概述 #
之前大体了解了B、B+ tree算法的实现原理:
但是对于生产环境里的具体实现还有很多疑问,具体有:
- 算法中演示的数据都是简单的、定长的数据,实际环境中数据不定长,甚至超过了一个页面的存储,这种情况下如何存储数据?
- 页面中随着数据的删除会有很多空闲空间,页面的分配以及页面内空闲空间是如何利用起来的?
- 线上的系统肯定要做容灾、恢复处理,这部分又是怎么实现的?
- …
在我查找各种资料之后,发现了madushadhanushka/simple-sqlite: Code reading for sqlite backend这个项目,该项目将sqlite 2.5版本b-tree相关的代码抽取出来,同时也写了对应的demo代码,抽取出来的代码量不过几千行。虽然2.5版本距离现在已经有较长的时间了,但是以这个项目为出发点了解生产级b-tree的实现仍不失为一个好的出发点。
本文中就这个项目的实现做一些解析,回答上面提出的几个问题在该项目中都是如何实现的,文中不再详细阐述算法的原理,有疑问可以回到上面两篇博文看看。
项目中只抽取了sqlite中后端存储的部分代码,所以并不涉及到sql的解析等等,只专注在数据如何存储这个层面,具体来说sqlite的后端存储分为了三个层次:
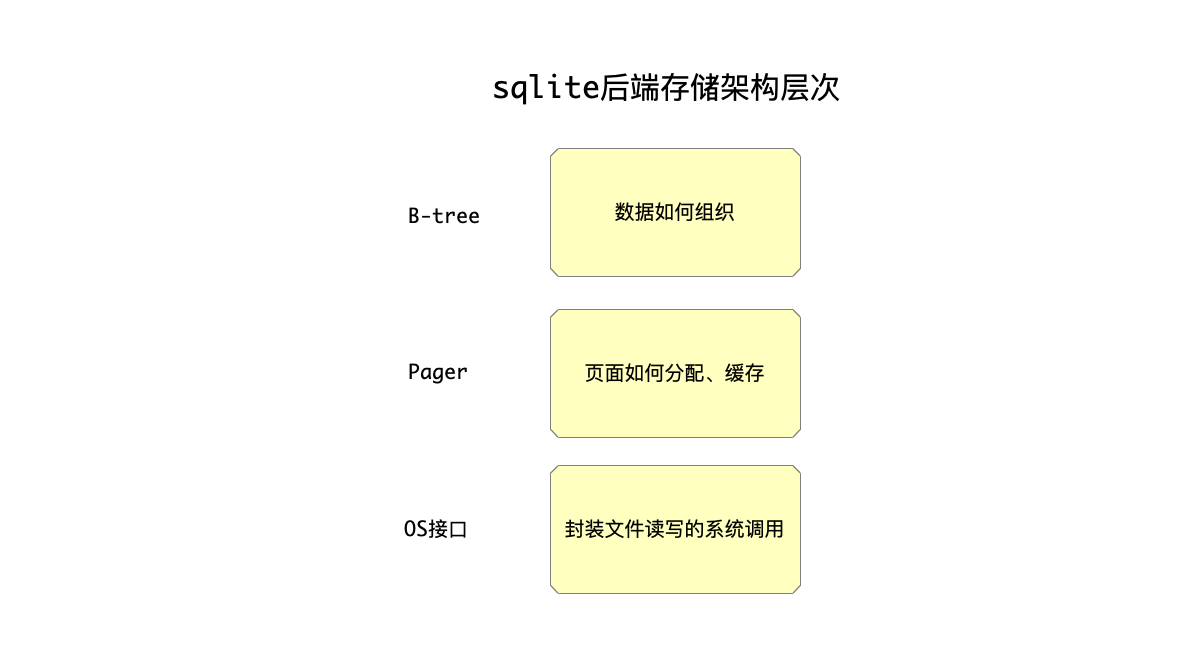
其中:
- b-tree模块:btree模块负责根据算法实现数据的组织,当需要分配新的空间保存数据时,以页面为最小单位调用Pager接口来分配(页面大小默认为1024KB)。
- Pager模块:封装页面的分配、缓存、加载、读、写等操作。
- OS模块:封装了操作系统层面对文件的读写操作。
对这部分的模块划分有总体了解之后,下面展开解释。
接口 #
首先还是讲讲这部分暴露出来的接口,这些都可以在项目test目录中自带的各模块用例里看得到具体的使用。
其他几个模块相对简单,就不再这里阐述,具体看看btree模块的接口。
sqlite中的数据,都存储在一个单一的数据库文件里,并不像innodb那样一个数据库划分了一个目录。
因此,要使用它的存储,首先需要调用sqliteBtreeOpen函数打开数据库文件,用于初始化Btree结构体,该结构体代表一个数据库对象,也就是和数据库文件是一一对应的关系。
有了数据库对象之后,还要创建表,此时需要调用sqliteBtreeCreateTable创建表,如果创建成功则返回int类型的table id。
有了数据库、表的id之后,需要创建游标对象BtCursor才能对表进行操作,这里需要调用sqliteBtreeCursor函数,传入数据库对象、table id等来完成游标对象的创建。
有了游标对象,可以针对表进行各种操作,包括:
- 插入、查询、删除数据。
- 遍历表中的所有对象。
等等。
这里简单总结一下b-tree模块暴露出来的几个核心数据结构:
- Btree:数据库对象,与一个数据库文件一一对应。
- table id:int类型,与数据表一一对应。
- BtCursor:游标对象,使用数据库对象以及table id创建,使用该对象可以完成针对数据表对象的各种操作。
Pager模块 #
内存中页面的结构和维护 #
pager.c中的Pager结构体,负责维护页面缓存、加载、写入页面,具体的工作包括:
- 维护了一个当前加载到内存中的页面编号hash表,即需要加载页面时,首先根据页面编号到该hash表中查找,如果没有说明该页面没有读取到页面缓存中,需要到硬盘上加载。
- 当然不可能无限制的缓存硬盘上的页面,当页面缓存不足时,所以还有页面淘汰机制,将需要被淘汰的页面数据落盘。
- 维护当前空闲页面的列表。
- 管理journal和checkpoint文件,这两个文件与错误恢复有关。
可以看到,一个页面可能在这三种数据结构体中:
- 页面编号同hash值的页面将串联成一个链表。
- 所有加载到内存中的页面形成一个链表。
- 如果这是空闲页面,那么还会串联到空闲页面链表中。
每一个加载进入内存中的页面数据,由以下三部分构成:
PgHdr结构体定义的页面元数据信息。- 硬盘上页面数据读取到内存中的内容,其大小与一个页面的大小相同,页面大小由宏
SQLITE_PAGE_SIZE指定,默认值为1024。 - 页面的额外(extra)数据,这部分空间暂时还不知道有什么用,可以在创建数据库时指定为0。
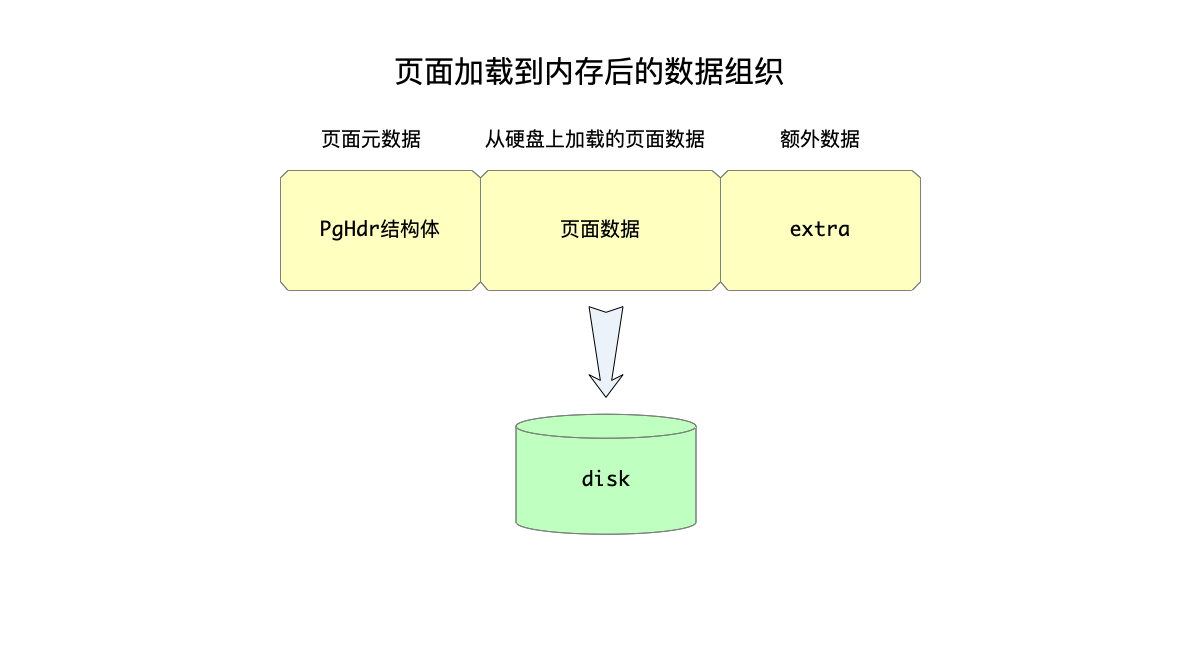
其中,PgHdr结构体有以下信息:
- 上面提到,一个页面在三种链表中(hash桶链表、内存页面链表、空闲页面链表),所以数据结构中就需要这三种链表的指针。
- 页面编号,这样知道该页面对应硬盘上哪个位置的数据。
- 是否脏页面,这意味着是否需要把该页面的数据落盘。
- 引用计数。
- 是否为journal(inJournal)和checkpoint(inCkpt)页面。
对加载到内存中的数据组织有所了解之后,就不难理解以下三个宏的作用:
// 内存中页面空间的分布是:PgHdr+硬盘页面空间+extra空间
// 根据页面header指针拿到硬盘页面空间的起始位置
#define PGHDR_TO_DATA(P) ((void*)(&(P)[1]))
// 根据内存中硬盘页面空间的起始位置拿到页面header指针
#define DATA_TO_PGHDR(D) (&((PgHdr*)(D))[-1])
即:
- PGHDR_TO_DATA:这个宏可以根据内存地址得到页面在内存中的首地址。
- DATA_TO_PGHDR:这个宏可以根据页面在内存中的首地址得到
PgHdr指针。
Journal文件管理 #
Journal文件用于数据恢复、回滚等操作。其原理是:每次写入数据时,将该页面当时的数据写入Journal文件,当需要回滚、恢复时,直接将保存在Journal中的内容覆盖原页面内容即可。

如上图中,每次修改数据时,有如下的顺序:
- 判断所修改页面是否已经在这一轮修改中将原始页面内容写入journal文件,如果有则忽略,没有则写入。
- 进行页面的修改,此时并不需要将这一修改马上在数据库文件中落盘。
- 当所有修改都完成之后,统一将数据库文件中页面的修改落盘,此时journal文件也可以清除了。
- 数据库启动后,第一次分配页面时,会判断是否当前存在journal文件内容,需要以此内容首先进行恢复操作。
这里的几个问题是:
问题一:每次页面修改都要写入journal文件,会不会太消耗了?我的看法是这个备份是以页面为单位的备份,而且一轮修改中只会备份同一个页面一次,所以还是可以接受的。
问题二:如果写入的时候进程退出,那岂不是所有的修改都会丢失?是的,所以这里需要类似wal的机制,首先保存这个写入操作。这样一份完整的数据就等于数据库文件+journal文件+wal文件。即恢复的时候,依照以下顺序来做:
- 读取数据库文件。
- 使用journal文件恢复崩溃时没有落盘页面修改之前的内容。
- 重放wal文件,将前面没有做的修改再做一遍。
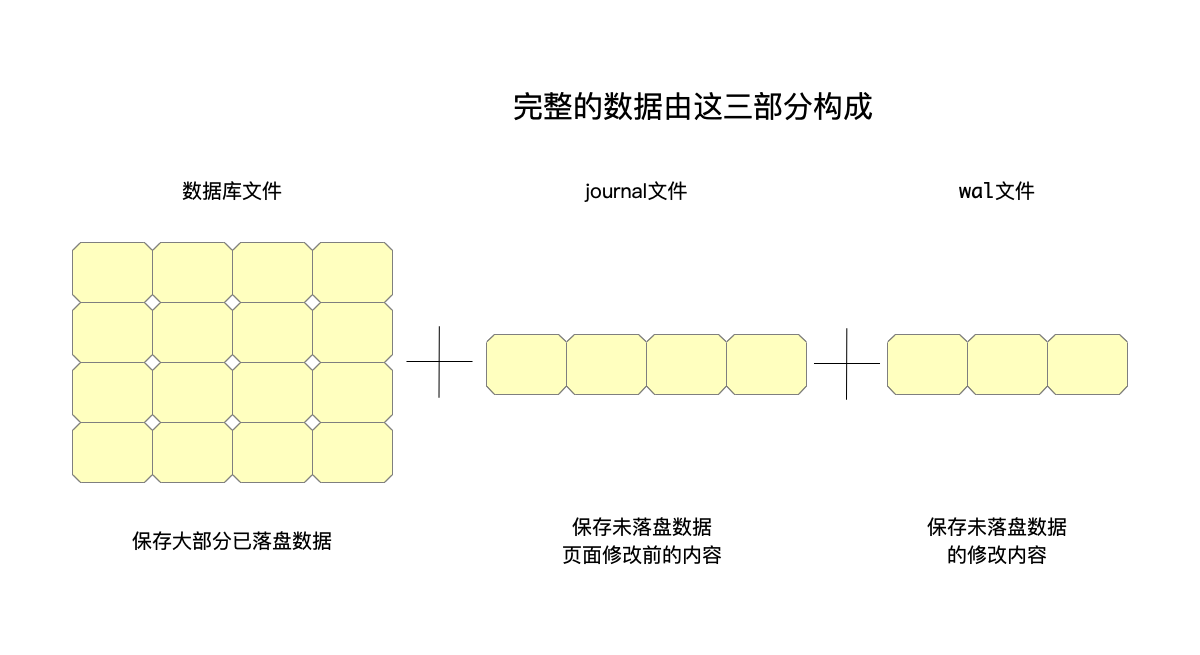
以一个例子来说明问题:
- 假设现有的数据为(k,1),(v,2),其中二元组第一个数据为key,第二个数据为value。
- 此时一个事务需要修改为(k,3),(v,4),将按照下面的顺序进行:
- 向wal中写入修改(k,3),(v,4)的操作。
- 在journal文件保存k、v所在页面的内容,即保存下来的数据为(k,1),(v,2)。
- 修改页面中(k,3),(v,4)。
- 修改完毕之后,事务提交,这会提交页面的修改,同时journal文件和wal文件的内容也无用了。
假设上面的事务只修改了(k,3),而(v,4)的修改还未落盘进程就退出了,那么恢复的流程如下:
- 首先读取数据库文件,此时因为只修改了一个值,读取出来的数据为(k,3),(v,2)。
- 使用journal文件来恢复未落盘页面修改之前的内容,即恢复之后的数据为(k,1),(v,2)。
- 重放wal中的修改操作,这就又走一遍上面的修改流程。
了解了以上的流程,可以来看一下Pager中如何实现journal文件备份的。
Pager中使用位图来保存哪些页面已经被写入journal文件了:
u8 *aInJournal; /* One bit for each page in the database file */
pPager->aInJournal[pPg->pgno/8] |= 1<<(pPg->pgno&7);
即:aInJournal是一个数组,其每个元素是个8位的整数,保存时将计算页面编号所在的数组位置保存在这8位整数的哪一位。
而journal文件的结构也很简单,如下图:
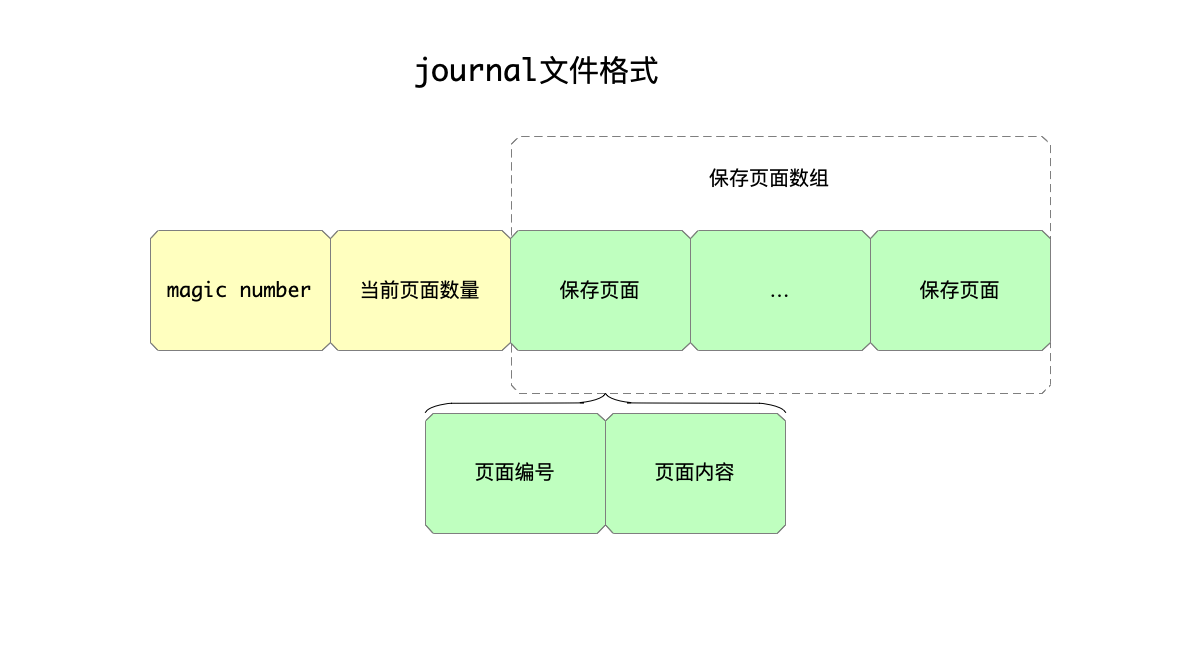
内容依次包括:
- aJournalMagic。
- 当前数据文件中的页面数量。
- 最后一个保存页面内容的数组,数组中每个成员为(页面编号,页面内容)的二元组,代码中用了
PageRecord这个结构体来定义这部分结构。由于页面的大小是定长的,所以这里每个成员的大小是定长的。
小结 #
以上,已经大致了解了sqlite 2.5版本如何管理页面的,总结起来:
- 页面是数据库管理数据库文件的基本单位。
- 加载到内存中的页面数据,由三部分组成:描述页面信息的元数据(结构体
PgHdr)、从硬盘上读取的页面数据、额外空间数据(通常为0)。 - 一个被加载到内存中的页面可能在以下三种数据结构中:
- 缓存页面数据的hash表中,加载页面时会首先到hash表中根据页面编号查找页面是否已经被加载进入内存。如果没有则需要从硬盘上加载页面数据,缓存中的页面数量超过阈值需要进行淘汰。
- 空闲页面链表,该链表上的页面都是空闲页面,当需要写入数据到新的页面中时,都首先查看是否有空闲页面可以回收利用。
- 加载到内存中的页面链表。
- sqlite使用Journal文件来保存一次改动中被修改的页面在修改之前的内容,启动时会查看如果Journal文件有内容会首先使用这些内容进行数据的恢复。
可以看到,Pager模块所有的操作都是以页面为单位来进行的,并不关心具体一行数据是如何存储的,数据的存储由btree模块实现,接下来就解释btree模块的实现。
btree模块 #
Pager模块操作的基本单位是页面,而btree模块操作数据的基本单位是Cell,即一个页面中划分为多个cell,一个cell用来保存一行数据。
数据库页面组织 #
数据库文件中一个页面的数据被划分为了以下几个部分:
- 页面头:由结构体
PageHdr定义。 - Cell链表:其中每个数组元素由结构体
Cell来定义。 - 空闲空间链表:被删除数据的
Cell空间,就变成了空闲空间,由结构体FreeBlk来定义。
把这里的结构划分和前面分析Pager模块时的单页面加载到内存后的数据组织图合并起来一起看看:
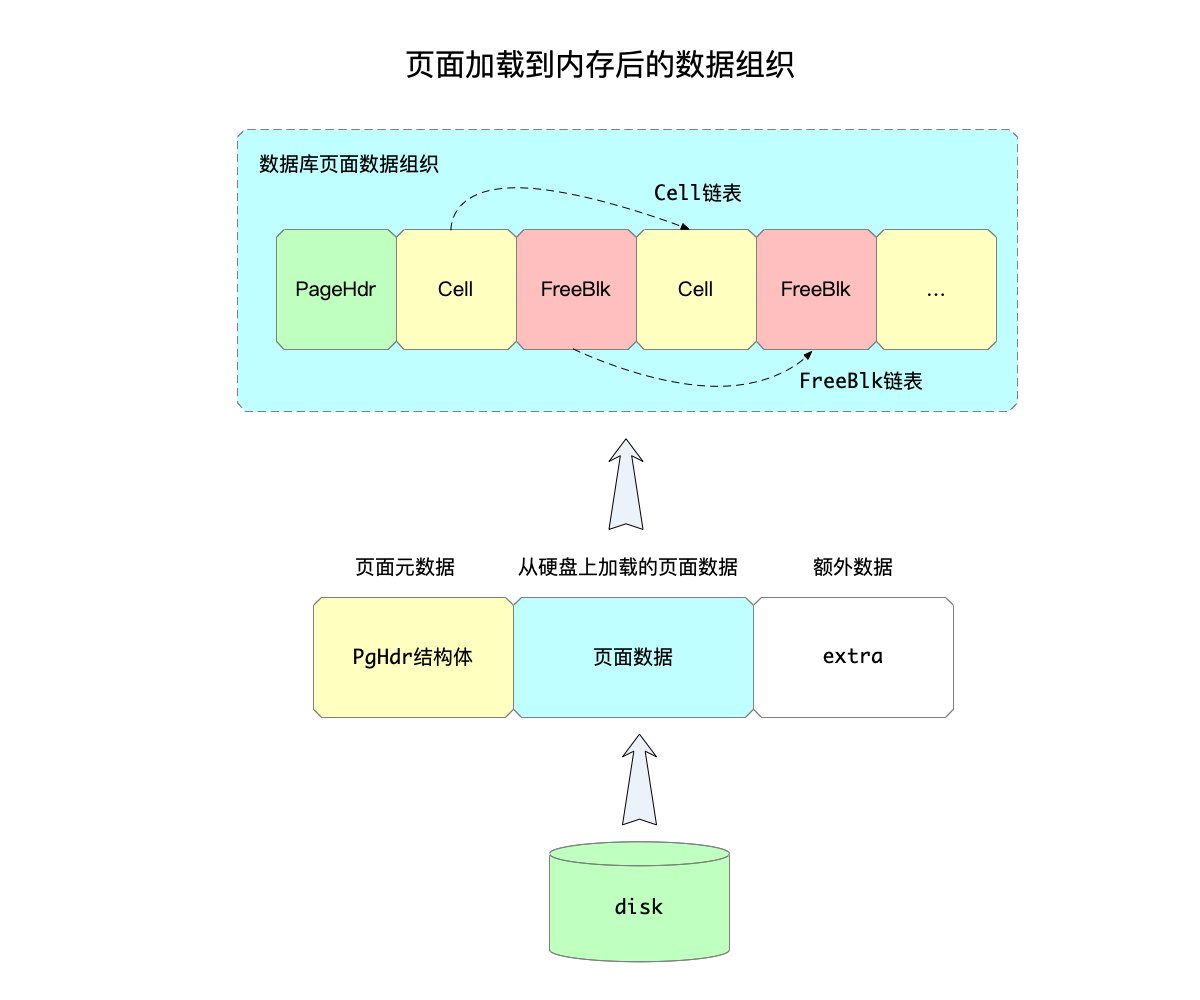
代码中把一个页面加载到内存中的数据,统一由结构体MemPage来管理:
struct MemPage {
union {
char aDisk[SQLITE_PAGE_SIZE]; /* Page data stored on disk */
PageHdr hdr; /* Overlay page header */
} u;
int isInit; /* True if auxiliary data is initialized */
MemPage *pParent; /* The parent of this page. NULL for root */
int nFree; /* Number of free bytes in u.aDisk[] */
int nCell; /* Number of entries on this page */
int isOverfull; /* Some apCell[] points outside u.aDisk[] */
Cell *apCell[MX_CELL+2]; /* All data entires in sorted order */
};
可以看到,MemPage结构体最开始部分是一个union:
union {
char aDisk[SQLITE_PAGE_SIZE]; /* Page data stored on disk */
PageHdr hdr; /* Overlay page header */
} u;
这是因为:定义了一个页面大小的char数组,这样对这个数组的操作就是直接操作页面内容;而每个页面的开始部分又都是PageHdr结构体表示的页面header,因此又可以通过该成员来操作header。除了union部分,MemPage中的其他成员都不是直接与页面内容对应的,属于页面加载进入内存之后计算得到的。
接着具体展开看这三部分的数据。
页面头信息 #
页面头信息由结构体PageHdr定义:
struct PageHdr {
Pgno rightChild; /* Child page that comes after all cells on this page */
u16 firstCell; /* Index in MemPage.u.aDisk[] of the first cell */
u16 firstFree; /* Index in MemPage.u.aDisk[] of the first free block */
};
其中:
- rightChild:页面右子树所在的页面编号。
- firstCell:cell链表的第一个元素。
- firstFree:free block第一个元素。
注意,后面两个元素的大小都是u16类型,因为这是在页面中的偏移量,所以这个类型是足够大的。
Cell #
Cell结构体的定义如下:
struct Cell {
CellHdr h; /* The cell header */
char aPayload[MX_LOCAL_PAYLOAD]; /* Key and data */
Pgno ovfl; /* The first overflow page */
};
其中:
- CellHdr:定义了cell的元信息。
- aPayload:保存cell数据的空间。
- ovfl:如果一个页面保存不了一行的数据,就称为“溢出(overflow)”,溢出的数据需要保存到溢出页面去,这个成员就是保存第一个溢出页面的页面编号。
其中CellHdr结构体的定义如下:
struct CellHdr {
Pgno leftChild; /* Child page that comes before this cell */
u16 nKey; /* Number of bytes in the key */
u16 iNext; /* Index in MemPage.u.aDisk[] of next cell in sorted order */
u8 nKeyHi; /* Upper 8 bits of key size for keys larger than 64K bytes */
u8 nDataHi; /* Upper 8 bits of data size when the size is more than 64K */
u16 nData; /* Number of bytes of data */
};
结构体成员的解释如下:
- leftChild:左子树节点的页面编号。
- nKey、nKeyHi:用于计算key部分大小。
- nData、nDataHi:用于计算data部分大小。
- iNext:用于存储cell链表上下一个cell数据在页面中的偏移量。
前面提到,有可能出现一个页面不够存储数据的情况,所以key和data的大小都分为了两部分,比如对于key来说,分为小于64Kb(存储在nKey)和大于64Kb(nKeyHi)两部分内容,这样key的大小就等于:
#define NKEY(h) (h.nKey + h.nKeyHi*65536)
类似的,也有NDATA宏,就不再解释。
另外需要说明一点,一个cell保存数据的以4字节来对齐,即如果数据小于4字节,则自动补全到4字节。有了这个数字,加上一个页面的大小、header部分的大小,就能计算出来一个页面最多容纳多少cell,以及一个页面最多有多少空间用于存储数据等等,这些都用宏组织了起来:
// cell的最小空间是cell header + 4字节
#define MIN_CELL_SIZE (sizeof(CellHdr)+4)
// 一个页面中最多cell的数量
#define MX_CELL ((SQLITE_PAGE_SIZE-sizeof(PageHdr))/MIN_CELL_SIZE)
// 可用空间 = 页面空间 - 头部固定空间
#define USABLE_SPACE (SQLITE_PAGE_SIZE - sizeof(PageHdr))
// 一个数据项最大空间,超过这部分就保存到overflow页面中
#define MX_LOCAL_PAYLOAD ((USABLE_SPACE/4-(sizeof(CellHdr)+sizeof(Pgno)))&~3)
// overflow页面能存储数据的容量
#define OVERFLOW_SIZE (SQLITE_PAGE_SIZE-sizeof(Pgno))
把上面关于cell的解释结合起来,一个cell的空间分布如下图:
FreeBlk #
FreeBlk结构体用于表示页面中的空闲块,即:如果一个cell所表示的数据被删除,则转换成了FreeBlk,FreeBlk结构体的定义很简单:
struct FreeBlk {
u16 iSize; /* Number of bytes in this block of free space */
u16 iNext; /* Index in MemPage.u.aDisk[] of the next free block */
};
成员解释如下:
- iSize:空闲块空间大小。
- iNext:下一个空闲块在页面中的偏移地址。
上面两个成员类型都是u16,由于只需要表示在一个页面内的大小和偏移量,所以是足够的。
OverflowPage #
OverflowPage结构体用于表示溢出页面,其定义如下:
struct OverflowPage {
Pgno iNext;
char aPayload[OVERFLOW_SIZE];
};
成员解释如下:
- iNext:该数据下一个overflow页面的编号(如果存在的话)。
- aPayload:存储payload空间的数组,其中宏
OVERFLOW_SIZE见上面的解释。
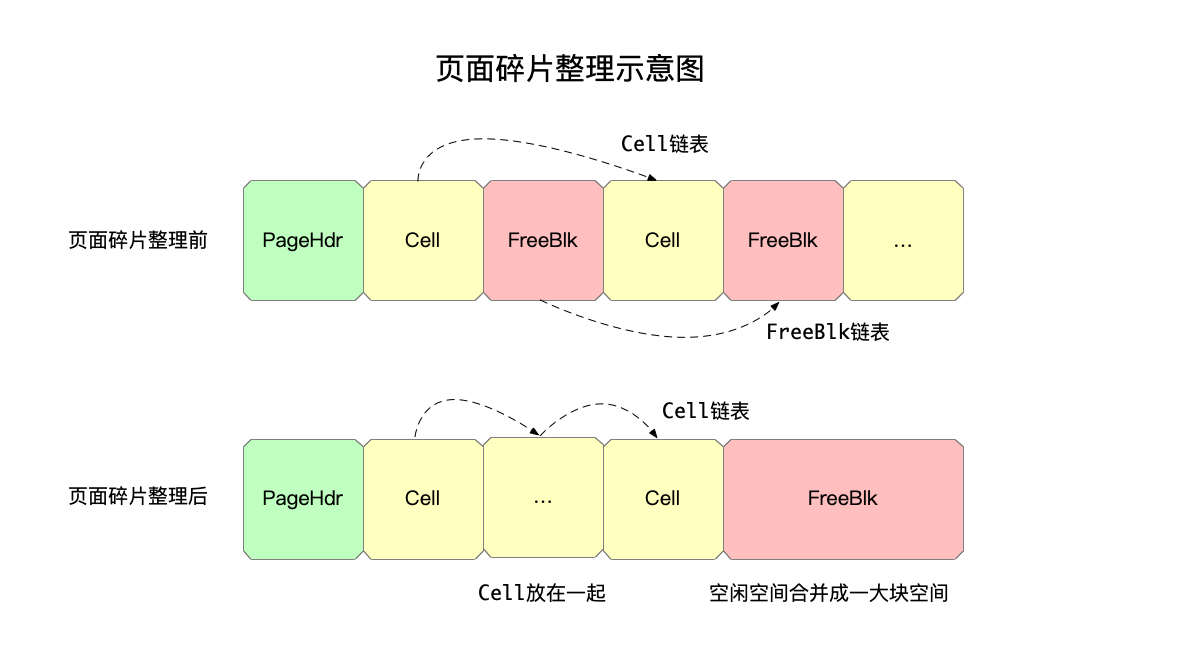
页面碎片整理 #
随着页面数据的增加、删除,页面中会出现很多碎片空间。当需要往页面新增数据时,将进行如下的检查:
- 如果页面空闲空间已经不足够,则分配一个新的页面来保存数据。
- 否则说明页面内的空闲空间足够,遍历页面的
FreeBlk链表,找到第一块适合大小的空间用来保存数据。如果这个流程没找找到合适的block,说明页面内的空间碎片化很严重,需要进行页面的碎片整理。
页面碎片整理的入口函数是defragmentPage,其原理是:
- 将所有cell的数据移动到紧跟着header之后的空间。
- 剩余空闲空间做为一块大的free block,等待下一次分配时切割出来使用。
即,碎片整理前后的示意图如下: