In the evolution of modern software engineering, the transition from single-node applications to distributed architectures represents a critical watershed. This leap is not merely a matter of hardware stacking or code migration, but a profound transformation involving shifts in mindset, design philosophy, and even a renewed understanding of the laws of physics.
As the opening chapter of this book, it will lead readers out of the comfort zone of single-node systems and confront the real challenges of distributed environments. We will first clarify the core definition of distributed systems and analyze their essential differences and advantages over centralized systems. Next, we will focus on the unavoidable technical problems in this field—from unreliable network communication to fragmented global clocks, and the uncertainty brought by partial failures. Finally, this chapter will elaborate on the mindset shifts architects must undergo during this transition: moving from pursuing absolute certainty to seeking a balanced trade-off between consistency and availability. Understanding these fundamental concepts and paradigms is a prerequisite for mastering the complex algorithms and consistency models in subsequent chapters, and it is also the cornerstone of building highly reliable and scalable systems.
What Is a Distributed System #
Before diving into distributed systems, let us first look at their opposite: the centralized single-node system, which is also sometimes referred to as a monolithic system because all computation, storage, and processing tasks are concentrated on a single computer or a central node. The main characteristics of single-node systems are:
- Single node: All functions (such as computation, data storage, and user request processing) are completed on one machine or a single server.
- Shared resources: Shared memory and local resources are used, communication is fast, and no network message passing is required.
- Single point of control: All decisions and data management are controlled by the central node, with no need for inter-node coordination.
- Single clock: All running processes on the machine use the same clock time.
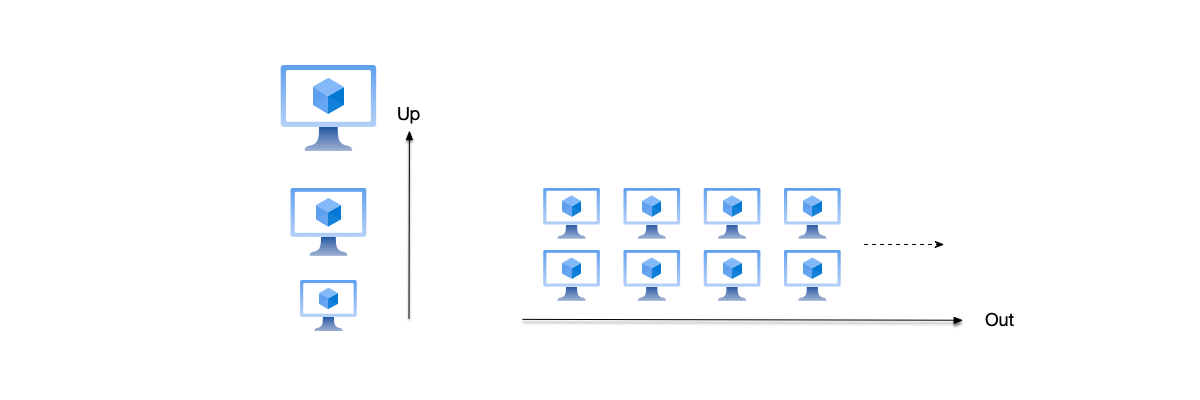
The advantages of centralized single-node systems are their simplicity: requests, computation, storage, and processing are all completed on the same node, so issues unique to distributed systems such as network latency and inconsistent system time do not exist. However, the disadvantages are also obvious: the failure of a single node can cause the entire system to become unavailable, lacking fault tolerance; at the same time, performance is limited by the processing capacity of a single node and can only be improved by upgrading hardware (vertical scaling—scale up, see the figure below).
Examples of centralized systems include:
- Traditional single-node databases.
- Single-server web applications that handle all requests and data storage.
- Local applications running on a personal computer.
However, many application scenarios and requirements cannot be solved by centralized systems, for example,
- High performance: Centralized systems can improve hardware performance through vertical scaling (using faster CPUs, larger memory, etc.) to enhance processing capacity. However, vertical scaling can never break through the physical ceiling of a single node. In contrast, distributed systems use (horizontal scaling—scale out) by combining multiple machines into a system to provide services externally. When the current system still does not meet requirements, more machines can be added to improve processing capacity. For example, in the 2003 paper [1], Google described their experience building a distributed file system using inexpensive hardware.
- High scalability: Like the performance bottleneck, as data volume grows, centralized systems also encounter bottlenecks in data storage. Distributed systems, by distributing data across multiple machines, can increase nodes to provide greater storage capacity when the system can no longer handle more data.
- High availability: The vast majority of services today require systems to run 24/7. In centralized systems, only one machine node provides service, which easily leads to the single point of failure problem: the failure of one machine causes the entire system to become unavailable. In distributed systems, multiple machines form a system, providing more redundancy so that the system can continue to run even when some machines fail.
- Geographic proximity to users: In many cases, the geographic location of users must be considered. For example, a social application has users from both Asia and Europe; in such cases, services may need to be established on different continents. These services distributed across different regions need to coordinate: for example, user IDs must be globally unique.
- Compliance requirements: With increasingly strict global data privacy regulations, system architectures must support cross-regional distributed deployment to meet compliance requirements for data residency and data sovereignty. By establishing independent data center nodes in different countries or jurisdictions, localized storage and processing of data is achieved, ensuring that user data is strictly confined within its geographic boundaries.
- Resource sharing: The term “resources” here refers not only to hardware resources but also to software resources. For example, when performing large amounts of computation, to speed up the process, the computation needs to be divided into multiple tasks and distributed to multiple machines for simultaneous execution. Through products like online shared documents, multiple users can browse and modify documents simultaneously without downloading files to their hard drives for editing, and no longer need to install processing software on their personal computers.
- Business attributes: Finally, beyond the physical limitations of centralized systems that require distributed architectures, certain businesses inherently require distributed characteristics. For example, in an e-commerce service, browsing and purchasing products happen on one platform, but paying the bill must be completed on another system (such as a payment platform or bank). In such businesses, the system must naturally be distributed.
With the horizontal comparison to single-node systems, we can now look at the definition of distributed systems. This book adopts the definition of distributed systems mentioned in [2]:
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another.
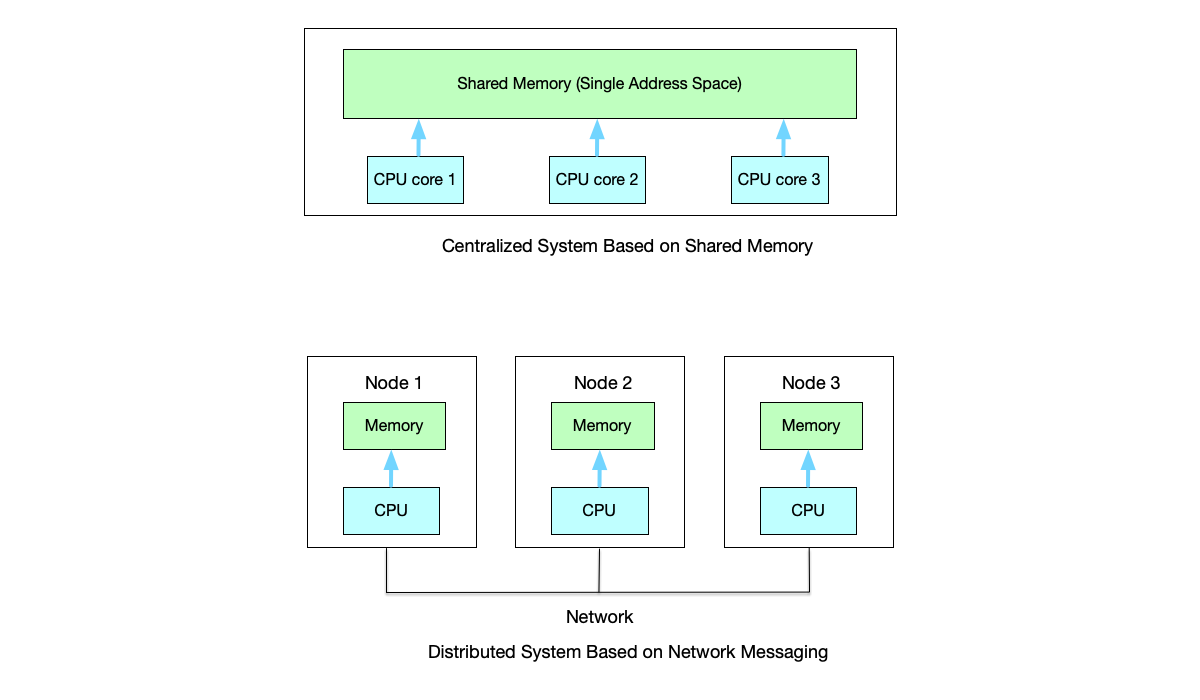
From the above definition, we can see that a Distributed System is a system composed of a set of independent computers (nodes) connected through a network, which collaborate to complete common tasks. Each node has its own processor, memory, and storage. Nodes communicate through message passing, with no shared memory.
Each computer that makes up a distributed system is called a node. Here, the concept of “computer” is very broad: it could be a personal computer, a server in a data center, a mobile device, or various types of IoT devices connected to the network (such as cars, smart home appliances, etc.). In short, a “node” can be any device capable of network communication.
Distributed systems aim to achieve high availability, scalability, and fault tolerance. Distributed systems typically have the following characteristics:
- Multi-node collaboration: A distributed system consists of multiple physically dispersed nodes working together, possibly located in different geographic locations or as independent processes. The address spaces of nodes are independent, so shared-memory multiprocessors are not considered representative of distributed systems.
- Network communication: Nodes communicate through a network (such as the Internet or a local area network). Network message latency depends on the specific conditions of the network link. For example, fiber optic cables may be severed, networks may be partitioned, and message latency may suddenly spike—these are all common failure scenarios in distributed communication.
- No global clock: Nodes lack unified time and need to synchronize through protocols.
- Collaborative work: Multiple nodes that make up a distributed system communicate and coordinate to achieve a common goal. For example, a storage system composed of three nodes jointly provides strongly consistent data services and can continue to work even when one node fails. Another example is dividing a large task into multiple small tasks, executing them jointly by multiple nodes, and then aggregating the results to obtain the final outcome.
The following table and figure list the key feature comparisons between distributed systems and centralized systems.
| Feature | Distributed System | Centralized System |
|---|---|---|
| Architecture | Multi-node, connected through network | Single node |
| Communication | Message passing through network, latency unbounded | Local call, low latency |
| Scalability | Horizontal scaling | Vertical scaling |
| Fault tolerance | High fault tolerance through multi-node redundancy | Single point of failure affects availability |
| Consistency | Need to define the allowed consistency model | Naturally consistent, no extra coordination needed |
| Complexity | Complex design and maintenance | Simple design and maintenance |
Comparison between centralized systems and distributed systems
However, although distributed systems have many advantages over centralized systems, implementing a reliable distributed system is not easy. Let us proceed to look at the challenges of implementing distributed systems.
Challenges of Distributed Systems #
When developers first turn to distributed system development, they bring with them much of the inherent experience from single-node system development. L. Peter Deutsch and others, during their time at Sun Microsystems, summarized the fallacies of distributed computing from their work [3]:
- The network is reliable.
- Latency is zero.
- Bandwidth is infinite.
- The network is secure.
- Topology doesn’t change.
- There is one administrator.
- Transport cost is zero.
- The network is homogeneous.
We will discuss some of these issues in detail below.
Unreliable Networks #
In single-node systems, messages are all local calls, with low latency and no possibility of non-delivery. In single-node programs, communication between two modules (such as function A calling function B) is completed through the memory bus and CPU instructions, which guarantees the following characteristics for communication under single-node systems:
- Reliability: Barring hardware failures, anomalies like data loss rarely occur.
- Synchronicity: This communication is usually synchronous.
- Bandwidth and latency: Bandwidth is extremely wide, latency is extremely low (nanosecond level), and very stable.
In distributed systems, however, nodes communicate through the network, and network communication often has unbounded latency: that is, it cannot guarantee any bound on data latency, and in some cases, messages may not arrive at all. For example, message delivery in the network may exhibit the following phenomena:
- Message loss: Requests may be dropped during router queuing, or because fiber optic cables are accidentally severed (case (a) in the figure below).
- Different messages arrive in a different order than when sent, or different nodes receive messages in different orders. When the same two nodes communicate, it is possible that message 1 was sent first and message 2 was sent later, but because they took different routing paths, message 2 may arrive before message 1.
- Due to network partitions and other factors, messages cannot be received by the peer, even though the receiving node is still in a working state.
- Due to message sending failures, messages may be retransmitted, causing the receiving node to receive multiple identical messages.
- In a single node, the time to read memory has an upper bound. But in a network, a data packet may be delayed by 1 ms or 1 minute, and it is impossible to distinguish whether the receiving party has crashed (case (b) in the figure below), is processing slowly, or there is a network problem.
- The message is successfully processed by the receiver and acknowledged, but the acknowledgment message is lost on the way back (case (c) in the figure below).
- …
As can be seen, when the above failures occur, they manifest as message delays, out-of-order delivery, and loss, but it is impossible to distinguish whether it is a “node failure (such as a crash)” or a “network failure.”
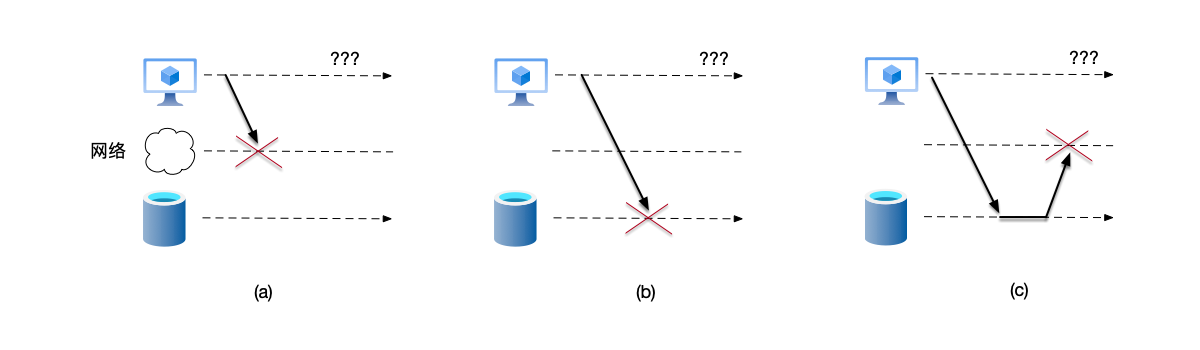
Therefore, even when using a transport protocol like TCP that encapsulates error retry and congestion control logic, developers cannot assume the network is reliable. TCP indeed performs retransmission and sequencing at the transport layer, providing the application layer with an illusion of a “reliable stream.” However:
- TCP cannot solve the problem of connection disconnection: if the network cable is unplugged, TCP will retry several times and eventually report an error. At this point, the application layer still has to handle the failure.
- TCP masks latency: to ensure ordering, TCP will block subsequent data packets, causing the application layer to experience severe latency jitter.
- TCP cannot guarantee “delivery” at the business level: a TCP ACK only means the kernel is telling the kernel “I received it,” not that the application has processed the request. For example, it is possible that after the data packet is received by the kernel but before it is processed by the application, the application crashes.
Clock and Ordering Problems #
In human intuition, time is linear and absolute. But in distributed systems, time is fragmented. In single-node systems, there is only one source of time, and the operating system is like an absolute referee holding a stopwatch. For example,
- Process A writes a file at 12:00:01.
- Process B reads the file at 12:00:02.
- Undoubtedly, A happened before B.
Because single-node systems have only one global clock, physical timestamps can be safely used to determine the order of events. As shown on the left side of the figure below, if you see in the logs that the timestamp of event X is smaller than that of event Y, then X definitely happened before Y. In the single-node world, the unique system-wide global clock provides a unique, strict sequence for all events.
However, in distributed systems, due to the following factors, there is no globally unique clock:
- Different nodes have different times. For example, the time on node A may be one second faster than the time on node B, so the order of events cannot be determined by simply comparing the times on different machines.
- Messages are transmitted between nodes through network communication, and network latency fluctuates, making it impossible to predict how long message delivery actually takes.
The above facts make it difficult in distributed systems to determine the order of events involving multiple machines based on the physical time of nodes. As shown on the right side of the figure below:
- Node A, with a faster clock, sends a message at time 10:01:54.765.
- Node B, with a slower clock, receives this message, and its local time is now 10:01:54.432.
- From the logs, B received the message before A sent it, which violates the laws of physics. Node B seems to have received a message from the future.
Therefore, in distributed systems, if physical timestamps are relied upon to resolve conflicts (such as “whoever writes last wins”), this clock error can lead to catastrophic data overwrites. We will explore the issues of time and ordering in distributed systems in depth in the Time and Order chapter.
Partial Failure #
In single-node systems, system behavior is deterministic, existing in only two possible states: either working normally or crashed. This “all-or-nothing” binary state is relatively easy to handle:
- If the code logic is wrong, the program will throw an exception or report an error.
- If the hardware fails (such as a power outage), the entire operating system will stop, and the program will terminate abruptly.
But in distributed systems, where multiple nodes coordinate work through network communication, they face a completely new failure mode: Partial Failure. Partial failure refers to a situation where some nodes or parts of the network in the system have failed, while other parts continue to run normally. “Partial failure” is far more difficult to handle than “complete crash” because it introduces uncertainty (nondeterminism).
Imagine that service A sends a request to service B, wanting to deduct 100 dollars from the balance. In a single-node function call, this would quickly return success or failure. But in a distributed network, service A waits for 5 seconds and receives nothing. At this point, the following possibilities exist, and service A cannot distinguish between them:
- Request lost: The request never reached service B due to network failures.
- Node crash: The request reached service B, which was halfway through processing, or had just deducted the money but had not yet had time to reply, when B’s power cord was unplugged.
- Response lost: Service B successfully processed the request, the deduction was successful, and it sent back “OK,” but the “OK” packet was lost on the way back.
- Slow processing: Service B is alive and well, but is responding slowly due to a garbage collection pause or database lock contention was too fierce, and it has not yet had time to reply.
This state of “not knowing what happened, so not knowing what to do” is the greatest challenge brought by partial failure.
Specific problems brought by partial failure include:
- “Sub-healthy” processes: A failing node may enter a “zombie” or degraded state. It occasionally responds and occasionally times out, causing the caller to not dare to disconnect easily and to keep retrying.
- Data inconsistency: If the request is to “deduct money from a bank account” and the response is lost, the sender, assuming failure, initiates a retry—even though the receiver has already successfully deducted the money. Without special handling, this may lead to duplicate deductions.
- Resource exhaustion (cascading failure): This is the most fatal. Suppose service A depends on service B. Service B experiences partial failure (responses become extremely slow). Service A’s threads will block waiting for B’s response. As requests continue to pour in, all of service A’s threads will be suspended waiting, causing service A’s memory and CPU to be exhausted, and eventually service A also fails. This is like a car getting a flat tire and slowing down (partial failure) on a highway, causing the entire highway behind it to be jammed (cascading failure).
- Ghost behavior: Sometimes the system determines that a node is down and offline (because network congestion prevented a heartbeat), and so it starts a standby node. As it turns out, the original node did not crash, but was just slow to respond for some reason. When the network recovers, two nodes operate on the same data simultaneously (split-brain), causing data corruption.
It is precisely for these reasons that Leslie Lamport once wryly described distributed systems as:
A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.
Although this is not a formal definition of distributed systems, it captures the challenges faced by distributed systems. In short, when a single-node system fails, it is easy to know that the system has a problem, but in distributed systems, the phenomenon is message timeout, and yet it is impossible to know exactly what happened.
Data Consistency #
If “partial failure” represents the inherent physical flaw of distributed systems, then the “data consistency” challenge constitutes its core logical contradiction. To thoroughly understand the complexity of distributed architectures, it is necessary to first review the idealized environment provided by the single-node model. In that world, strong consistency is an innate fundamental guarantee:
- Shared memory model: In multi-threaded programs, as long as a lock is added or atomic variables are used, when thread A modifies variable $x$ to 100, thread B reading $x$ afterward will definitely read 100.
- Single database: In a MySQL instance running on a single node, once a transaction is committed, the data is persisted. No matter who queries afterward, they will see the latest data.
In the single-node world, there is only one truth, and the propagation of truth is instantaneous. There is an invisible “global observer” (the operating system or database kernel) that guarantees all observers always see the same state.
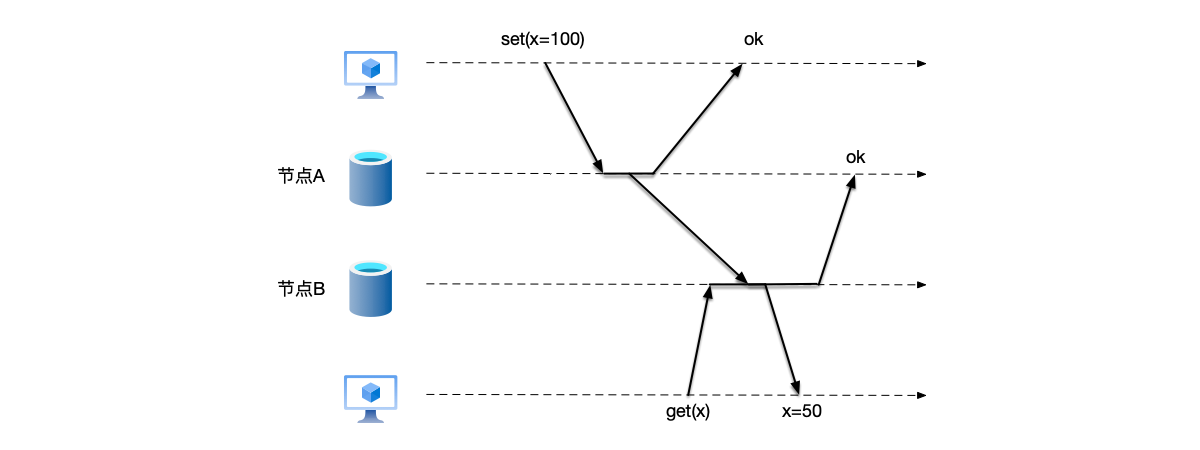
But in distributed systems, when multiple machines communicate through network messages, the laws of physics (the limit of the speed of light) shatter this beautiful illusion. To prevent single points of failure, we usually replicate data to multiple machines (such as in a master-slave architecture). Once replicas are introduced, the single truth ceases to exist; instead, multiple divergent states may emerge. As shown in the figure below, imagine the following scenario:
- Node A receives a user’s write request: “Change the balance to 100.”
- After updating its own data, node A responds to the client that the write was successful.
- Node A notifies node B through the network: “Change the data to 100.”
- During the few milliseconds (or even seconds) of delay in this network transmission, another user sends a query request to node B but receives old data.
At this point, node A says the balance is 100, and node B says the balance is 0. Who is right?
- From a temporal perspective, the data on node A is the latest.
- But from node B’s perspective, it has no idea what happened at A.
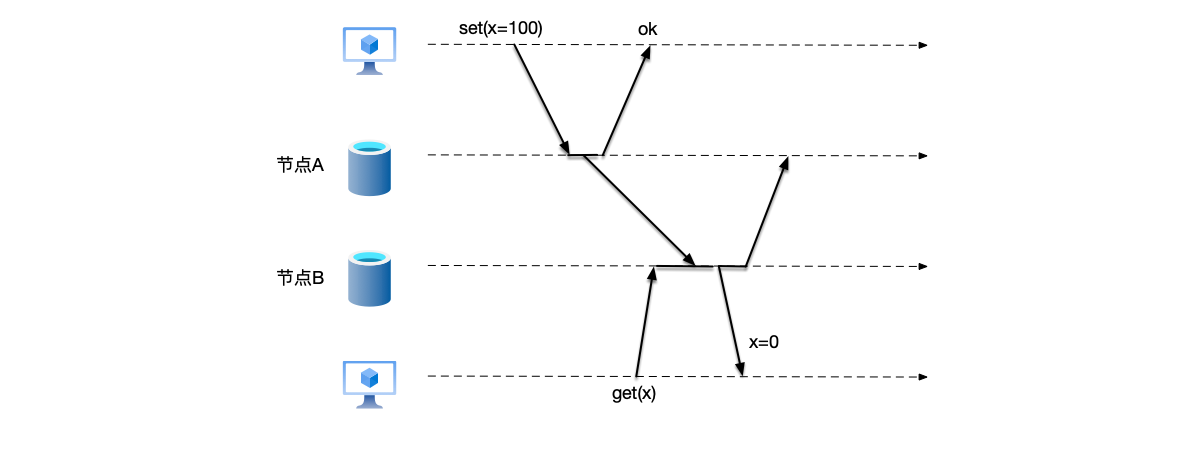
This is the consistency problem of distributed systems: due to the delay in message communication, there is no other way to ensure that all nodes have the same data view at the same moment.
Fortunately, in distributed systems, consistency is not a black-and-white Boolean value (yes/no), but a spectrum. The architect’s job is no longer to find “perfect truth,” but to find the subtle balance point between “how long to make users wait for data accuracy” (latency/strong consistency) and “how much old data to allow users to see for speed” (availability/eventual consistency) based on business scenarios.
The above are the challenges faced by distributed systems. The remaining content of this book will revolve around these challenges, explaining in detail how to solve these problems. The following table provides a simple comparison and summary. We will begin our discussion of this book with these questions.
| Dimension | Single-node Features | Distributed Challenges | Key Technologies/Solutions |
|---|---|---|---|
| Time | Physical clock total order | Physical clock unreliable | Logical clocks, TrueTime |
| Failure | Crash means stop | Partial failure | Replication, consensus |
| Consistency | Strong consistency (ACID) | Replica delay, data conflicts | Consistency models, distributed transactions, consensus |
| Capacity | Single-node hardware limit | Unlimited data volume | Partitioning |
Characteristics of centralized systems and challenges of distributed systems
Mindset Shift #
We have already understood the differences between single-node and distributed systems. When engineers transition from single-node system development to distributed system development, the following mindset shifts are required:
From “Binary Logic” to “Ternary Logic”
In single-node systems, a function call has only two possible outcomes: either success (returning a result) or failure (throwing an exception). In single-node systems, computers are reliable; CPU instructions either execute or they do not.
In distributed systems, remote procedure calls (RPC) between nodes have three possible outcomes: in addition to success and failure, there is also the possibility of message timeout. When message timeout occurs, there is no way to know whether the other party did not receive the request, is processing slowly, or the reply was lost after processing.
Therefore, distributed engineers must learn to handle such a “Schrödinger state.” In message communication, idempotency design must be introduced: because it is not known whether the last attempt succeeded, the system must be designed to allow retries and ensure that the result of multiple retries is the same as a single attempt.
From “Global Consistency” to “Relativity”
In single-node systems, because there is a globally unique clock, event times have a strict order. For example, if logs show that event A occurred at 10:00:01 and event B occurred at 10:00:02, then event A definitely occurred before event B.
But in distributed systems, because there is no globally unique clock, the reliance on “absolute time” must be abandoned, and instead the “order of events” must be focused on. In addition, engineers need to accept eventual consistency in certain scenarios: at this moment, the balance is 100 dollars from service A’s perspective, while it is 90 dollars from service B’s. This is “normal” in distributed systems, as long as we reach agreement after a while.
From “Perfectionism” to “The Art of Trade-offs”
In single-node systems, ACID (Atomicity, Consistency, Isolation, Durability) is regarded as the golden standard taken for granted. The database promises: as long as a transaction is committed, the data will never be lost, and everyone will see the latest state. Developers are accustomed to this “perfect” guarantee.
However, in the distributed world, the CAP theorem (Consistency, Availability, Partition Tolerance) shatters this illusion. Beginners often mistakenly think that CAP means you can arbitrarily pick two out of C, A, and P, but in distributed reality, partition tolerance is not an option but an objective fact that must be accepted. Network partitions are inevitable: fiber optic cables will be severed, routers will be congested, and even data centers may lose power. Once a network partition occurs (nodes cannot communicate with each other), the system must face a cruel choice:
- If you want 100% availability (ability to read and write at any time), you must sacrifice strong consistency (possibly reading stale data).
- If you want strong consistency (everyone must see the same thing), you must sacrifice availability during a network partition (system reports an error or blocks).
This requires engineers to no longer seek a “perfect solution,” but to find “the most suitable solution for the business.” In distributed architecture, there is no best design, only the most reasonable trade-off under specific constraints.
Note: We will discuss ACID in depth in the Transactions chapter and the CAP theorem in the Replication chapter.
From “Defending Against Failures” to “Embracing Failures”
In single-node systems, failures are exceptional cases, and engineers strive to avoid system crashes.
But in distributed systems, failures are the norm:
- When a system has 1,000 machines, hard drives may fail every day, and network jitters may occur at every moment.
- Special attention must be paid to partial failure: the entire system has not crashed, but because some non-critical service is responding slowly, the entire thread pool is dragged down, causing the main site to go down.
This requires engineers to design for failure—assuming dependencies will inevitably crash, delay, or deliver out-of-order messages. By adopting patterns like circuit breakers, graceful degradation, and bulkheads, systems can isolate the failing components rather than cascading into total failure.
Chapter Summary #
This opening chapter officially unlocks the door to distributed systems. Starting from the most basic definitions, and through comparison with traditional centralized single-node systems, we have established a fundamental understanding of distributed systems and analyzed the complex challenges and paradigm shifts behind them.
- Architectural evolution: from single-node to distributed. Single-node systems are based on shared memory and a single clock, with advantages such as simple models and strong consistency, but face single points of failure and the physical bottleneck of vertical scaling. Distributed systems are composed of a set of independent computers (nodes) interconnected through a network, which communicate and coordinate through message passing. To break through the limitations of single nodes, we have turned to distributed architectures. Through horizontal scaling, using the collaboration of multiple machines, we have achieved high performance, high scalability, and high availability, and met the needs for data compliance and business isolation.
- Core challenges: beautiful illusions are shattered. Distributed systems are powerful, but they are not a free lunch. We have shattered common myths such as “the network is reliable” and “latency is zero” (fallacies of distributed computing) and confronted the following major core challenges:
- Unreliable networks: Unlike the reliable memory bus of a single node, network communication has problems such as packet loss, out-of-order delivery, and unbounded latency. Even the TCP protocol cannot solve business-level “delivery” confirmation or logical handling after connection disconnection.
- Clocks and ordering: Distributed systems lack a globally unique physical clock, making it impossible to rely solely on physical timestamps to determine the order of distributed events; new logical clock mechanisms must be found.
- Partial failure: This is the most tricky problem in distributed systems. Unlike the definite state of “all or nothing” in single-node systems, distributed systems have a “zombie” state—it is impossible to determine whether the other party is dead or alive, and impossible to determine whether a request was executed successfully.
- Data consistency: Due to the existence of data replicas and the physical limit of the speed of light, it is extremely difficult to ensure that all nodes have the same data view at the same moment. We need to find a balance between “strong consistency (waiting for synchronization)” and “availability (fast response).”
- Mindset shift: the engineer’s self-evolution. Transitioning from developing single-node applications to distributed systems is not only a technical upgrade but also a reconstruction of mindset:
- From binary to ternary: Abandon the “success/failure” binary and learn to handle the “success/failure/timeout (unknown)” ternary logic, and introduce idempotency design.
- From absolute to relative: Abandon reliance on global absolute time and instead focus on the causal order of events and logical clocks.
- From perfection to trade-offs: Accept the constraints of the CAP theorem, no longer seek perfect strong consistency, but make trade-offs between consistency and availability based on business scenarios.
- From defense to embracing failures: Admit that failures are the norm, and design fault-tolerant systems through techniques such as circuit breakers and degradation, rather than praying that failures do not occur.
Through the study of this chapter, readers have gained a preliminary understanding of distributed systems and know the challenges and difficulties of distributed systems. In the following chapters, we will provide specific engineering solutions and theoretical foundations for the issues raised in this chapter—replication, partitioning, logical clocks, consensus algorithms, consistency models—one by one.
References #
-
Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung: “The Google File System,” at 19th ACM Symposium on Operating Systems Principles (SOSP), October 2003. doi:10.1145/945445.945450
-
G. Coulouris, J. Dollimore, T. Kindberg, and G. Blair: “Distributed Systems: Concepts and Design,” 5th edition. Pearson, 2011.
-
Wikipedia: “Fallacies of distributed computing”