How to Read Code(En Version)
I wrote a document in 2019 [“How to read a source code?"] (https://www.codedump.info/post/20190324-how-to-read-code/), and now looking back, there is room for improvement in this document,so I have reorganized it on top of that.
The ability to read source code is considered to be one of the underlying fundamental programmer skills, and the reason why this ability is important is that
- inevitably need to read or take over other people’s projects. For example, researching an open source project, such as taking over a project from someone else.
- Reading good project source code is one of the important ways to learn from other people’s good experience, which I know myself.
Reading code and writing code are two not quite the same skills, the reason is that “writing code is expressing yourself, reading code is understanding others”. Because of the many projects, the authors of the project have their own style, it takes a lot of energy to understand.
I’ve been in the business for years reading the project source code in general and in detail, and have written some code analysis articles one after another, so I’ll briefly summarize my approach in this article.
the first thing:run it!
The first step to start reading a project source code, is to let the project through your own compilation and run smoothly. This is especially important.
Some projects are complex and depend on many components, so it is not easy to set up a debugging environment, so it is not always possible for all projects to run smoothly. If you can compile and run it yourself, then the scenario analysis, plus debugging code, debugging, and so on will have the basis to unfold.
In my experience, a project code, whether the debugging environment can be built smoothly, the efficiency is very different.
After running, and to try to streamline their environment to reduce the debugging process of interference information. For example, Nginx uses multiple processes to process requests. In order to debug the behavior of Nginx, I often set the number of workers to 1, so that when debugging you know which process is to be tracked.
For example, many projects are compiled with optimization options or without debugging information by default, which can be a problem when debugging, so I modify the makefile to compile to -O0 -g, which is compiled to generate a version with debugging information and no optimization.
All in all, the debugging efficiency can be improved a lot after running, but under the premise of running and trying to streamline the environment to exclude the disturbing factors.
Clearly define your purpose
Although it is important to read the project source code, not all projects need to be read from start to finish. Before you start reading, you need to be clear about your purpose: whether you need to understand the implementation of one of the modules, the general structure of the framework, the implementation of one of the algorithms, and so on.
For example, many people look at the code of Nginx, and the project has many modules, including the basic core modules (epoll, network sending and receiving, memory pooling, etc.) and modules that extend a specific function, and not all of these modules need to be understood very clearly.
- Understanding the underlying processes at the core of Nginx and the data structures.
- Understanding how Nginx implements a module.
With this general understanding of the project, all that remains is to look at the specific code implementation when you encounter a specific problem.
All in all, it is not recommended to start reading the code of a project without a purpose, as looking at it headlessly will only consume your time and enthusiasm.
Distinguish between main and branch storylines
With a clear purpose in mind, you can distinguish between main and subplots in the reading process. For example.
- For example, if you want to understand the implementation of a business logic that uses a dictionary to store data in a function, here, “how the dictionary data structure is implemented” is a side plot, and you don’t need to look deeper into its implementation.
Guided by this principle, the reader only needs to understand the external interfaces to the code of the stems, such as a class that does not need to understand its implementation, and to understand the entry and exit parameters and the role of these interfaces, treating this part as a “black box”.
By the way, in the early years, I saw a way of writing C++ in which the header file contains only the external interface declaration of a class, and the implementation is transferred to the C++ file through an internal impl class, for example.
Header file.
// test.h
class Test {
public:
void fun();
private:
class Impl;
Impl *impl_;
};
C++ file.
void Test::fun() {
impl_->fun()
}
class Test::Impl {
public:
void fun() {
// Concrete implementation
}
}
This way of writing makes the header file a lot cleaner: there are no private members or functions associated with the implementation, only the exposed interface, so the user can know at a glance what the class offers to the public.
! impl
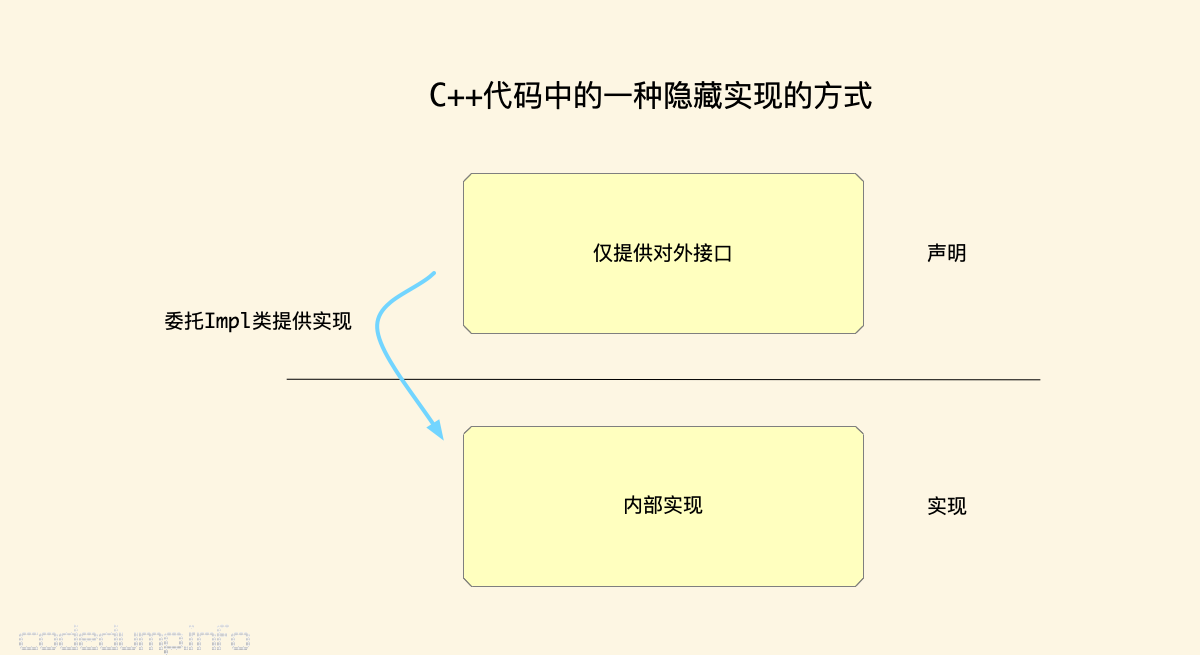{kind=link}
The “main” and “branch” storylines switch frequently throughout the code reading process, requiring the reader to have some experience in knowing which part of the code they are reading is the main storyline.
Vertical and horizontal
The code reading process is divided into two different directions.
- Vertical: Read in the order of the code. Vertical reading is often required when a specific understanding of a process or algorithm is needed.
- Horizontal: Read different modules, and often when you need to first figure out the overall framework, you need to read horizontally.
The two directions of reading, should alternate, which requires the code reader to have some experience and be able to grasp the current direction of code reading. My advice is: the process still puts the whole first, and do not go too deep into a particular detail without understanding the overall premise. Consider a function or data structure as a black box, know their input and output, as long as it does not affect the understanding of the whole, then put it aside and move on.
Scenario analysis
If you have the previous foundation, you have been able to make the project run smoothly in your own debugging environment, and you have clarified the functions you want to understand, then you can do a scenario analysis of the project code.
The so-called “scenario analysis” is to construct some scenarios by yourself, and then analyze the behavior in these scenarios by adding breakpoints and debugging statements.
For example, when I wrote Lua Design and Implementation, I explained the process of interpreting and executing Lua virtual machine instructions, and needed to analyze each instruction, so I used scenario analysis. I would simulate the Lua script code that uses the instruction, and then breakpoint in the program to debug the behavior in these scenarios.
My usual approach is to add a breakpoint to an important entry function, then construct debugging code that triggers the scenario, and when the code stops at the breakpoint, observe the behavior of the code by looking at the stack, variable values, and so on.
For example, in Lua interpreter code, generating Opcode will eventually call the function luaK_code, so I’ll add a breakpoint above this function and construct the scene I want to debug, and as soon as I break at the breakpoint, I’ll see the complete call flow through the function stack: ``C
(lldb) bt
* thread #1: tid = 0xb1dd2, 0x00000001000071b0 lua`luaK_code, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
* frame #0: 0x00000001000071b0 lua`luaK_code
frame #1: 0x000000010000753e lua`discharge2reg + 238
frame #2: 0x000000010000588f lua`exp2reg + 31
frame #3: 0x000000010000f15b lua`statement + 3131
frame #4: 0x000000010000e0b6 lua`luaY_parser + 182
frame #5: 0x0000000100009de9 lua`f_parser + 89
frame #6: 0x0000000100008ba5 lua`luaD_rawrunprotected + 85
frame #7: 0x0000000100009bf4 lua`luaD_pcall + 68
frame #8: 0x0000000100009d65 lua`luaD_protectedparser + 69
frame #9: 0x00000001000047e1 lua`lua_load + 65
frame #10: 0x0000000100018071 lua`luaL_loadfile + 433
frame #11: 0x0000000100000eb9 lua`pmain + 1545
frame #12: 0x00000001000090cd lua`luaD_precall + 589
frame #13: 0x00000001000098c1 lua`luaD_call + 81
frame #14: 0x0000000100008ba5 lua`luaD_rawrunprotected + 85
frame #15: 0x0000000100009bf4 lua`luaD_pcall + 68
frame #16: 0x00000001000046fb lua`lua_cpcall + 43
frame #17: 0x00000001000007af lua`main + 63
frame #18: 0x00007fff6468708d libdyld.dylib`start + 1
The advantage of scenario analysis is that instead of looking for a needle in a haystack, you can narrow down the problem to a scope and understand it.
The concept of “scenario analysis” is not a term I came up with. For example, there are several books that analyze code, such as Linux Kernel Source Code Scenario Analysis, Windows Kernel Scenario Analysis, and Windows Kernel Scenario Analysis. Windows Kernel Scenario Analysis”](https://book.douban.com/subject/3715700/).
Make use of good test cases
Good projects come with a lot of use cases, examples of this type are: etcd, a few open source projects produced by google.
If the test cases are written very carefully, then it is worthwhile to study them. The reason is: test cases are often for a single scenario, alone to construct some data to verify the process of the program. So, like the previous “scenario analysis”, it’s a way to move you from a big project to a specific scenario.
Clarify the relationship between core data structures
Although it is said that “programming = algorithm + data structure”, my experience in practice is that data structure is more important.
Because the structure defines the architecture of a program, there is no concrete implementation until the structure is set. Like building a house, the data structure is the framework structure of the house, if a house is very large, and you do not know the structure of the house, will be lost in it. As for the algorithm, if it is a part of the details that you do not need to delve into for the time being, you can refer to the previous section “Distinguishing the main and branch storylines” to understand the entrance and exit parameters and their roles first.
Linus says: “Bad programmers care about code. Good programmers care about data structures and how they relate to each other.”
Therefore, when reading a piece of code, it is especially important to clarify the relationships between the core data structures. At this time, it is necessary to use some tools to draw the relationship between these structures. There are many such examples in my source code analysis class blogs, such as Notes on Reading Leveldb Code, Implementation of Etcd Storage, and so on.
It should be noted that there is no strict sequential relationship between the two steps of scenario analysis and clarifying the core data structure; it does not have to be something first and then something else, but rather interactively.
For example, if you have just taken over a project and need to understand the project briefly, you can first read the code to understand what core data structures are available. Once you understand it, if you are not sure about the process in certain scenarios, you can use scenario analysis. In short, alternate until your questions are answered.
Ask yourself more questions
The learning process cannot be separated from the interaction.
If reading code is just an input, then there needs to be an output. Only simple input is like feeding something to you, and only better digestion can become your own nutrition, and output is an important means to better digest knowledge.
In fact, this idea is very common, for example, students need to do practice assignments (Output) in class (Input), such as learning algorithms (Input) need to practice their own coding (Output), and so on. In short, output is a kind of timely feedback in the learning process, and the higher the quality, the more efficient the learning.
There are many means of output, and when reading the code, it is more recommended to be able to ask yourself more questions, such as.
- Why did you choose this data structure to describe this problem? How are other projects designed in similar scenarios? What data structures are there to do such a thing?
- If I were to design such a project, what would I do?
And so on and so forth. The more active and positive thinking you do, the better output you will have, and the quality of output is directly proportional to the quality of learning.
Write your own code reading notes
Since I started blogging, I have been writing code reading articles for various projects, and my screen name “codedump” also comes from the idea of trying to “dump the code internal implementation principle”.
As mentioned earlier, the quality of learning is directly proportional to the quality of output, which is my own deep experience. Because of this, I insist on writing my own analysis notes after reading the source code.
Here are a few things to keep in mind when writing these kinds of notes.
Although they are notes, imagine that you are explaining the principles to someone who is less familiar with the project, or imagine that you are looking back at the article months or even years later. In this case, try to organize the language as well as possible and explain it in a step-by-step manner.
Try to avoid posting large paragraphs of code. I think it’s a bit self-defeating to post large paragraphs of code in such articles: it just looks like you understand it, but you don’t. If you really want to explain a piece of code, you can use pseudo-code or reduced code. Remember: don’t kid yourself, really get it. If you really want to add your own comments to the code, one suggestion I have is to fork a copy of some version of the project and commit it to your own github, where you can always add your own comments and save the commit. For example, my own commented code for etcd 3.1.10: etcd-3.1.10-codedump, similarly other projects I read will fork a project on github with codedump suffix of the project.
Draw more diagrams, a picture is worth a thousand words, use graphics to show the relationship between the code flow, data structures. I just recently discovered that the ability to draw diagrams is also an important ability, and I’m learning how to use images to express my ideas from scratch.
Writing is an important foundational ability, and a friend of mine recently educated me to the effect that if you are strong in something, if you add good writing and good English, then it will greatly amplify your ability in that area. And similar to writing, English such as the underlying basic ability, not a handful, need to keep practicing for a long time to be able to. And writing a blog, for technical staff, is a good means to exercise writing.
PS: If many things, you then do when you can think of the future to face the output of the person is your own, such as their own written code to maintain the back of their own articles written for their own eyes, and so on, the world will be much better. For example, writing a technical blog about these things, because I am writing when I consider that the person who will look at this document may be myself, so when writing will try to be clear and easy to understand, trying to see myself after a period of time when I see their own document, I can immediately recall the details of the time, but also because of this, I rarely post large sections of code in the blog, as far as possible to supplement the legend.
Summary
The above is my brief summary of some of the means and methods of attention when reading source code, in general there are so many points, right?
- Only better output can better digest the knowledge, the so-called build debugging environment, scenario analysis, ask yourself more questions, write code reading notes, etc. are all around the output to start. In short, you can’t be like a dead fish and expect to fully understand its principles just by reading the code, you need to find ways to interact with it.
- Writing is one of the basic hard skills of a person, not only to exercise their ability to express themselves, but also to help organize their thoughts. One means of exercising writing skills for programmers is to write a blog, and the sooner you start exercising, the better.
Finally, as with any skill that can be acquired, the ability to read code requires long hours and lots of repetition, so next time start working on a project that interests you.