端同时写入数据库,谁先到达,哪个操作是最新的?
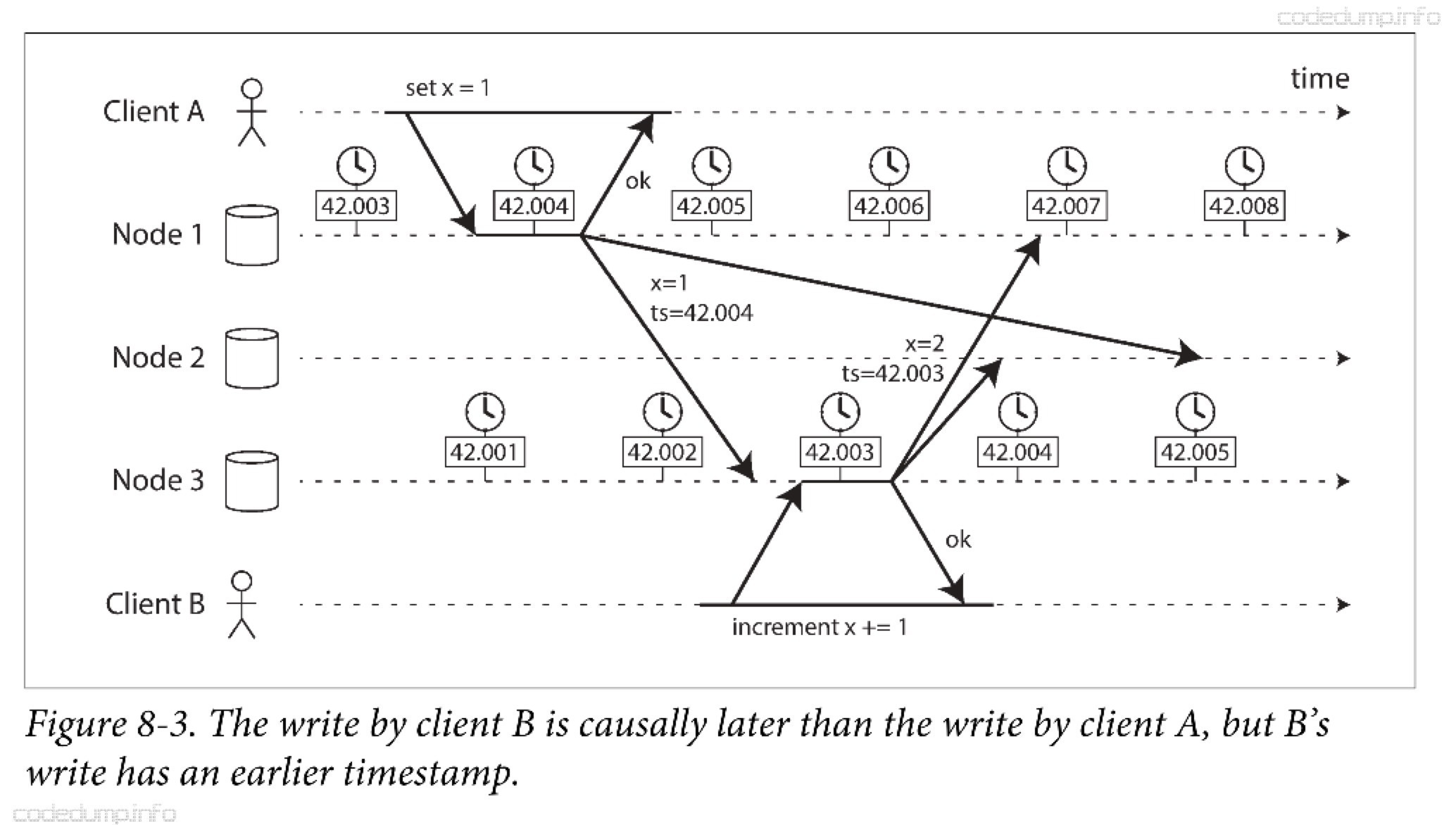
上图中,客户端A写入x=1的时间是42.004秒,而客户端B写入x+=1即x=2虽然在后面发生但是时间是42.003秒。节点2在收到这两个事件时,会根据时间戳错误的认为x=1是最新的值,丢弃了x=2的值。
这种冲突解决方式称为“最后写入获胜(Last Write Win)”,但是这样保持“最新”值并丢弃其他值的做法,由于“最新”的定义强依赖于墙上时钟,则会引入偏差。
时钟的置信区间 #
不应该把墙上时间视为一个精确的时间点,而更应该被视为带有置信区间的时间范围。比如,系统有95%的置信度认为目前时间在[10.3,10.5]秒之间。
比如Google Spanner中的TrueTime API,在查询当前时间时,会得到两个值:[不早于,不晚于]分别代表误差的最大偏差范围。
全局时钟的快照隔离 #
进程暂停 #
另外一个分布式系统中危险使用时钟的例子:假设数据库每个分区只有一个主节点,只有主节点可以接收写入,那么其它节点该如何确信该节点没有被宣告失效,可以继续安全写入呢?
一种思路是主节点从其它节点获得一个租约,类似一个带有超时的锁。某一个时间只有一个节点可以拿到租约,某节点获得租约之后,在租约到期之前,它就是这段时间内的主节点。为了维持主节点的身份,节点必须在到期之前定期去更新租约。如果节点发生了故障,则续约失败,这样另一个节点到期之后就可以接管。
典型流程类似这样:
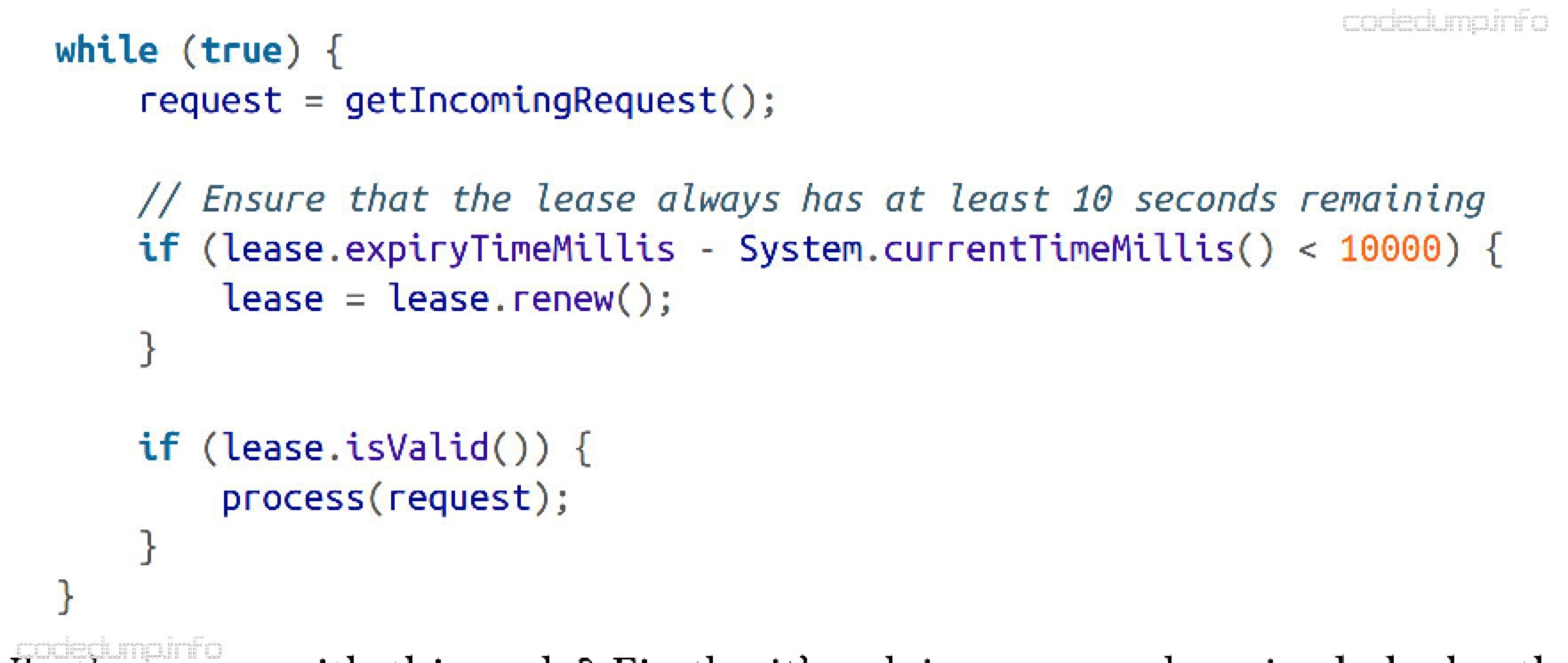
这段代码有几个问题:
- 依赖于同步的时钟,租约到期时间由另一台机器锁设置,并和本地时间进行比较。如果两者有比较大的误差则可能出现问题。
- 代码中假定了检查点的system.currentTimeMillis()和请求处理process(request)间隔很短。但是,如果进程由于GC等原因被暂停,也有可能发生问题。
知识、真相与谎言 #
以上阐述了分布式系统中的网络、时钟都不是很靠谱,那么分布式系统中什么信息才具有较大的可信度呢?
在分布式系统中,我们可以明确列出对系统行为(系统模型)的若干假设,然后以满足这些假设条件来为目标构建实际运行的系统。在给定系统模型下,可以验证算法的正确性。这也意味着即使底层模型仅提供少数几个保证,也可以在系统软件层面实现可靠的行为保证。
真相由多数决定 #
节点不能根据自己的信息来判断自身的状态。由于节点可能随时会失效,可能会暂停、假死,甚至最终无法恢复,因此分布式系统不能完全依赖于单个节点。目前,许多分布式算法都依靠法定票数,即在节点之间进行投票。任何决策都需要来自多个节点的最小投票数,从而减少对特定节点的依赖。
这其中也包括宣告某个节点失效。如果有法定数量的节点声明另一个节点失效,即使该节点仍然感觉自己存活,也必须接受失效的裁定进行下线操作。
主节点与锁 #
有很多情况下,需要在系统范围内确保只有一个实例,比如:
- 只允许一个节点做为数据库分区的主节点,以防止出现脑裂现象。
- 只允许一个事务或客户端持有特定资源的锁,以防止同时写入。
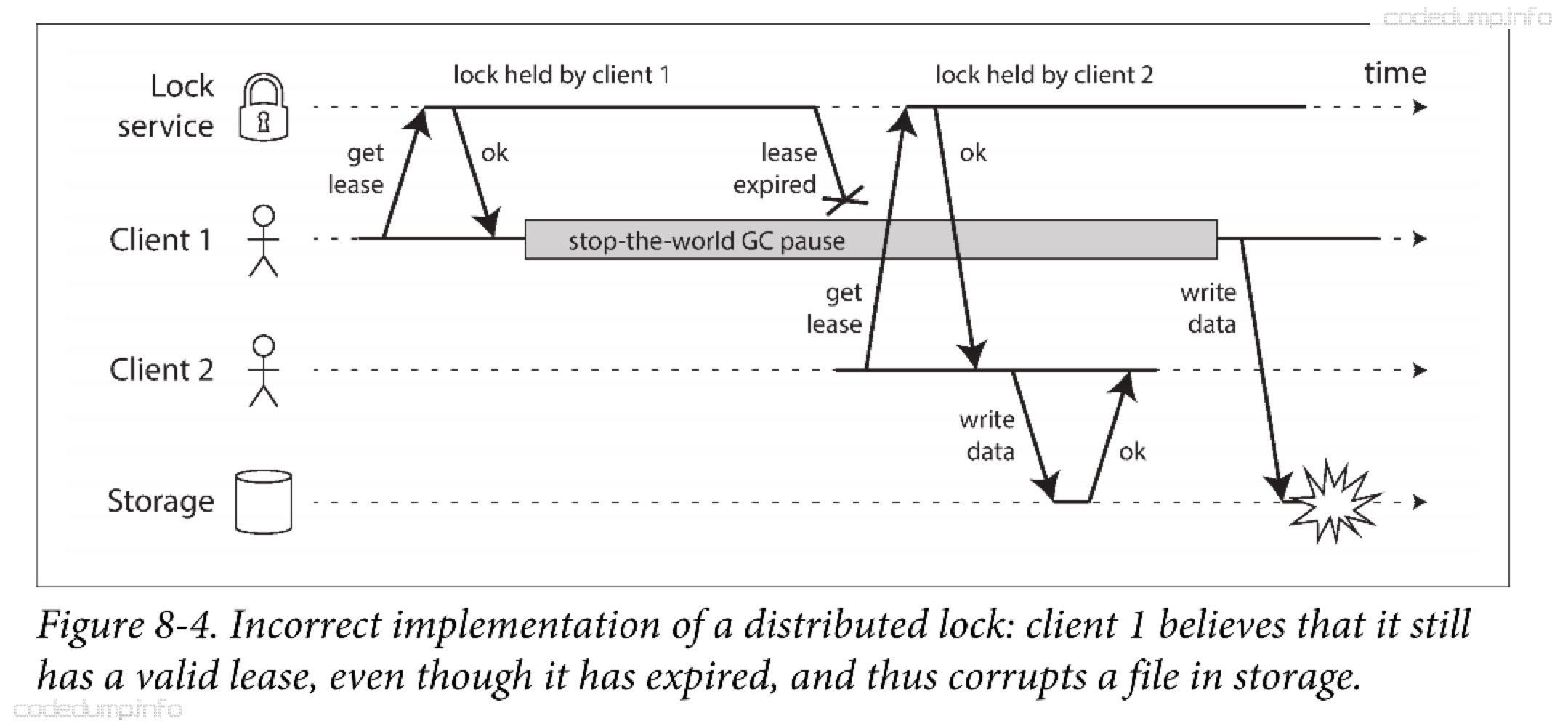
在分布式系统中,即使某个节点自认为自己是“唯一的那个”,但并不一定系统中的多数节点都这么认为。当系统中的多数节点认为某节点已经失效,但是该节点还继续充当“唯一的那个”节点工作时,就可能出现问题。
如下图中所示,客户端1的锁租约已经到期,但是仍然自认为有效,导致了数据被破坏。
Fencing与锁 #
当使用锁和租约机制来保护资源的并发访问时,必须确保过期的“唯一的那个”节点不影响其他正常部分。要实现这一点,可以使用fencing(栅栏,隔离之一)技术。
假设每次锁服务在授予锁或租约时,还会返回一个fencing令牌,该令牌每次授予都会递增。然后,客户端每次向存储系统发起写请求时,都必须包含所持有的fencing令牌。
如下图所示,客户端1获得锁租约的时候得到了令牌33,随后陷入长时间暂停直到租约到期。此时客户端2获得了新的锁租约和令牌34。客户端1恢复之后尝试进行写请求,但是此时带上的令牌33小于34,所以被拒绝写操作。
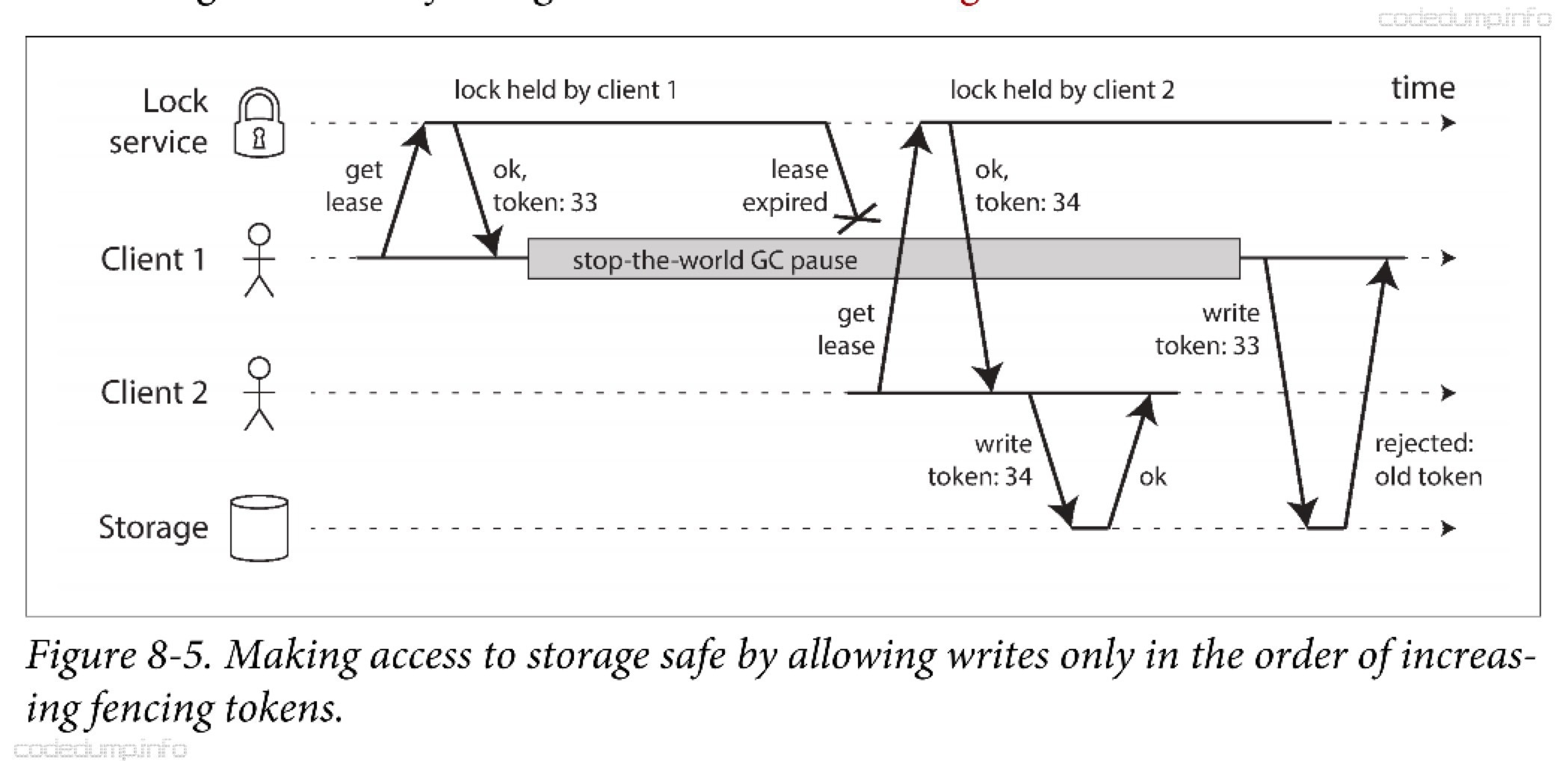
拜占庭故障 #
fencing令牌可以用于检测并阻止无意的误操作,但是当节点有意故意破坏系统时,在发送消息时就可以故意伪造令牌了。
在不信任的环境中需要达成共识的问题被称为拜占庭将军问题。
理论系统模型与现实 #
算法的实现不能过分依赖特定的硬件和软件配置。这就要求我们对预期的系统错误进行形式化描述,通过定义一些系统模型来形式化描述算法的前提条件。
在计时方面,有三种常见的模型:
- 同步模型:同步模型假定有上界的网络延迟,有上界的进程暂停和有上界的时钟误差。注意,这并不意味着完全同步的时钟或网络延迟为0.只是意味着清楚的了解网络延迟、暂停和时钟漂移不会超过某个固定的上界。
- 部分同步模型:部分同步意味着系统在大多数情况下像一个同步系统一样运行,但有时候会超出网络延时,进程暂停和时钟漂移的预期上界。这是一个比较现实的模型:大多数情况下,网络和进程比较稳定,但是必须考虑到任何关于时机的假设都有偶尔违背的情况,而一旦发生,网络延迟、暂停和时钟偏差都可能会变得非常大。
- 异步模型:在这个模型中,一个算法不会对时机做任何假设,甚至里面根本没有时钟(也没有超时机制)。
除了计时模型,还需要考虑到节点失效,有以下三种常见的节点失效系统模型:
- 崩溃中止模型:在这个模型中,算法假设一个节点以一种方式发生故障,即遭遇系统崩溃。这意味着节点可能在任何时候突然停止响应,且该节点以后永远消失,无法恢复。
- 崩溃恢复模型:节点可能在任何时候发生崩溃,且可能在一段(未知的)时间之后得到恢复并再次响应。在崩溃恢复模型中,节点上持久化存储的数据会在崩溃之后保存,而内存中的状态会丢失。
- 拜占庭失效模型:节点可能发生任何问题,包括试图作弊和欺骗其它节点。
算法的正确性 #
为了定义算法的正确性,需要描述它的属性信息,例如对于fencing令牌生成算法,有如下属性:
- 唯一性:两个令牌请求不能获得相同的值。
- 单调递增:如果请求x返回了令牌t1,请求y返回了令牌t2,且x在y开始之前先完成,那么t1<t2。
- 可用性:请求令牌的节点如果不发生崩溃那么一定能收到响应。
安全性(safety)和活性(liveness) #
有必要区分两种不同的属性:安全性和活性。在上面的例子中,唯一性和单调递增属于安全性,可用性属于活性。
两种性质有何区别?活性的定义中通常包含暗示“最终”一词(最终一致性就是一种活性)。
安全性可以理解为“没有发生意外”,活性类似“预期的事情最终一定会发生”。
- 如果违反了安全性,可以明确指向发生的特定的时间点(例如,唯一性如果被违反,可以定位到具体哪个操作产生了重复令牌)。且一旦违反了安全性,违规行为无法撤销,破坏已实际发生。
- 活性则反过来,可能无法明确某个具体的时间点(例如一个节点发送了一个请求,但还没有收到回应),但总是希望在未来某个时间点可以满足要求(即收到回复)。
区分安全性和活性的一个好处是可以帮助简化处理一些具有挑战性的系统模型。通常对于分布式算法,要求在所有可能的系统模型中,都必须满足安全性。也就是说,即使所有节点发生崩溃,或者整个网络中断,算法确保不能返回错误的结果。
而对于活性,则存在一些必要条件。例如,只有在系统多数节点没有崩溃,以及网络最终可以恢复的前提下,才能保证可以收到响应。
第九章 一致性与共识 #
一致性保证 #
最终一致性(eventual consistency):如果停止更新数据,等待一段时间(时间长度未知),则最终所有读请求将返回相同的内容。
然而最终一致性是一种非常弱的一致性保证,因为无法知道何时(when)系统会收敛。而在收敛之前,读请求都可能返回任何值。
可线性化(Linearizability) #
可线性化(Lineariazability),也被称为原子一致性(atomic consistency),强一致性(strong consistency),其基本的思想是让一个系统看起来好像只有一个数据副本,且所有的操作都是原子的。有了这个保证,应用程序不需要再关系系统内部有多少个副本。
在一个可线性化的系统中,一旦客户端成功提交写请求,所有客户端的读请求一定能看到刚刚写入的值。这一保证让客户端认为只有一个副本,这样任何一次读取都能读到最新的值,而不是过期的数据。
下图来解释在一个非线性化的系统中,可能出现什么问题。
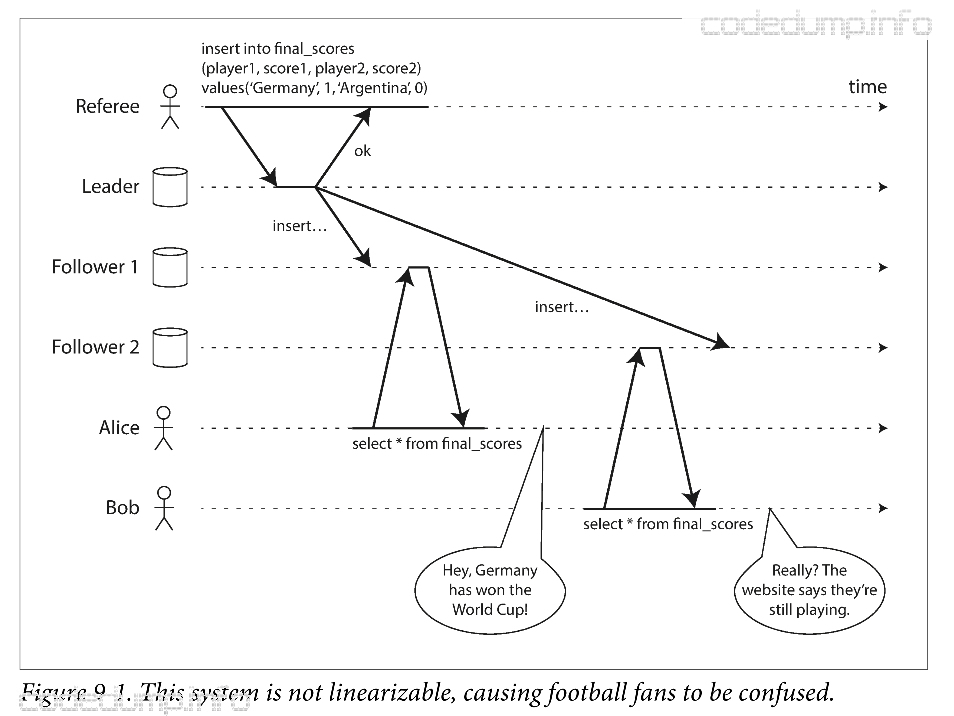
上图中,alice和bob同时等待2014年世界杯决赛的结果。在宣布最终比分之后,alice看到了最终的结果,然后将此结果告诉了bob,bob马上在自己的手机上刷新想看最新的结果,但是却返回了过期的数据,显示当前比赛还在进行中。
如何实现可线性化? #
前面只是简单介绍了可线性化的思想:使系统看起来只有一个数据副本。为了更好的理解可线性化,看下面的图示例子。
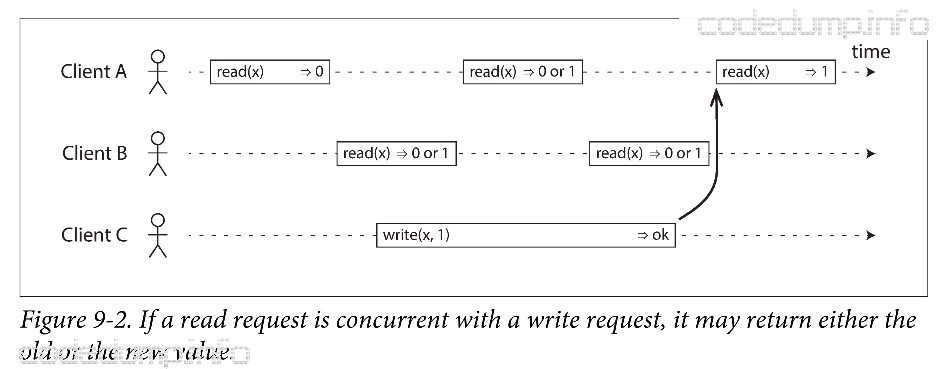
在上图中,分为两种操作:针对某个值进行read和write操作。
客户端A的第一次和最后一次read操作,分别返回0和1,这没有问题,因为在这两次操作中间有客户端C的write操作将数据x更新为了1。
但是,在写操作还在进行的时候,如果读操作返回的值会来回的跳变,即某次读请求返回的是旧值,而某一次又返回的是新值,这对于一个可线性化系统而言是不可接受的。
为此,需要加入一个约束条件,如下图所示:
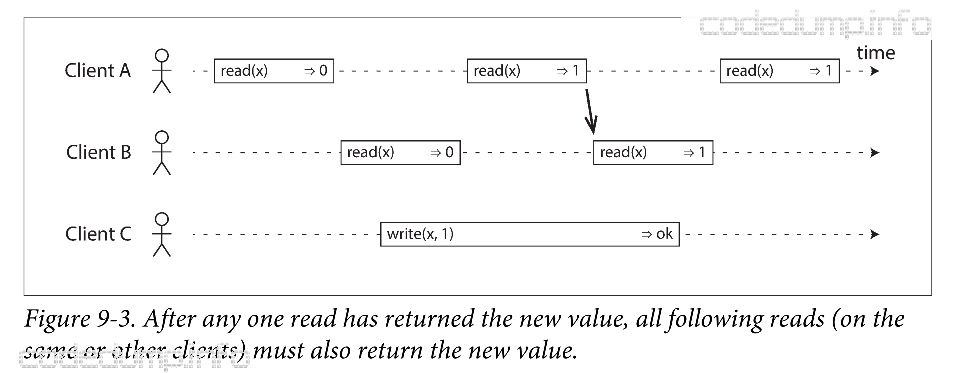
在上图中,箭头表示时序依赖关系。即现有客户端A的第二次read(x)操作,再有客户端B的第二次read(x)操作。客户端A的第二次读请求返回了x的新值1,而客户端B在这次读请求之后也去读x的值,此时应该返回的也是新值1。
即:在一个可线性化的系统中,有一个很重要的约束条件,在写操作开始和结束之间必然存在一个时间段,此时读到x的值会在旧值与新值之间跳变。但是,如果某个客户端的读请求返回了新值,那么即使这时写操作还未真正完成,后续的所有读请求也应该返回新值。
以下的例子进一步解释可线性化的操作,除了读写之外又引入另一种操作:
- cas(x, old, new):表示一次原子的比较-设置操作(compare-and-set,简称CAS),如果此时x的值为old,则原子设置这个值为new;否则保留原有值不变,这个操作的返回值表示这次x原有的值是否为old,即设置操作是否发生。
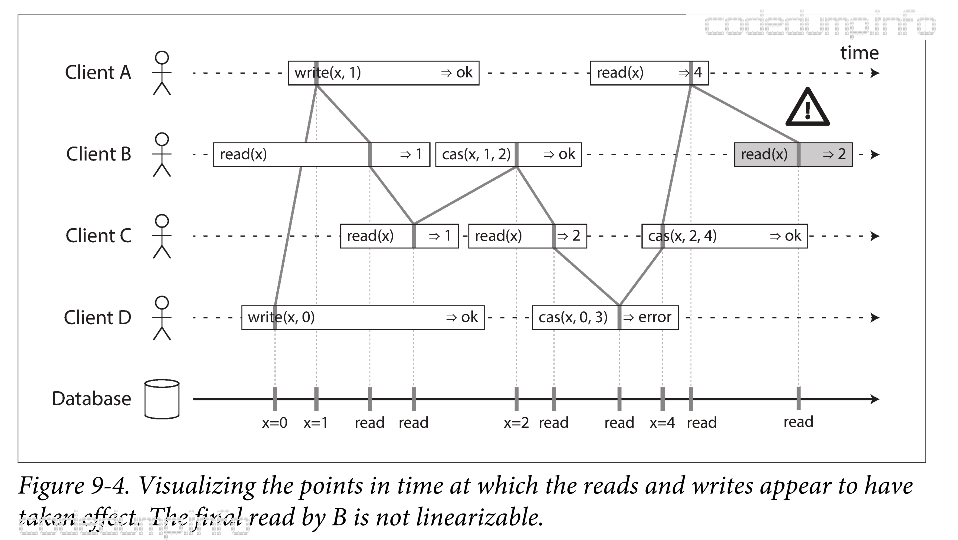
上图中的每个操作都有一个竖线,表示可能的执行时间点。可线性化要求,连接这些标记的竖线,必须总是按时间(即从左到右)向前移动,而不能向后移动。因此,一旦新值被写入或读取,所有后续的值读到的都是新值,直到被覆盖。
在上图中,有一些细节需要注意:
- 客户端B首先read(x),接下来客户端D write(x,0),然后客户端A在write(x,1),而最终返回给客户端B的值是1(客户端A写入的值)。这个结果是可能的,这意味着数据库执行的顺序是:先处理客户端D的写请求,然后是A的写入操作,最后才是B的读请求。虽然这个顺序并不是上面请求的顺序,但是考虑到请求有网络延迟的情况,比如可能B的请求延迟很大,导致在两次写请求之后才打到数据库,因此只能返回最后A写入的值。
- 客户端A在收到写请求的应答之前,B就收到了新的值1,这表明写入成功。这也是可能的,这并不意味着B的读请求在A的写请求之前发生,只是意味着由于网络延迟等原因导致A稍后才收到响应。
- 客户端的最后一次读取不满足线性化。因为在此之前,A已经读到了由C进行cas(x,2,4)操作设置的新值4,B的最后一次读请求在A读取到4之后,因此B不能读到旧值2了。
线性化的依赖条件 #
实现线性化系统 #
由于线性化本质上意味着“表现的好像只有一个数据副本,其上的操作都是原子操作”。系统最
顺序保证 #
因果关系对所发生的事件施加了某种顺序:发送消息先于收到消息,问题出现在答案之前等。
如果系统满足因果关系所规定的顺序,称之为“因果一致性(causally consistent)”。
因果顺序并非全序 #
全序关系(total order)支持任何两个元素之间进行比较,即对于任意元素,总是可以指出哪个大哪个小。
但是有些集合并不符合全序关系,例如集合{a,b}大于集合{b,c}么?因为它们都不是对方的子集,所以无法直接进行比较。这种情况称之为不可比较(incomparable),数学集合只能是偏序关系(partially ordered)。
全序和偏序的差异也体现在数据库一致性问题中:
- 可线性化:在一个可线性化的系统中,存在全序操作关系。系统的行为好像就只有一个数据副本,且每个操作都是原子的,这意味着任何两个操作,都可以指出操作的先后顺序来。
- 因果关系:如果两个操作都没有发送在对方之前,那么两个操作是并发关系(concurrent)。即,如果两个事件是因果关系,那么这两个事件就可以被排序;而并发的事件则无法排序比较。因此因果关系是偏序,而非全序。
根据上面的定义,在可线性化的系统中不存在并发操作。
可线性化强于因果一致性 #
可线性化意味着一定满足因果关系,任何可线性化的系统一定能够正确满足因果关系。
在许多情况下,系统只要能够满足因果一致性就足够了,可线性化的代价太高。
序列号排序 #
可以使用序列号或时间戳来排序事件。时间戳不一定来自物理时钟,可以只是逻辑时钟。
在主从复制数据库中,复制日志中可以定义与因果关系一致的写全序关系,即由主节点为每个操作递增计数器,从而系统中的每个操作都赋值一个单调递增的序列号。
但是如果系统中不存在唯一的主节点,比如是多主或无主类型的数据库,可以采用以下的方式:
- 每个节点独立生成自己的一组序列号,比如两个节点一个节点生成奇数,另一个节点生成偶数。另外还可以在序列号中加入所属节点的唯一标识,确保不同的节点用于不会生成相同的序列号。
- 可以把时间戳信息(物理时钟)加到每个操作上。
- 可以预先分配序列号的区间范围。
Lamport时间戳 #
如下图所示,每个节点都有唯一的标识符,且每个节点都有一个计数器来记录自己处理的请求总数,Lamport时间戳是一个值对:(计数器,节点ID),这样就能确保每个Lamport时间戳都是唯一的。
给定两个Lamport时间戳,可以这样来对比得到全序关系:计数器大的时间戳大,如果计数器相同,那么节点ID大的时间戳更大。
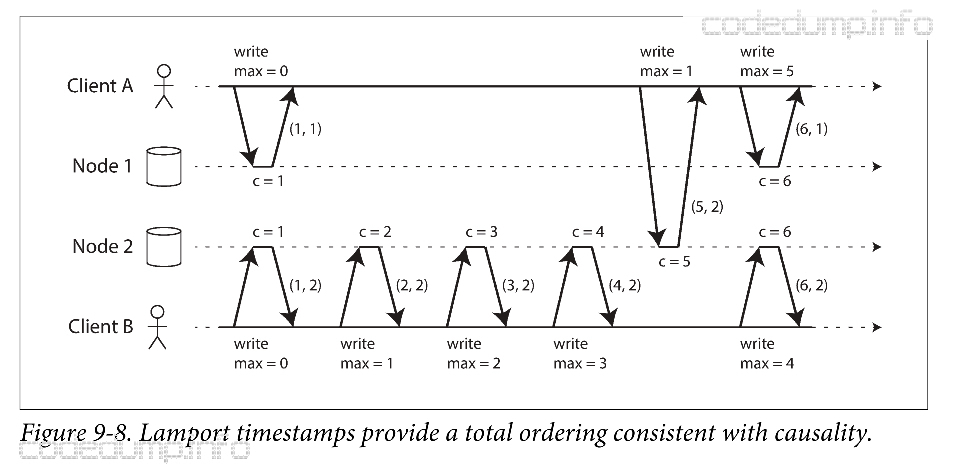
Lamport时间戳与版本向量的区别在于:版本向量用于区分两个操作是并发的还是因果依赖的,而Lamport时间戳用于确保全序关系。即使Lamport时间戳不能用于区分两个操作属于并发关系,还是因果依赖关系。
但是,即便有了全序的时间戳排序,有一些问题仍然无法解决。
比如注册一个网站时,要求用户名需要唯一,虽然两个同样名字的创建用户请求过来,可以根据全序关系来决定究竟哪个请求在先抢占了这个用户名,但是这并不够,因为这个是在请求写入之后才进行的判断,在应答写请求时无法立刻知道结果,因为还需要查询所有节点,如果有节点失败的情况下还需要等待,等等。
为了解决类似的问题,就需要引入”全序关系广播“这个概念了。
全序关系广播(Total Oder Broadcast) #
全序关系广播指节点间交换消息的某种协议,要求满足以下两个基本安全属性:
- 可靠发送:没有消息丢失,如果消息发送到了一个节点,也必须要发送到其他节点。
- 严格有序:消息总是以相同的顺序发送给每个节点。
分布式事务与共识 #
两阶段提交(two-phase commit,简称2PC) #
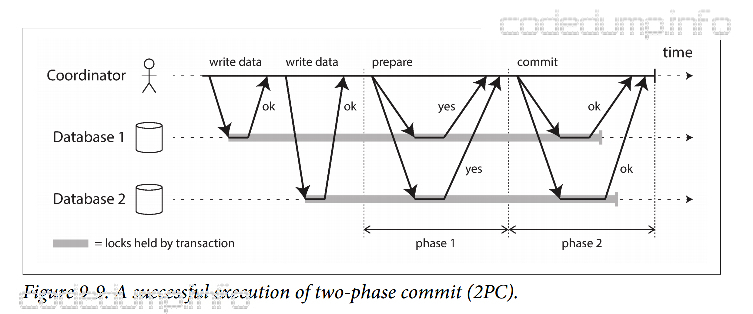
以上是简单的2PC的操作示意图,图中引入了一个协调者(Coordinator)的角色。当应用程序开始提交事务时,协调者开始阶段1:发送一个准备请求给事务中的参与者,询问是否可以提交。协调者然后跟踪参与者的回应:
- 如果所有参与者都应答”是“,表示它们已经准备好提交,协调者接下来在阶段2发出提交请求,提交才开始执行。
- 如果任何参与者回答了”否“,则协调者在阶段2中向所有节点发送放弃请求。
如果参与者在2PC期间失败,那么协调者将中断事务提交;如果在第二阶段发送提交时失败,协调者将无限期重试。
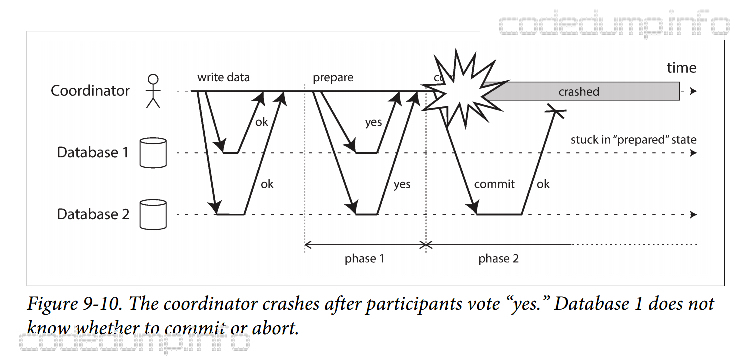
但是,如果是协调者自身发生了故障,后面的行为无法预计,如下图所示。
支持容错的共识算法 #
所有支持容错的共识算法都有以下的性质:
- 协商一致性(Uniform agreement):所有的节点都接受相同的决议。
- 诚实性(Integrity):所有节点都不能反悔,即对一项决议不能有两次不同的结果。
- 合法性(Validity):如果决定了v值,则v一定是某个节点所提议的。即:不能有一个凭空的决议产生。
- 可终止性(Termination):节点如果不崩溃则最终一定可以达成协议。
协商一致性和诚实性属性定义了共识算法的核心思想:决定一致的结果,而一旦决定就不能再变更决定。 有效性属性排除了无意义的方案。
如果不考虑容错性,以上三点很容易实现:强行指定某个节点为”独裁者“,由它做出所有的决定。但是,如果该节点失败,系统就无法再继续做出任何决定。这就是在2PC时看到的:如果协调者失败了,那些处于不确定状态的参与者无从知道应该怎么做。
可终止性引入了容错的思想。它强调一个共识算法不能原地空转,永远不做事情。即使某些节点出现了故障,其它节点也必须最终做出决定。
因此,可终止性属于一种活性属性(liveness property),而其它三个性质属于安全性方面的属性。
任何共识性算法,都需要至少大部分节点正确运行才能保证终止性,这个”大多数节点“又被称为”quorum“。
因此,可终止性的前提是,发生崩溃或者不可用的节点必须小于小半数节点。另外,共识算法也界定系统不存在拜占庭错误。
共识算法与全序广播 #
共识算法一般都是:决定了一系列值,然后采用全序关系广播算法传播数据。
全序广播的要点是:消息按照相同的顺序发送到所有节点,有且只有一次。
所以,全序广播算法相当于持续的多轮共识:
- 由于协商一致性,所有节点决定以相同顺序发送相同的消息。
- 由于诚实性:消息不能重复。
- 由于合法性,消息不能被破坏和捏造。
- 由于可终止性,消息不能丢失。
主从复制与共识 #
主从复制,也是所有写入操作由主节点负责,并以相同顺序发送到从节点来保持副本数据更新,为什么那时候没有考虑共识问题?
如果主节点由人手动选择和配置,那就是一个独裁性质的一致性算法,出现故障的时候需要人工干预。
然而,共识算法由需要首先选择出一个主节点来,否则会出现脑裂问题。如何选举主节点呢?
epoch和quorum #
共识算法中,每个协议会定义一个世代编号(epoch number),这个编号是递增唯一的,对应于paxos中的ballot number、vsp中的view number、raft中的term number。
当主节点失效时,马上进行一轮新的投票来选举出新的主节点。选举会赋予一个单调递增的epoch号,如果出现不同的主节点,那么就看谁的epoch号更大的胜出。
在主节点做出任何决定之前,必须首先检查是否存在比它更高的epoch号,如何检查呢?基于前面做分布式系统的一个准则”真理由多数决定“,节点不能依靠自己掌握的信息来决策,而应该从quorum节点中收集投票。节点只有当没有发现更高epoch的主节点存在的情况下,才会对当前的提议进行投票。
因此实际上这里是两轮不同的投票:首先投票决定谁是主节点,然后是对主节点的提议进行投票。
投票过程看起来像2PC,区别在于:2PC的协调者不是依靠选举产生;另外共识算法只需要收到quorum节点的应答就可以通过决议,而2PC需要所有参与者都通过才能通过决议。