引言:本文使用大量的图例,同时没有难懂的公式,意图解释清楚一致性模型要解决什么问题,以及三种一致性模型:顺序一致性、线性一致性、因果一致性。
图解一致性模型 #
概述 #
解决什么问题? #
分布式系统要保证系统的可用性,就需要对数据提供一定的冗余度:一份数据,要存储在多个服务器上,才能认为保存成功,至于这里要保存的冗余数,有Majority和Quorum之说,可以参考之前的文章:周刊(第17期):Read-Write Quorum System及在Raft中的实践。
同一份数据保存在多个机器上提供冗余度,也被称为副本(replica)策略,这个做法带来下面的好处:
- 容错性:即便分布式系统中几台机器不能工作,系统还能照常对外提供服务。
- 提升吞吐量:既然同一份数据存储在多个机器上,对该数据的请求(至少是读请求)能够分担到多个副本上,这样整个系统可以线性扩容增加更多的机器以应付请求量的增加。
同时,副本策略也有自己需要解决的问题,其中最重要的问题就是一致性问题:在系统中的一个机器写入的数据,是否在系统中其他机器看来也是一样的?
很显然,即便在一切都正常工作的条件下,在系统中的一个机器成功写入了数据,因为广播这个修改到系统中的其他机器还需要时间,那么系统的其他机器看到这个修改的结果也还是需要时间的。换言之,中间的这个时间差可能出现短暂的数据不一致的情况。
可以看到,由于这个时间差的客观存在,并不存在一个绝对意义上的数据一致性。换言之,数据一致性有其实现的严格范围,越严格的数据一致,要付出的成本、代价就越大。
为了解决一致性问题,需要首先定义一致性模型,在维基的页面上,一致性模型(Consistency model)的定义如下:
In computer science, a consistency model specifies a contract between the programmer and a system, wherein the system guarantees that if the programmer follows the rules for operations on memory, memory will be consistent and the results of reading, writing, or updating memory will be predictable.
我们举一个日常生活中常见的问题来解释一致性模型:
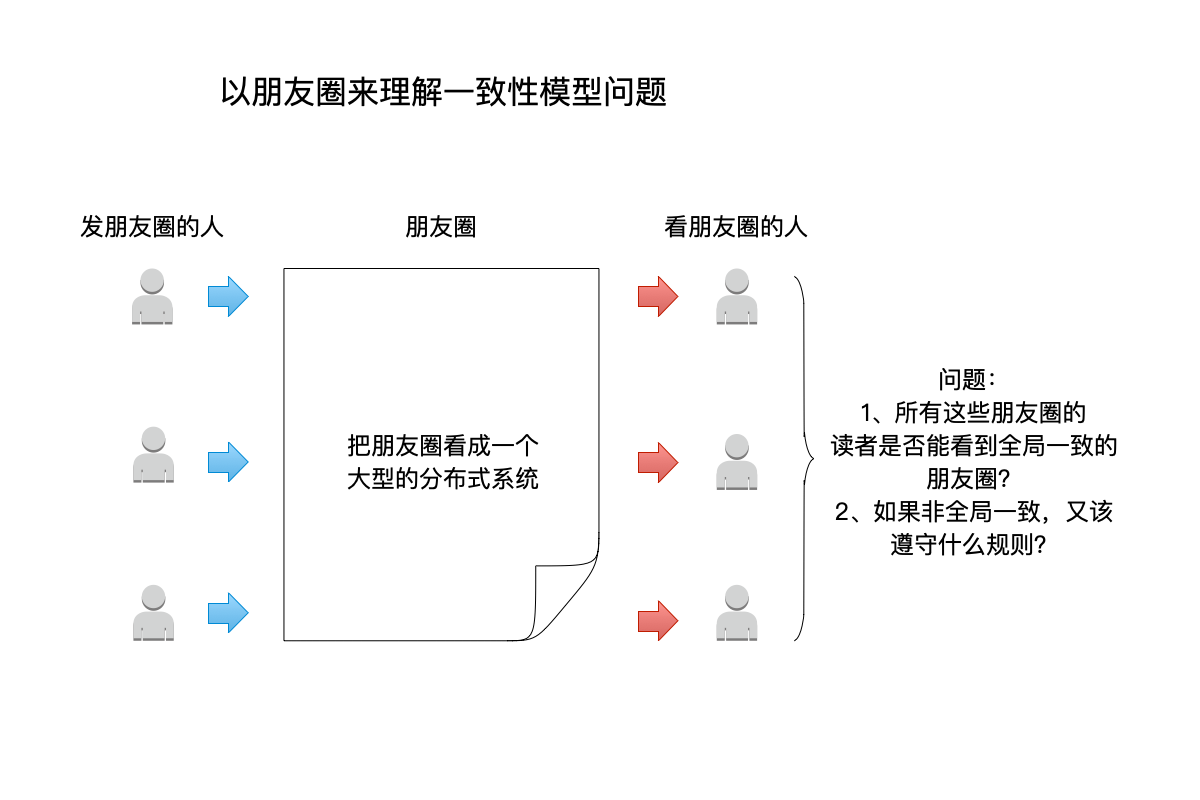
在上图中:
- 不妨把
朋友圈当成一个大型的分布式系统:- 这个分布式系统,对外提供了写入(发朋友圈)和读取( 读朋友圈)的功能。
- 存储这些朋友圈数据的,肯定不止一台机器,因此这些机器在一起构成了这个大型的分布式系统。
- 不同的用户,发朋友圈的时候,也不一定都写入相同的一台机器。反之也是,在读朋友圈时也不一定会到同一台机器上读取数据。
朋友圈这个分布式系统,有两种客户端:发朋友圈的客户端负责写入数据,读朋友圈的客户端负责读取数据,当然很多时候同一个客户端既能读也能写。
接下来的问题是:
- 这些看朋友圈的人,是否能看到全局一致的数据?即所有人看到的朋友圈都是同一个顺序排列的?
显然,有很多时候,即便是在看同一个朋友圈下的评论回复,不同的人看到也不尽然都是同一个顺序的,所以以上的答案是否定的。那么就引入了下一个问题:
- 如果不同的人看到的朋友圈(包括评论)顺序各有不同,这些顺序又该遵守怎样的规则才是合理的?
回答怎样的顺序规则才是合理的,这就是一致性模型要解答的问题。
一致性模型图例 #
本文意在使用各种图例来解释一致性模型,所以在继续往下讲解之前,有必要首先交待一下图例中的各种元素,以下图为例:
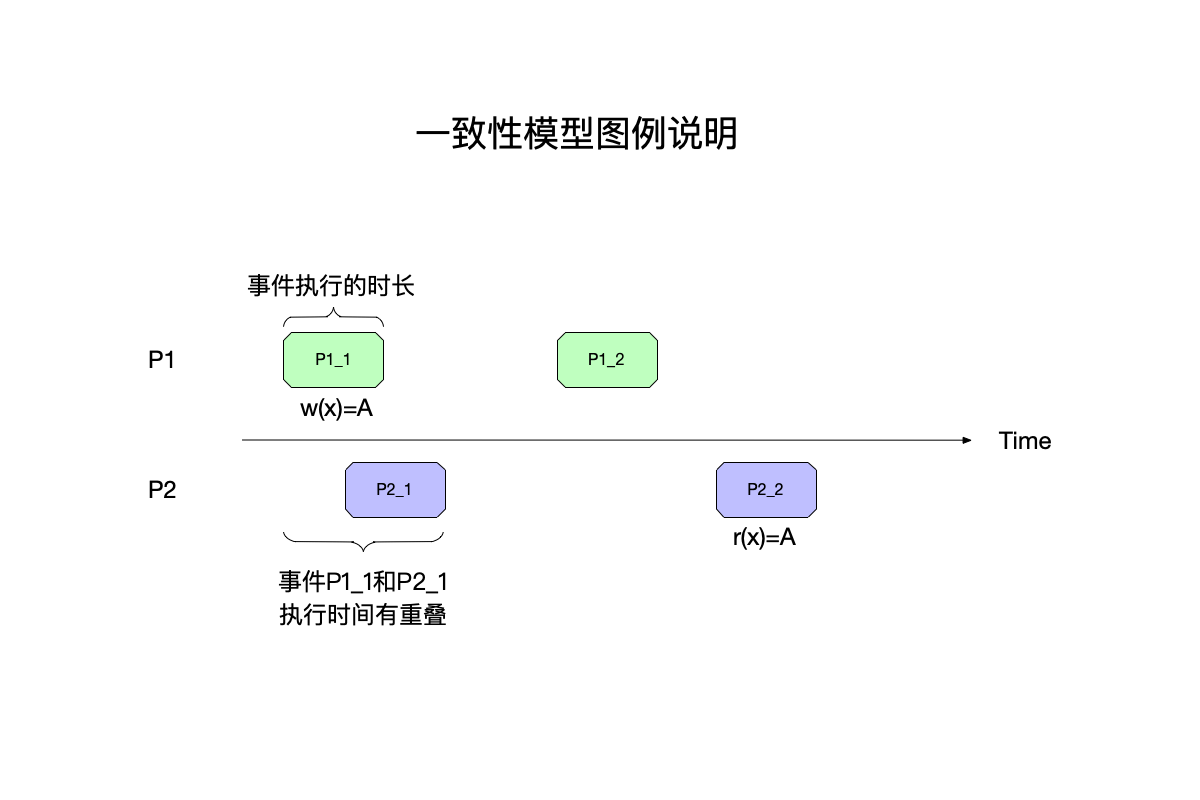
在上图中,有以下几个元素:
- 最左边是分布式系统中的进程编号${\displaystyle P_1}$、${\displaystyle P_2}$。
- 横轴是时间轴,从左往右时间递增,但是这里并没有严格的时间刻度。
- 进程中发生的事件,事件的命名规则为
进程编号_进程中的事件编号,比如${\displaystyle P_11}$,除此以外:- 事件有其开始、结束时间,使用一个矩形来表示一个事件的执行,这样矩形的宽度可以认为在时间轴上的宽度,即事件的执行时长。
- 事件与事件之间,在执行时间上可能发生重叠,如图中的${\displaystyle P_11}$和${\displaystyle P_21}$,这种有重叠的事件,被称为并发事件(concurrent event),在顺序上,并发事件之间可以认为谁先谁后都可以,后面会专门聊这部分。
- 使用不同的颜色来区分不同进程上发生的事件。
- 每个事件关联一个操作,为了简化问题目前只有读和写操作:
- w(x) = A:向变量x写入A。
- r(x) = A:从变量x读出A。
单进程下的事件排列 #
我们继续回到朋友圈的话题上来,一条朋友圈下面有多个人发表评论,可以认为这是一个二维的数据:
- 进程(也就是发表评论的人)是一个维度。
- 时间又是另一个维度,即这些评论出现的先后顺序。
但是在阅读这些评论的读者看来,需要将这一份二维的数据,去除掉不同进程这个维度,压平到只有本进程时间线这一个单一维度上面来,以上面图例来说就是这样的:
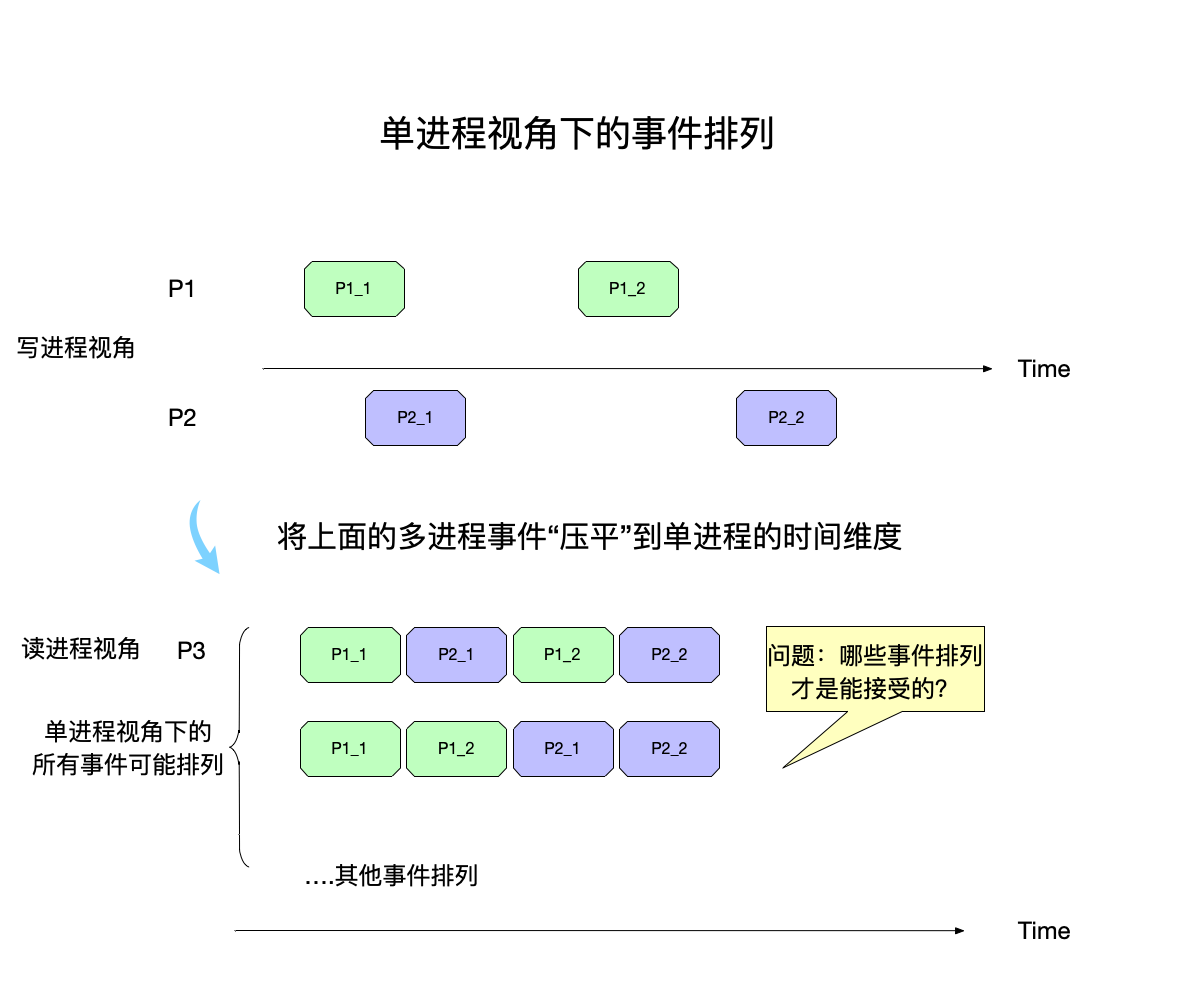
在上图中,在读进程${\displaystyle P_3}$的视角看来,两个写进程的事件,需要压平到本进程的时间线上进行排列,可以看到这些事件在压平之后有多种排列的可能性。
将多个写进程的事件进行排列,放到单进程的时间线上,这是一个排列组合问题,如果所有的写进程事件加起来一共有n个,那么这些事件的所有排列组合就是$n!$。比如事件a、b、c,不同的排列一共有这些:
{(a,b,c),(a,c,b),(b,a,c),(b,c,a),(c,a,b),(c,b,a)}
一致性模型就是要回答:在所有的这些可能存在的事件排列组合中,按照要求的一致性严格程度,哪些是可以接受的,哪些不可能出现?
后面的讲述将看到:越是宽松的一致性模型,能容纳的事件排列可能性就越多;反之越严格则越少。
一致性模型 #
本文中将讨论以下三种一致性模型:线性一致性、顺序一致性、因果一致性,上面是按照严格顺序排行的,也就是说线性一致性最严格、因果一致性则最弱。需要说明的是,还存在其它一致性模型,但是不在本文的讨论范围内。
顺序一致性 #
顺序一致性的定义最初出现在论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Progranm》中,原文中要求顺序一致性模型满足两个要求:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
(任何执行的结果都与所有处理器的操作按某种顺序执行的情况相同,每个单独的处理器的操作按其程序指定的顺序出现在这个序列中。)
它有两个条件:
Requirement Rl: Each processor issues memory requests in the order specified by its program.
Requirement R2: Memory requests from all processors issued to an individual memory module are serviced from a single FIFO queue. Issuing a memory request consists of entering the request on this queue.
先来看条件1:
- 条件1:每个进程的执行顺序要和该进程的程序执行顺序保持一致。
前面提到过,当读进程读到多进程的多个事件时,相当于把这些不同时间、进程维度的事件“压平”到本进程的同一个时间维度里,条件1要求这样被压平之后的顺序,每个进程发出的事件的执行顺序,和程序顺序(program order)保持一致。
举一个违反这个条件的反例,如下图所示:
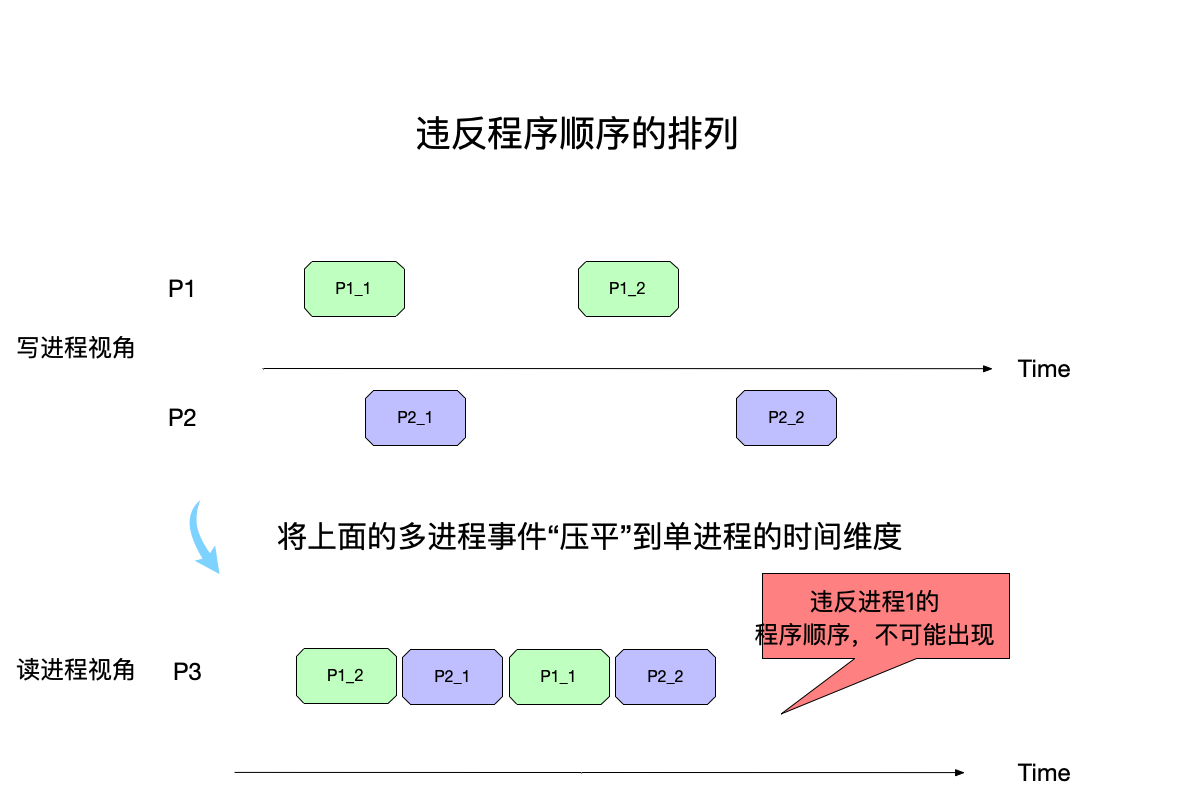
上图中:
- 进程${P_1}$视角下:程序的执行顺序是先执行 ${P_11}$,再执行 ${P_12}$。
- 但是到了P3视角下重排事件之后,${P_12}$出现在了事件${P_11}$前面,这是不允许出现的,因为违反了原进程${P1}$的程序顺序了。
但是,仅靠条件1还不足以满足顺序一致性,于是还有条件2:
- 条件2:对变量的读写要表现得像FIFO一样先入先出,即
每次读到的都是最近写入的数据。
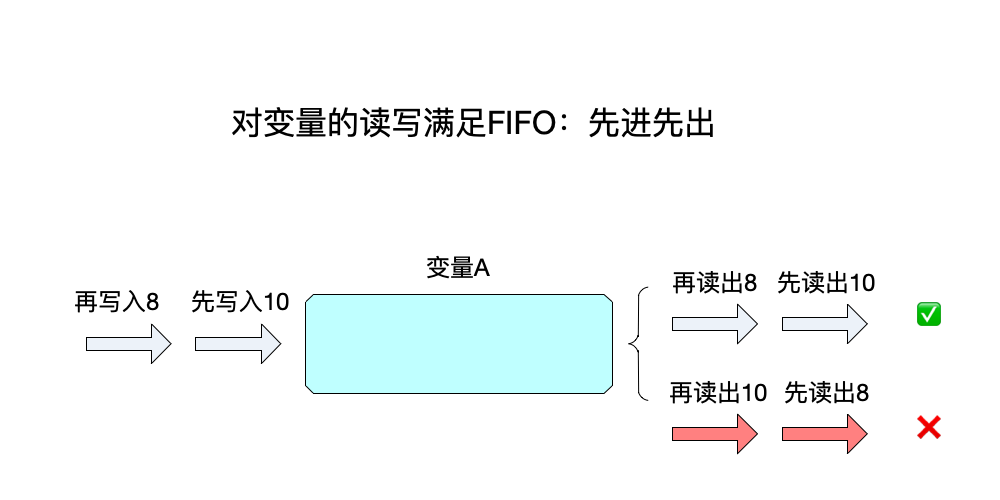
我们来举一个例子来完整说明顺序一致性:
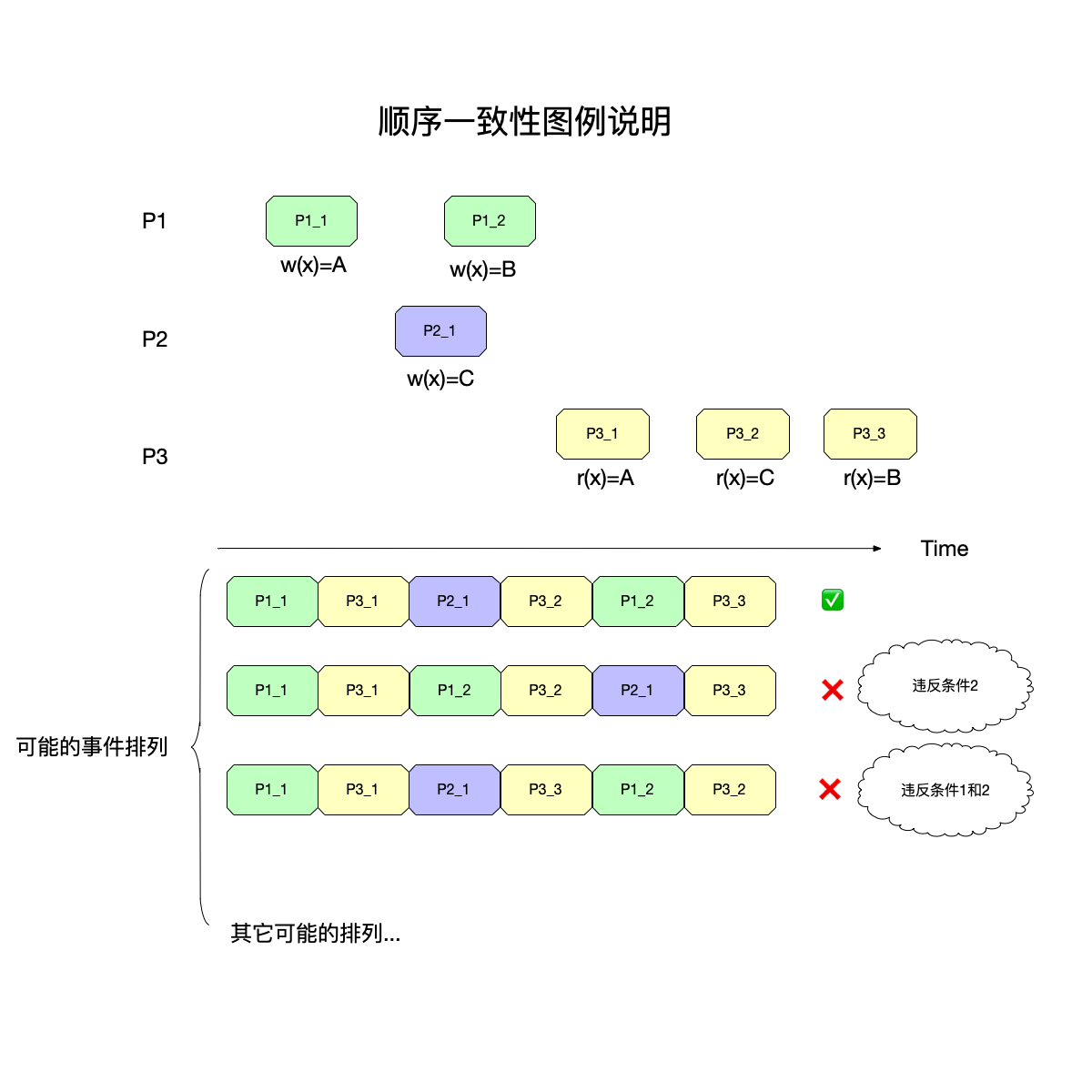
上图中,有三个进程对变量x进行读写操作:
-
进程${P_1}$:事件${P_11}$修改x为A,事件${P_12}$修改x为B。
-
进程${P_2}$:事件${P_21}$修改x为C。
-
进程${P_3}$:事件${P_31}$读出x为A,事件${P_32}$读出x为C,事件${P_31}$读出x为B。
注意:在上图中,事件${P_12}$和${P_21}$有重叠,意味着这两个事件是“并发事件”,即哪个事件先发生、完成都是可以接受的。
图中下半部分给出了三种可能的事件排列:
- 第一种排列:
- 将事件对应的操作解读出来,那么执行顺序为:{w(x)=A,r(x)=A,w(x)=B,r(x)=B,w(x)=C,r(x)=C}。
- 可以看到,上面这个顺序,既没有违反条件1(因为同进程的程序顺序没有被打乱),也没有违反条件2(读出的都是开始写入的数据)。
- 第二种排列:
- 将事件对应的操作解读出来,那么执行顺序为:{w(x)=A,r(x)=A,w(x)=B,r(x)=C,w(x)=C,r(x)=B}。
- 由于${P_12}$和${P_21}$是并发事件,可以任意排列两者的顺序,这里选择先执行${P_12}$,可以看到:
w(x)=B,r(x)=C,这违反了条件2。
- 第三种排列:
- 将事件对应的操作解读出来,那么执行顺序为:{w(x)=A,r(x)=A,w(x)=C,r(x)=B,w(x)=B,r(x)=C}。
- 这一次选择了先执行${P_21}$,可以看到:
w(x)=C,r(x)=B以及w(x)=B,r(x)=C:违反了条件2。- ${P_33}$先于${P_32}$执行,违反了条件1。
以上就是顺序一致性的解释,它要求两个条件:
- 不能打乱单进程的程序顺序,同一个进程里的事件先后顺序要得到保留。
- 每次读出来的都是最新的值,而且一旦形成了一个排列,要求系统中所有进程都是同样的一个排列。
这里需要特别说明的是,只要满足这两个条件,并没有对不同进程的事件先后顺序其他硬性的规定,所以即便是某些事件在排列之后看起来违反了事件发生的先后顺序也是可以的。其实这在上图中已经有体现了:
- 事件${P_31}$明明比事件${P_12}$和${P_21}$发生得更晚,但是只要在重排之后它是紧跟着${P_11}$的第一个读事件,就没有违反顺序一致性。在这个大前提下,事件${P_31}$甚至能出现在${P_12}$和${P_21}$之前,这看起来就很
违反直觉了。
再比如下图:
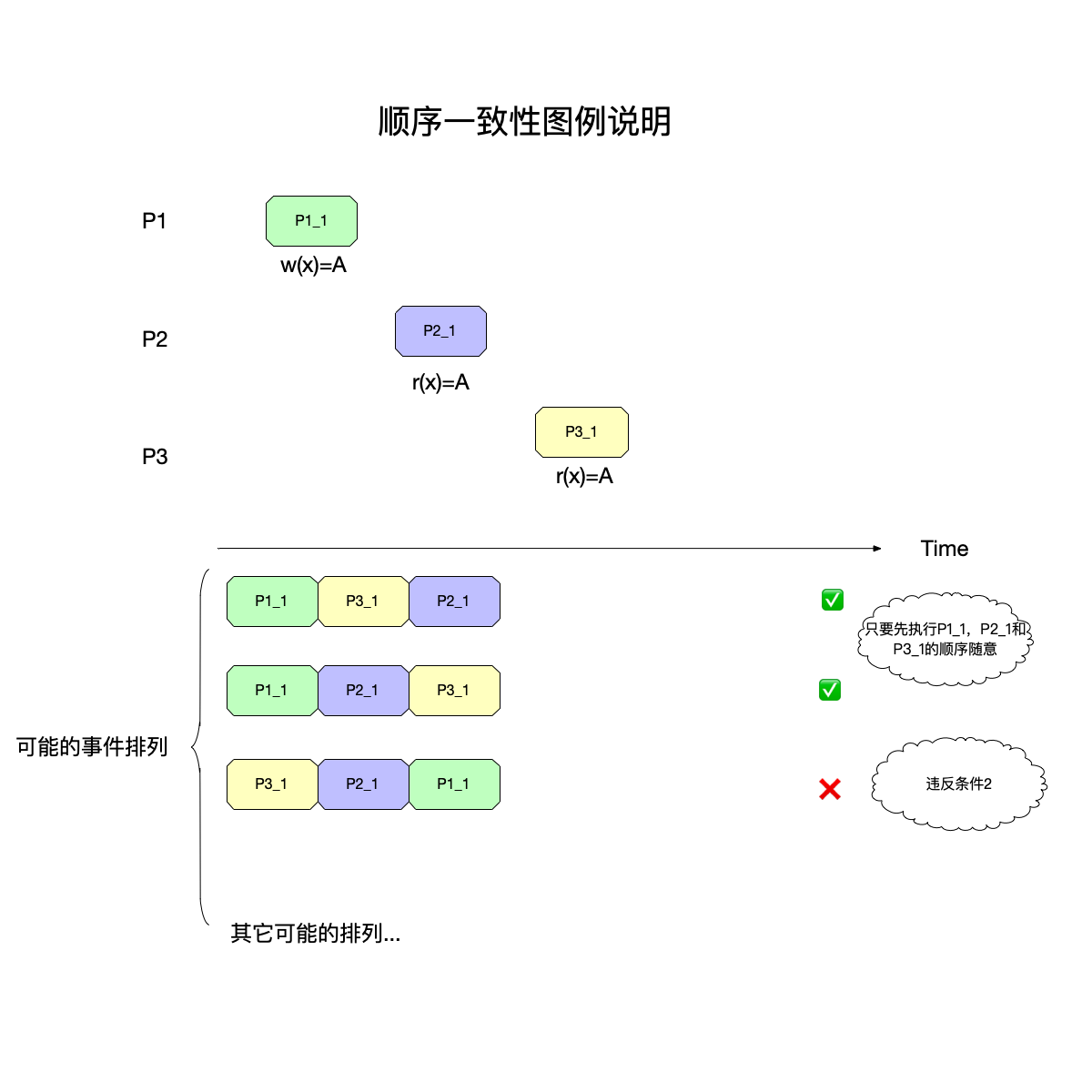
在上图中,故意将三个事件画的分开一些,意味着三个事件并不重叠,即有明确的先后顺序,但是在顺序一致性模型看来:
- {${P_11}$,${P_21}$,${P_31}$}和{${P_11}$,${P_31}$,${P_21}$}都是对的,因为这两者都没有违反条件1和2。
- 只有最下面的{${P_31}$,${P_21}$,${P_11}$}才是错的,因为违反了条件2。
可以看到,顺序一致性在满足了条件1、2之后,对不同进程的事件之间的顺序没有硬性的要求,即便在感官直觉上某事件应该发生得更早,但是只要没有违反这两个条件就可以认为是满足顺序一致性模型的。
于是就出现了更严格的线性一致性,它基于顺序一致性的条件,对事件的先后顺序做了更严格的要求。
线性一致性 #
线性一致性要求首先满足顺序一致性的条件,同时还多了一个条件,不妨称之为条件3:
- 条件3:不同进程的事件,如果在时间上不重叠,即不是并发事件,那么要求这个先后顺序在重排之后保持一致。
如果加上这个更强的条件,上面的图中,就只有{${P_11}$,${P_21}$,${P_31}$}是满足线性一致性的排列了。
再举一个例子来说明线性一致性:
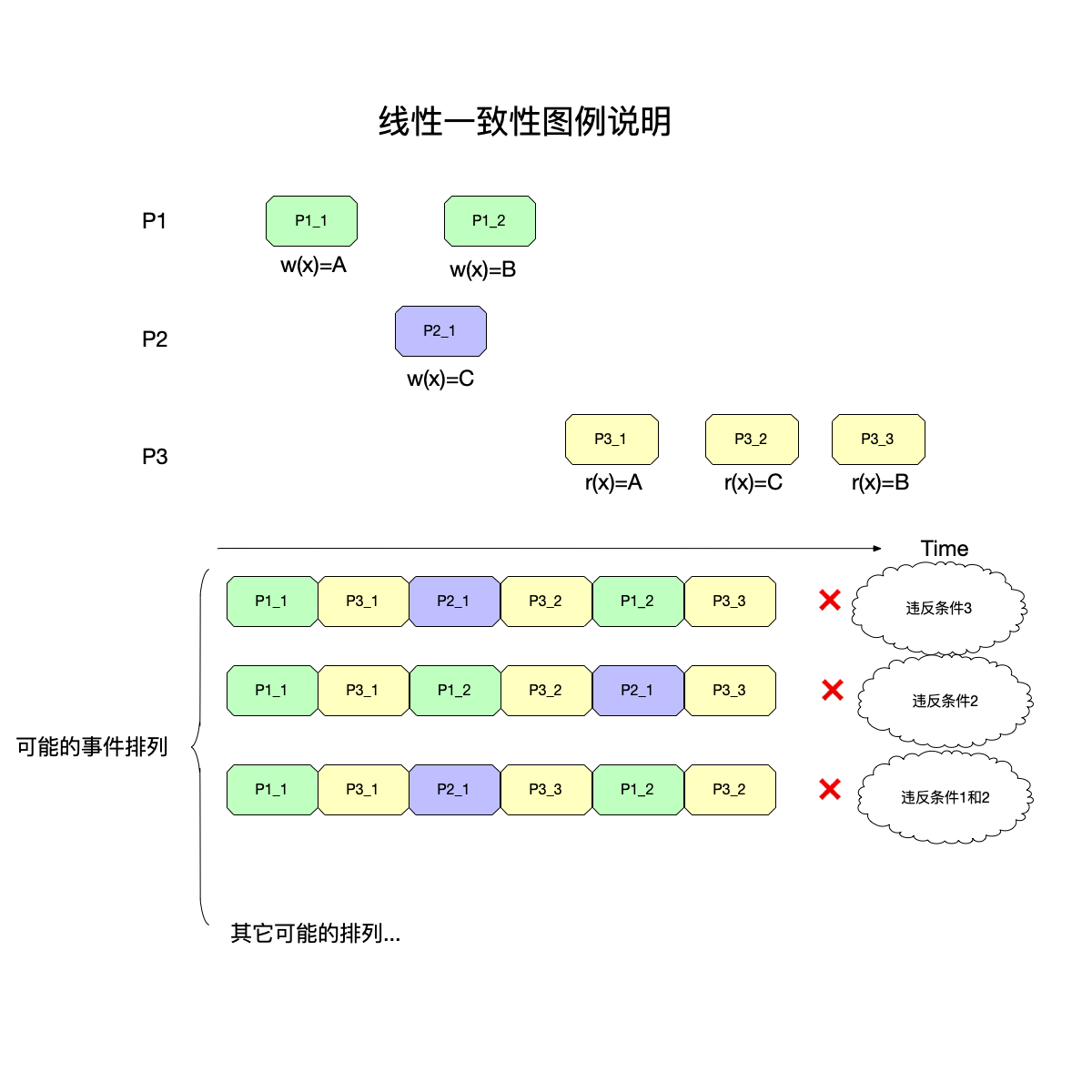
这还是最开始解释顺序一致性模型的图,但是在线性一致性的条件下,找不到能够满足条件的排列了。
这是因为:
- 事件${P_21}$和${P_12}$都在事件${P_11}$之后,这个顺序需要得到保持。
- 而事件${P_31}$在事件${P_21}$和${P_12}$之后,这个顺序也需要得到保持。
- 如果保持了前面两个顺序,那么${P_31}$执行的时候,必然读不出来A,而应该是B或者C(即${P_21}$或者${P_12}$的执行结果)。
顺序一致性和线性一致性总结 #
可以看到,如果满足线性一致性,就一定满足顺序一致性,因为后者的条件是前者的真子集。
除了满足这些条件以外,这两个一致性还有一个要求:系统中所有进程的顺序是一致的,即如果系统中的进程A按照要求使用了某一种排序,即便有其他排序的可能性存在,系统中的其他进程也必须使用这种排序,系统中只能用一种满足要求的排序。
这个要求,使得满足顺序和线性一致性的系统,对外看起来“表现得像只有一个副本”一样。
但因果一致性则与此不同:只要满足因果一致性的条件,即便不同进程的事件排列不一致也没有关系。
因果一致性 #
相较于顺序和线性一致性,因果一致性就简单一些,其实就只要满足在Lamport时钟中提到的happen-before关系即可:
- 引入符号$→ $做为表示事件之间
happen-before的记号。
- 在同一个进程中,如果事件${\displaystyle a}$在事件${\displaystyle b}$之前发生,那么${\displaystyle a → b}$。(这是因为根据规则1,进程每次发出事件之后都会将本地的lamport时钟加一,于是可以在同一个进程内定义事件的先后顺序了)
- 在不同的进程中,如果事件${\displaystyle a}$表示一个进程发出一个事件,事件${\displaystyle b}$表示接收进程收到这个事件,那么也必然满足${\displaystyle a → b}$。(这是因为根据规则2,接收进程在收到事件之后会取本地时钟和事件时钟的最大值并且+1,于是发出事件和接收事件尽管在不同的进程,但是也可以比较其lamport时钟知道其先后顺序了)
- 最后,
happend-before关系是满足传递性的,即:如果${\displaystyle a → b}$且${\displaystyle b → c}$,那么也一定有${\displaystyle a → c}$。
以评论朋友圈这个行为来解释因果一致性再合适不过:
- 评论另一个用户的评论:相当于进程给另一个进程发消息,肯定要求满足
happen-before关系,即先有了评论,才能针对这个评论发表评论。 - 同一个用户的评论:相当于同一个进程的事件,也是必须满足
happen-before关系才行。
以下图为例:
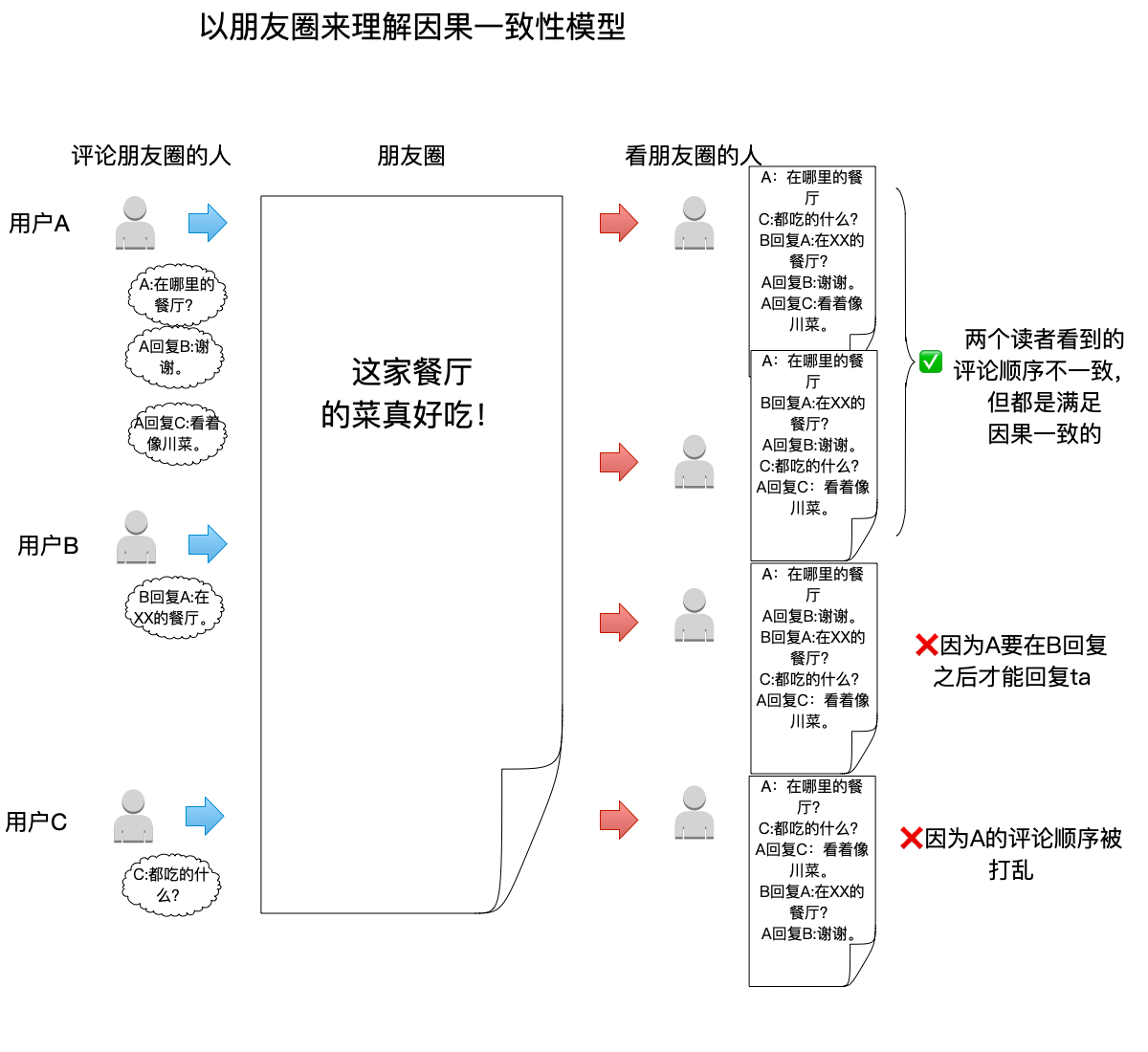
一共有4个朋友圈的读者,它们看到的评论顺序都各不一样:
- 最上面的两个读者,读到的顺序都满足因果一致性,因此即便是不一样的顺序也是正确的。
- 最下面的两个读者,顺序都不满足因果一致性:
- A回复B这个事件出现在了B回复A之前,不符合多进程之间的
happen-before关系。 - A回复C这个事件在进程A中应该在A回复B之前,不符合同一进程的事件之间的先后顺序。
- A回复B这个事件出现在了B回复A之前,不符合多进程之间的
总结 #
-
在分布式系统中,多个进程组合在一起协调工作,产生多个事件,事件之间可以有多种排列的可能性。
-
一致性模型本质上要回答这个问题:按照该一致性模型定义,怎样的事件排列才符合要求?
-
顺序一致性和线性一致性都意图让系统中所有进程
看起来有统一的全局事件顺序,但是两者的要求不同,顺序一致性:- 条件1:每个进程的执行顺序要和该进程的程序执行顺序保持一致。
- 条件2:对变量的读写要表现得像FIFO一样先入先出,即每次读到的都是最近写入的数据。
只要满足这两个条件,顺序一致性对事件之间的先后顺序并没有硬性要求,而线性一致性在此基础上多了条件3:
- 条件3:不同进程的事件,如果在时间上不重叠,即不是并发事件,那么要求这个先后顺序在重排之后保持一致。
-
因果一致性是更弱的一致性,只要满足
happen-before关系即可。由于happen-before关系实际上是由Lamport时钟定义的,这是一种逻辑时钟,所以不同的读者看到的先后顺序可能会有点反直觉,但是只要满足happen-before关系就是正确的。