In the previous chapter, we compared single-node systems with distributed systems. A single-node system communicates through shared memory, has a globally unique clock, and exhibits deterministic behavior when errors occur, making programming on such systems relatively straightforward. In contrast, a distributed system consists of multiple nodes that communicate via messages, which makes distributed systems significantly more complex. Therefore, before designing a distributed system, we need a theoretical framework to describe how the system operates. Designers must clarify the assumptions and conditions of the runtime environment at design time, as different conditions entail varying implementation challenges. Models of distributed systems are the theoretical frameworks used to describe and analyze the behavior, properties, and design of distributed systems. They provide an abstraction for studying communication, computation, failures, and synchronization in distributed systems, helping designers and researchers understand system behavior and solve practical problems in complex environments.
In this chapter, we start our discussion of distributed-system models with two famous thought experiments: the Two Generals’ Problem and the Byzantine Generals’ Problem.
Two Generals’ Problem #
The Two Generals’ Problem [1] is a thought experiment in the field of distributed systems. It aims to illustrate the pitfalls and challenges of coordinating operations among multiple nodes in a distributed system through an unreliable connection.
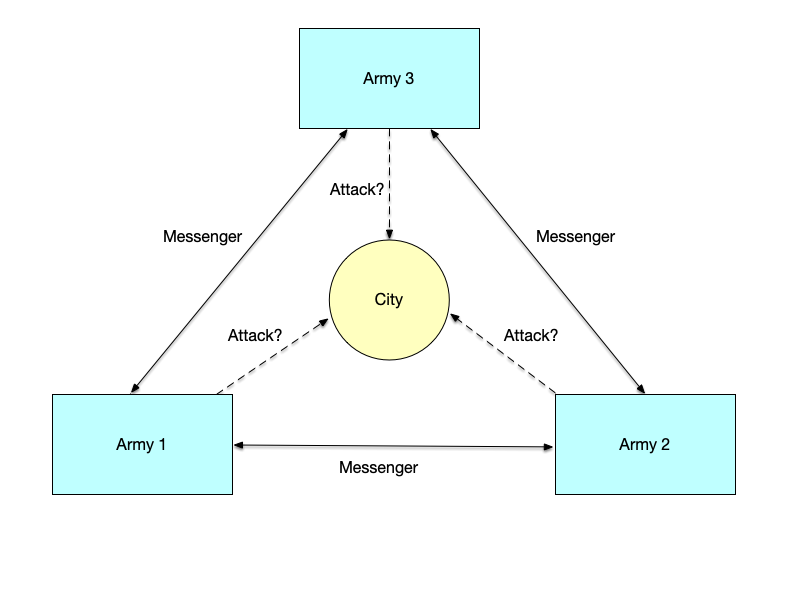
The experiment assumes two armies, each led by a general. The two armies are preparing to attack a city. The city’s defenses are strong, and both armies must act together to win; either army acting alone will fail. The two generals need to coordinate a common time to attack. The two armies are stationed on opposite sides of the city, separated by a valley. The only way for them to communicate is to send messengers across the valley. However, the valley is controlled by the city’s defenders, so messages passing through it may be captured.
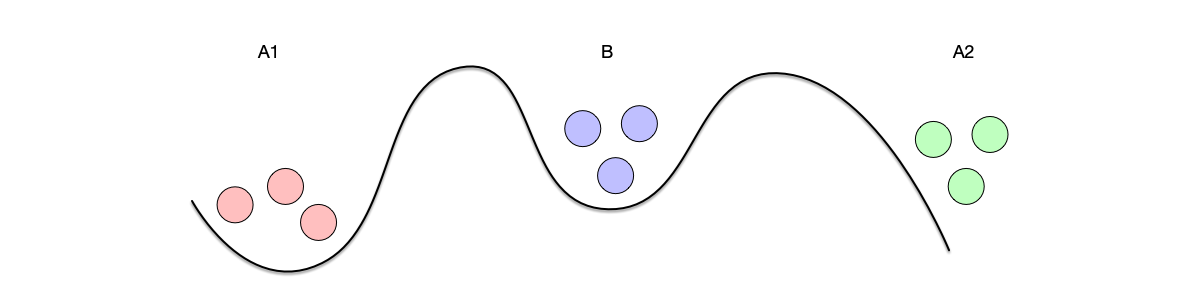
Although the two generals have already agreed to attack the city, they have not yet agreed on the time of the attack. Both generals must order their armies to attack simultaneously in order to win. Therefore, they must communicate and coordinate a time to attack. If one general believes a time has been coordinated while the other is unaware, and only one army attacks, the result will be a disastrous failure, as shown in the following table:
| Army A1 | Army A2 | Result |
|---|---|---|
| Do not attack | Do not attack | Nothing happens |
| Attack | Do not attack | Army A1 fails |
| Do not attack | Attack | Army A2 fails |
| Attack | Attack | City captured |
Possible outcomes of launching an attack
In this experiment, the “generals” are the nodes in a distributed system, and the messengers that communicate between them are the connections between nodes. We can see that these connections are unreliable: messages may be lost. Let us examine whether the two generals can reach consensus on an attack time when communicating over such an unreliable connection.
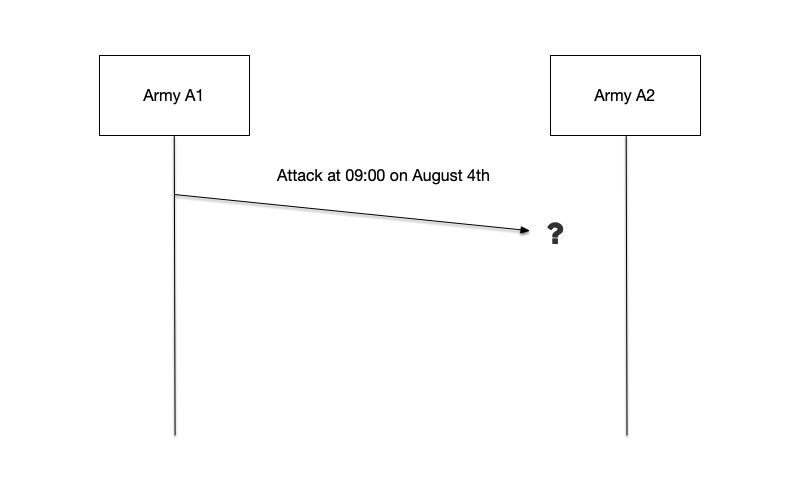
Suppose General A1 sends a message to General A2 saying, “Attack at 09:00 on August 4.” Because the messenger may be captured, General A1 is uncertain whether the message will reach General A2. This uncertainty makes A1 hesitate, because if his army attacks alone, it will face a disastrous defeat.
To eliminate this uncertainty, A1 and A2 agree that after receiving a message, the receiver will send an acknowledgment so that the sender can confirm the message was successfully received. However, the acknowledgment may also be captured, so it is also uncertain whether it will reach the receiver. This uncertainty makes A2 hesitate, because if his army attacks alone, it will face a disastrous defeat.
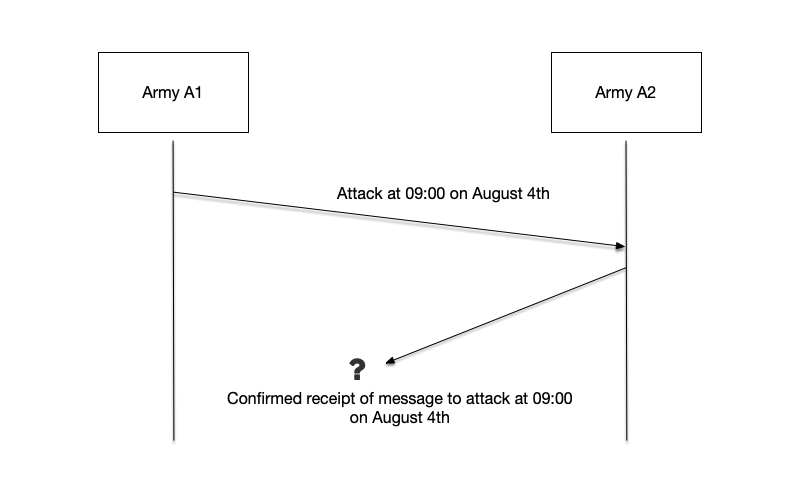
At this point the problem reaches a dead end: no matter how many acknowledgment messages are sent, neither general can have sufficient reason to believe that their messenger has not been captured by the enemy.
Based on the scenarios above, the Two Generals’ Problem highlights the following difficulties:
- Uncertainty of message delivery: General A1 sends a message to General A2 telling him the attack time, but cannot confirm whether A2 received it. Even if A2 receives it and replies with an acknowledgment, A1 cannot confirm whether the reply was delivered. This acknowledgment process may loop infinitely, because every acknowledgment requires a further acknowledgment.
- Infinite-acknowledgment problem: To ensure both sides agree on the attack time, A1 needs an acknowledgment from A2, A2 needs an acknowledgment from A1 that A2’s acknowledgment was received, and so on. Because communication is unreliable, each acknowledgment may be lost, making it impossible to reach definite consensus.
The Two Generals’ Problem was first proposed by E. A. Akkoyunlu, K. Ekanadham, and R. V. Huber in a 1975 paper [2], which described communication between two gangs and gave a proof that this class of problems is unsolvable. In 1978, Jim Gray named it the “Two Generals Paradox” in his book [3].
The Two Generals’ Problem shows that in an unreliable communication environment, absolute consensus cannot be reached through a finite number of message exchanges.
Strictly speaking, the Two Generals’ Problem cannot be completely bypassed in theory. However, in practical engineering, its limitations can be alleviated or circumvented by the following methods, making the system feasible in real-world scenarios:
- Improving Odds Through Redundancy: This approach involves sending multiple messengers simultaneously. If the receiver receives some of them, it considers action to be possible. For example, in the Two Generals’ Problem, instead of sending only one messenger, either side sends 100 messengers at the same time; if the receiver receives 10 of the messages (a 1/10 probability), it considers the message received. However, from an engineering perspective, this approach is not performance-friendly.
- Introducing timeouts and default fallback actions: The receiver can set a default time by which to expect a message. If no message from the other side arrives by that time, it takes a default safe action. For example, in the Two Generals’ Problem, the army that is to begin the attack agrees to attack at 9:00 a.m., but if no attack signal is received by 9:10 a.m., it defaults to calling off the attack. Although this default behavior cannot capture the city, it avoids the risk of failure from a unilateral attack. In distributed-system design, many designs also adopt default behavior after a timeout. For example, in the Raft algorithm, if a Follower node does not receive a message from the Leader node before the election timeout, it assumes by default that the Leader node has failed and initiates a new round of election.
Consider the real-world scenario in which two computers need to communicate. In this case, the challenge of communication is still the unreliable communication channel, so this is also one of the real-world scenarios of the Two Generals’ Problem. The TCP (Transmission Control Protocol) [4] protocol can be regarded as a partial engineering solution to the Two Generals’ Problem.
This book does not attempt to provide a comprehensive explanation of TCP’s internal mechanics; interested readers are encouraged to refer to [5]. Here we focus on how TCP communicates over an unreliable channel to partially solve the Two Generals’ Problem.
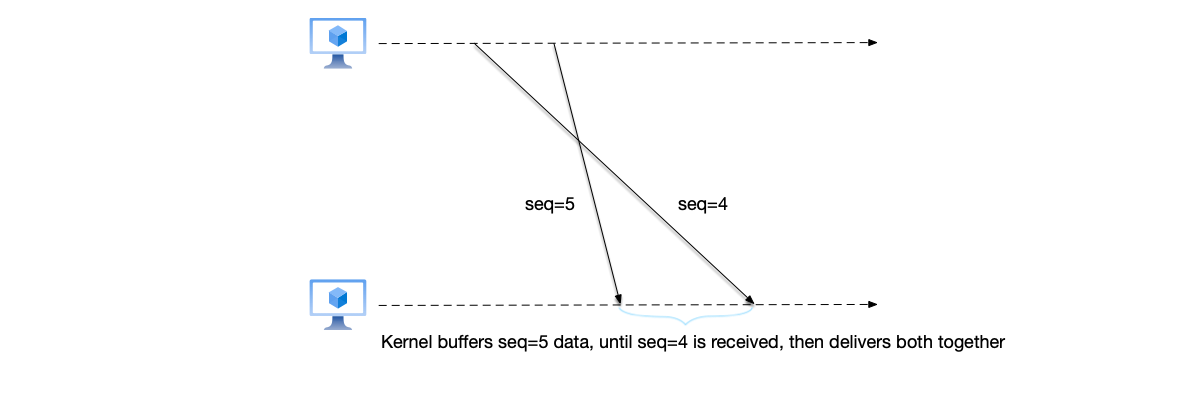
In the TCP protocol, each packet has a unique sequence number corresponding to it. After receiving a packet, the receiver confirms receipt by sending an acknowledgment (ACK). Through this mechanism, TCP solves the problem of packets arriving out of order. Consider the following scenario: if the sender sends packets with sequence numbers 4 and 5 to the receiver, but the receiver receives the packet with sequence number 5 first, delivering the packet with seq=5 to the application layer immediately would result in out-of-order data processing. To avoid delivering data out of order, the kernel first checks whether all packets before this packet have already been delivered to the application layer; only if this packet is the earliest undelivered packet will it be delivered. In this scenario, the packet with seq=4 has not yet been received, so the kernel first caches the packet with seq=5 and waits for the packet with seq=4 to arrive before delivering both together.
Note: In concrete implementations of the TCP protocol stack, the “cache out-of-order data” behavior described above is not performed indefinitely; it is strictly limited by the receive window (rwnd).
The TCP receiver maintains a sliding-window structure. When an out-of-order packet (such as seq=5) is received, the kernel checks whether the packet’s sequence number falls within the currently allowed receive window:
- If it is outside the window range: the packet is dropped directly to prevent the receiver’s memory from being exhausted.
- If it is out of order because a previous packet (such as seq=4) is missing: the TCP protocol stack temporarily stores seq=5 in an out-of-order queue and sends a duplicate ACK to the sender for the data before seq=4, triggering the sender’s fast-retransmit mechanism.
- Only when the missing seq=4 finally arrives does TCP splice seq=4 with seq=5 from the out-of-order queue into a continuous byte stream, advance the left boundary of the sliding window, and finally submit it to the application layer. This mechanism reflects an important trade-off in distributed-system design: by consuming receiver memory, network-transmission bandwidth is saved (avoiding retransmission of already-arrived out-of-order packets).
Sequence numbers solve the out-of-order delivery problem, while data loss is solved by the timeout-retransmission mechanism. In the TCP protocol, after sending a packet, the sender starts a retransmission timeout for that packet. If the sender has not received the receiver’s ACK response within the specified time, it considers the packet lost and retransmits it. TCP will make a best-effort attempt to retransmit multiple times; if all retries fail, it aborts the connection and returns an error.
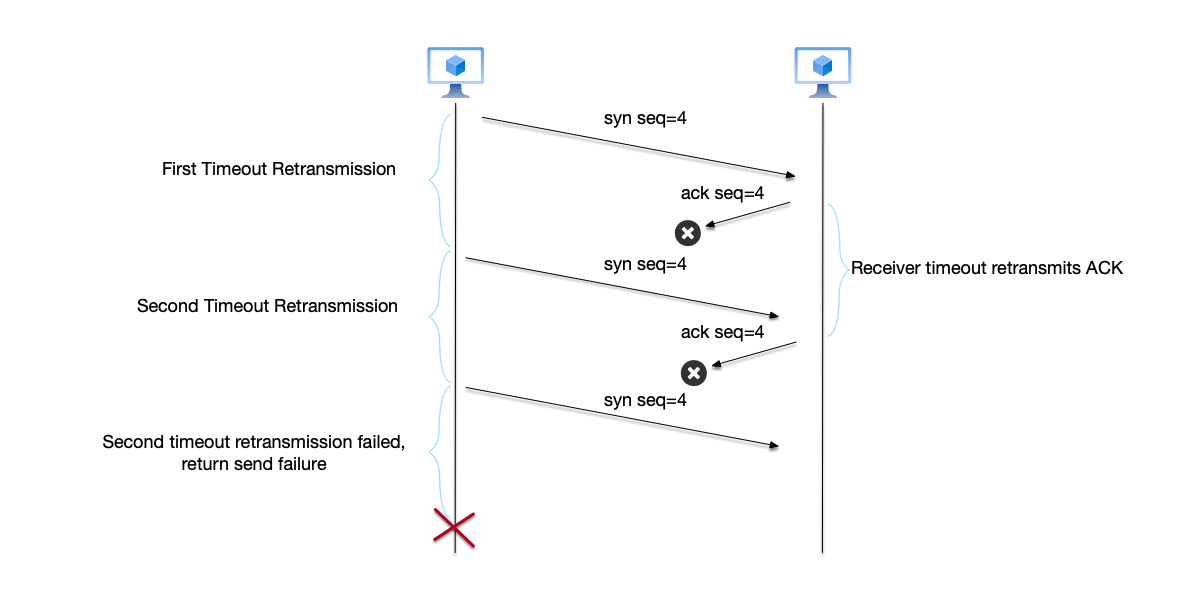
As we can see, TCP significantly improves communication reliability through sequence numbers for out-of-order delivery and through retransmission to ensure every packet is successfully sent. However, TCP still cannot completely solve the Two Generals’ Problem; it is at best a partial engineering solution. For example, if someone unplugs the network cable, no matter how many retransmissions occur, the data certainly cannot be sent or received successfully.
Note: We can see that the receiver also needs timeout retransmission when sending ACK responses, which means the sender also needs an acknowledgment for the ACK response. The explanation of TCP above omits many details for simplicity; interested readers may refer to the books recommended earlier.
Also, considering two retransmission failures as a transmission failure is also a simplification.
Byzantine Generals’ Problem #
The Byzantine Generals’ Problem [6] was first proposed by Lamport in the paper [7] and is likewise a thought experiment about distributed systems. The Two Generals’ Problem discusses problems in distributed systems caused by network communication; the Byzantine Generals’ Problem, by contrast, discusses problems caused by the nodes themselves.
Similar to the Two Generals’ Problem, the Byzantine Generals’ Problem also assumes a scenario in which armies coordinate an attack on a city. In the Byzantine Generals’ Problem, the armies’ actions include not only attack but also retreat; a mix of armies attacking and retreating may also lead to failure. In addition, unlike the Two Generals’ Problem:
- In the Byzantine Generals’ Problem, more than two armies may participate in the attack.
- In the Byzantine Generals’ Problem, it is assumed that messages communicated between armies are always received correctly; there is no situation, as in the Two Generals’ Problem, where messengers are captured and messages fail to arrive. That is, in the Byzantine Generals’ Problem, communication is assumed to be reliable.
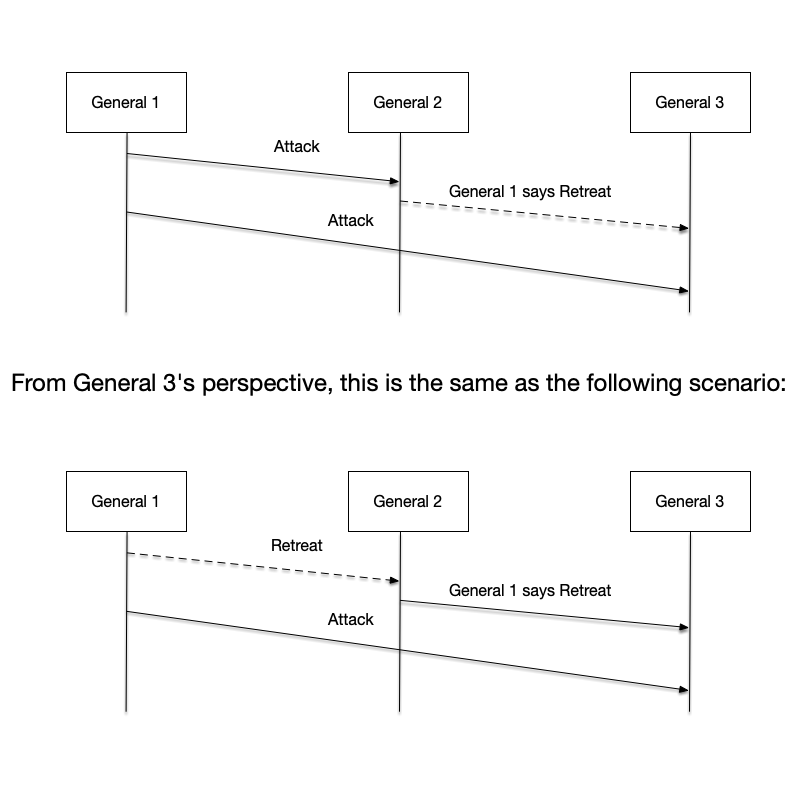
While the Byzantine Generals’ Problem assumes reliable communication, unlike the Two Generals’ Problem, it introduces a new complication: traitors may exist among the generals. These traitors may intercept and alter messages or deliberately disseminate false information.
The figure below gives two examples of what happens when traitors appear. Normal messages are shown with solid lines, while malicious messages sent by traitors are shown with dashed lines. In the upper part of the figure, after General 2 receives General 1’s attack message, he passes a tampered, malicious message to General 3: “General 1 says retreat.” General 3 then receives the attack message sent by General 1. These two contradictory messages leave General 3 confused: who is lying? In this scenario, the traitor node maliciously alters the content of the message when forwarding it.
Likewise, in the lower part of the figure, the traitor becomes General 1, who says “retreat” to General 2 and “attack” to General 3. In this scenario, the traitor node maliciously sends misleading messages to different nodes.
Although these are two different scenarios, from General 3’s point of view, he sees two contradictory messages.
Mapping the Byzantine Generals’ Problem to a distributed system, the generals are the nodes, the messengers are the communication links between nodes, and the Byzantine-failure model describes a situation in which some malicious nodes in a distributed system may tamper with or send misleading messages, causing system failures.
A paper by Cynthia Dwork et al. [8] proves that in a system with malicious nodes and unpredictable communication delays, the Byzantine Generals’ Problem can be solved only if strictly fewer than one-third of the nodes are malicious. That is, in a system with $3f+1$ nodes, no more than $f$ nodes may be malicious. For example, in a system with four nodes, at most one malicious node can be tolerated.
In some distributed systems, it is necessary to consider that malicious nodes may exist in the system. Such systems are called Byzantine fault tolerant, for example in the blockchain and cryptocurrency domains. These systems must provide guarantees that they can operate normally even when malicious nodes exist. We will continue to discuss this topic later in the chapter.
System Models #
The first two sections of this chapter discussed two thought experiments in distributed systems:
- Two Generals’ Problem: demonstrates failures that may be caused by network communication.
- Byzantine Generals’ Problem: demonstrates failures that may be caused by node behavior.
Both thought experiments are too “idealized” in that they assume only one type of failure. In real distributed systems, multiple types of failures usually coexist. Before designing a distributed system, we must first clarify the environment in which the system operates: what types of failures must be tolerated, and what consistency requirements must be satisfied. For example, the Paxos and Raft algorithms described later in the book are consensus algorithms that do not work in Byzantine-failure environments.
Models of distributed systems are theoretical frameworks and abstractions for describing and analyzing distributed-system behavior, aiming to help understand, design, and optimize distributed systems. They mainly include the following:
- Communication model: describes how nodes exchange information.
- Failure model: describes how nodes may fail.
- Timing model: defines how confident we can be about “delay” when designing algorithms.
- Consistency model: defines what consistency requirements the different nodes of a distributed system must satisfy for their data.
This chapter discusses the first three models; the consistency model is discussed in the Replication chapter.
Communication Models #
“The network is reliable” is the first of the eight fallacies of distributed computing. The article “The Network is Reliable” [9] lists various causes of network failures, including real-world examples: network maintenance, router failures, power failures, and even accidentally unplugging a power cord or cutting a fiber-optic cable.
When discussing network models, we take a more abstract perspective and ignore the details of these failures. Most distributed algorithms assume that nodes provide bidirectional message passing, known as point-to-point or unicast communication.
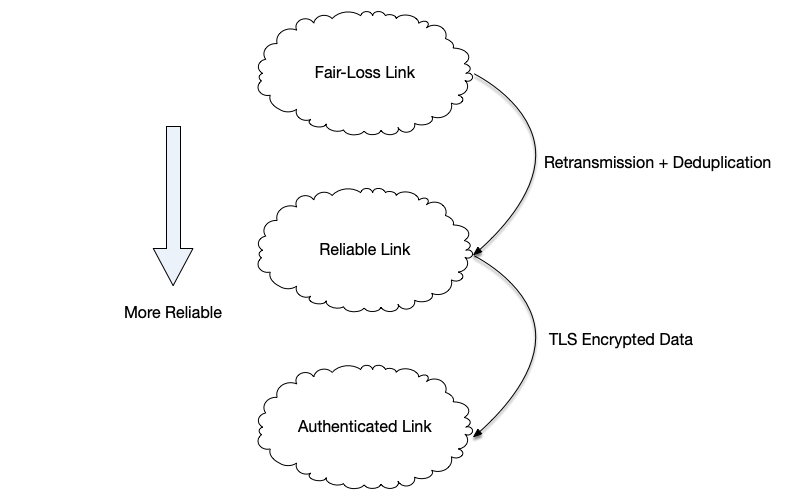
In general, the following link-reliability guarantees exist: Fair-Loss Link, Reliable Link, and Authenticated Link.
Fair-Loss Link
In a fair-loss link, messages may be lost, and some messages may be reordered or duplicated, but fair-loss links have the following core properties:
- Finite loss: messages may be lost, but not indefinitely. If a message is sent infinitely many times, it will eventually be delivered. That is, as long as the physical link is not broken, the probability of success is greater than zero.
- No spurious messages: if a receiver receives message $m$, the sender must have actually sent it (assuming no Byzantine-style malicious forgery).
The fair-loss link assumes that messages will eventually be delivered after repeated attempts. This assumption implies that network partitions will last only a finite amount of time, not forever. Therefore, as long as the sender does not crash, it can always guarantee eventual delivery through infinite retries; however, if the sender crashes before the message is delivered, it cannot retry. But it has many problems: packet loss is the norm, messages may be duplicated and reordered. It can serve as the foundation of all higher-level links, but business logic cannot be directly built on it.
Reliable Link
A reliable link is also called a perfect link. It has the following properties:
- Adds a message-retransmission mechanism to ensure messages are eventually delivered.
- Adds a mechanism to detect and suppress duplicate messages.
A reliable link guarantees reliable delivery of every message sent: if a process sends a message, it will eventually be delivered correctly. A reliable link can also guarantee that no message is delivered more than once. In short, reliable delivery and no duplicate messages mean that every message sent by a correct process is delivered exactly once.
The reliable link is precisely the communication model that the TCP protocol attempts to provide, and it is the environment usually assumed by algorithms such as Raft and Paxos. It is the standard abstraction we pursue in distributed systems.
Authenticated Link
When a system runs in an untrusted environment (such as the public Internet or blockchain) and faces Byzantine failures, “reliability” alone is not enough; “security” is also required. The challenges include:
- Man-in-the-middle attacks: an attacker intercepts a sent message, modifies its content, and sends it to the receiver.
- Data forgery: an attacker impersonates the sender and sends messages to the receiver.
Authenticated links were proposed to solve these problems. Their properties are:
- Integrity: the message has not been tampered with during transmission.
- Authenticity: the receiver can be sure the message really came from the sender.
The common SSL protocol implements authenticated links by establishing encrypted channels.
Among these network links, weaker links can be transformed into stronger links by adding technical means on top of the model, as shown in the figure below:
- By repeatedly retransmitting lost messages until they are delivered and filtering out duplicate messages at the receiver, a fair-loss link can be transformed into a reliable link.
- Using encryption technology, any link can be transformed into a fair-loss link. For example, the HTTPS protocol adds TLS encryption to HTTP (the “S” in HTTPS) to prevent attackers from eavesdropping on or tampering with messages. However, encryption cannot prevent messages from being dropped by the receiver; therefore, only when we assume the receiver will never block message communication can any link be transformed into a fair-loss link.
Note: Although the TCP protocol attempts to provide reliable-link guarantees, when designing distributed systems, do not naively assume that TCP is a “reliable link.” While TCP provides the abstraction of a reliable link while the connection is alive, once the connection is reset or the machine is rebooted, the TCP context is lost. Therefore, a true distributed system must implement a “reliable link” at the application layer:
- The application layer has its own request IDs for deduplication.
- The application layer has its own ACK mechanism to confirm successful business processing, not just TCP packet receipt.
- The application layer has its own retry strategy.
This is why RPCs in the Raft paper include Term and Index: these are the tools the application layer uses to build truly reliable links that span TCP connection lifetimes.
Failure Models #
In real systems, node and network failures may occur simultaneously. As shown in the figure below, Node A sends a request to Node B asking for the value of variable $x$. After receiving the request, Node B replies to Node A that the value of $x$ is 5.
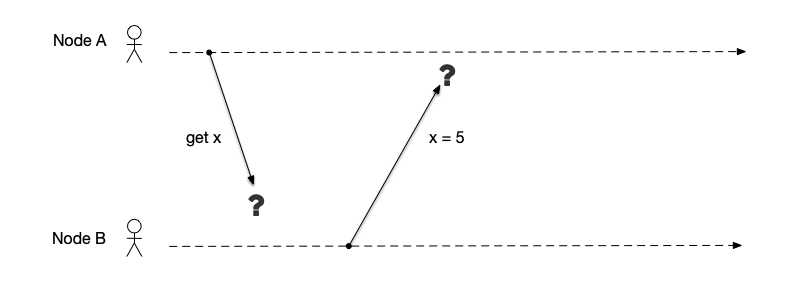
The following failures may occur during this simple communication process:
- Node B does not receive Node A’s request because of a communication failure.
- Node B crashes while processing the message and cannot reply.
- Node B receives the request only after a long delay because of network latency.
- Node B is too busy (for example, processing other transactions) to respond to the message.
- Node B maliciously replies with incorrect data to Node A.
- The message is lost during transmission or reception.
- When Node B replies, Node A crashes and cannot receive the reply.
- Etc.
It is clear that even in this simplest scenario, it is impossible to enumerate all possible failures. However, failures can be classified; different failure models have different design difficulties, and systems must be designed based on assumptions about a particular failure type.
Failure models define how badly machines, networks, and software can fail in the working environment of a distributed system. In the theory and practice of distributed systems, failure models form a hierarchy. From simple “crash” to complex malicious “tampering”, the difficulty of handling these failures increases exponentially.
Crash Model #
In a crash fault, a node may crash for various reasons, such as hardware failures or software bugs. Depending on whether a node can resume execution after a crash, crash faults are further divided into crash-stop faults and crash-recover faults.
Crash-Stop Model
In a crash-stop fault, it is assumed that after a node crashes, it never resumes execution. This is the most idealized model and usually exists only in theoretical derivations or extremely controlled hardware environments. Under this failure model, once a node fails, it immediately stops all operations; other live nodes in the system can accurately detect that the node has died. Algorithms for handling this failure model are very simple; for example, primary-backup failover is used. Once the primary node is detected to be down, the backup node immediately takes over.
This type of failure applies to unrecoverable hardware errors and some stateless services.
For example, certain simple layered Web services consist of a front-end API service and a back-end database service. If traffic increases, one scaling solution is to add additional front-end API services behind a load balancer. By adding API servers, more user requests can be accepted. In the design of such systems, a principle followed is to make the front-end services stateless. As the name implies, “stateless” means that when creating a process instance, no past data or state is stored, and no data needs to be persisted. Using stateless API services means that each individual API service does not track any user information outside the context of a single request. One advantage of stateless services is that they can be stopped at any time and started freely; no attempt is made to recover state upon startup, which facilitates seamless system scaling.
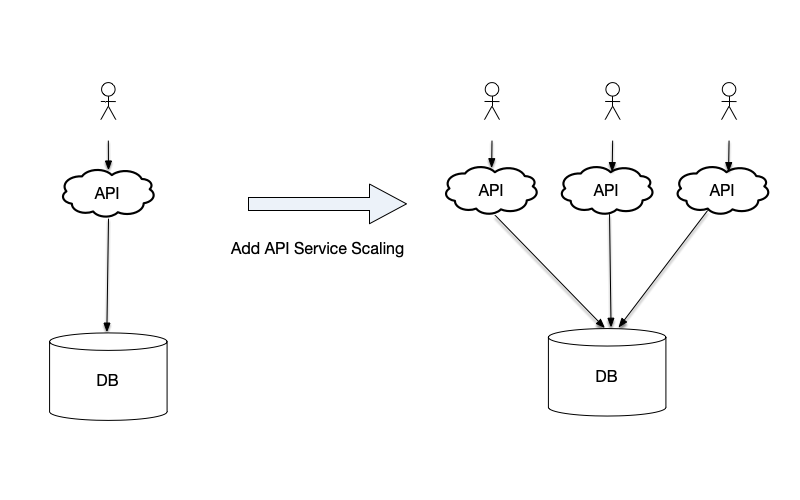
Another example is stateless services in Kubernetes. In Kubernetes’ stateless-node pattern, a service consists of multiple Pods. Each Pod runs only once during its lifecycle; once a Pod is restarted, it may be scheduled to run on another node. Each time a Pod is created, it is assigned a unique ID. If a node goes down, Pods scheduled to that node will be deleted after a timeout. If Pods are configured to restart after a failure, they will discard all data in memory when the failure occurs, and will not attempt to recover the state before the crash when restarted.
Crash-Recover Model
A crash-recover fault means that after a node crashes, it continues execution by restarting. In this failure model, we assume nodes may crash but can always recover within a certain time. If it is necessary to resume execution from the state before the crash, this can be done by reading persisted data. This is the core assumption model for distributed storage systems in industry. Under this model, the following phenomena may occur:
- Nodes may crash at any time and stop responding.
- Nodes may restart after a period of time and rejoin the cluster.
- A node’s “memory” may be lost: volatile state in memory, such as locks, caches, and uncommitted transactions, will all be lost.
Therefore, the core challenge for such systems is how a node obtains the latest state of the cluster after recovering from a crash:
- After restarting, the node’s state is stale. It must know how far behind it is and “catch up” from other nodes.
- If a node was a Leader node, after it crashes the cluster elects a new Leader. A moment later the old Leader restarts, still thinking it is the Leader and trying to give orders.
Database services are the most typical example of crash-recover fault services. When a process fails, the database loads its previous state by loading snapshot data before the crash and replaying the write-ahead log (WAL) [10], among other means, to recover the data from before the crash.
In Kubernetes, developers can use the StatefulSet type to create applications. Pods created in this way provide uniqueness guarantees that are preserved even after restarts and rescheduling. When an individual Pod fails, the Pod identifier can be used to read data from the existing data volume to recover state.
Omission Model #
An omission fault means that under certain circumstances a node omits sending or receiving some messages. Causes of omission faults usually include packet loss due to network instability and exhaustion of system resources.
This model is more subtle than the crash model. The node is still running, but it cannot send or receive messages normally. Its core challenges are:
- Ineffective failure detection: the node’s heartbeat packets may fail to go out, causing the node to be misjudged as “dead.” But in fact it is still writing to disk and still processing local logic. This can easily cause data inconsistency.
- Asymmetric network: Node A can send messages to Node B, but Node B cannot send messages to Node A.
To understand omission faults more intuitively, we can dive into the operating-system kernel and network-hardware layers. In engineering practice, omission faults often manifest as a “silent drop,” which is harder to debug than an explicit error:
- Receiver omission: when a node is under extremely high load (for example, CPU at 100% capacity), although the OS kernel is still running, it may not be able to process network-card interrupts in time. At this point, the network card’s hardware buffer (ring buffer) or the kernel’s receive queue fills up quickly. Once it overflows, the network card silently drops subsequently arriving packets at the hardware level. In this case, the application layer is completely unaware that messages have arrived, while from the sender’s point of view it is as if the messages have sunk into the ocean. At this point the node is still processing local disk I/O, but in the cluster network it has become a “black hole.”
- Sender omission: at the level of intermediate devices such as switches or routers, if transient micro-bursts occur that exhaust the switch port’s buffer, packets are also dropped by intermediate devices. Node A successfully calls the
send()interface and gets a successful return value (because the data was written to the local socket buffer), but the packet never actually reaches Node B.
Common technical solutions include:
- Retry and acknowledgment: every message must be confirmed by the receiver before it is considered successfully delivered. If no acknowledgment is received for a long time, the message is retransmitted, turning “omission” into “delay.”
- Lease: to perform a write operation, a valid lease must be held. If an omission fault prevents the lease from being renewed, the lease expires and the node is forced to stop serving (even if it thinks it is still alive).
Byzantine Model #
In the Byzantine fault model, a node may perform arbitrary actions, including crashes or malicious behavior. When designing algorithms for this model, no assumptions can be made about the behavior during a failure.
This model is the most general and also the hardest to design algorithms for. In terms of performance and storage cost, it is the most expensive. However, when unknown or unpredictable failures may occur, it is the only reasonable choice.
Note that the “arbitrary failures” mentioned here are not necessarily malicious or deliberate; they may also be caused by incomplete implementation, framework or system bugs, or hardware failures.
For example, in a decentralized network such as Bitcoin [11], there may be participants trying to cheat for profit. In such a system, trusting the messages or data of other nodes is unsafe. Bitcoin avoids this problem through proof of work (PoW) [12].
In the article “A Byzantine Failure in the Real World” [13], the Cloudflare team mentions a production incident in 2020 caused by an abnormal switch.
Failure Hierarchy
Failure models have the hierarchical relationship shown in the figure below. The innermost crash-stop model is the easiest to handle; the outermost Byzantine model is the hardest. If a system can handle the harder failure types in the outer layer, it can naturally handle those in the inner layer. For example, a system that can handle the crash-recover model can certainly handle the crash-stop model. We explain them from the inside out.
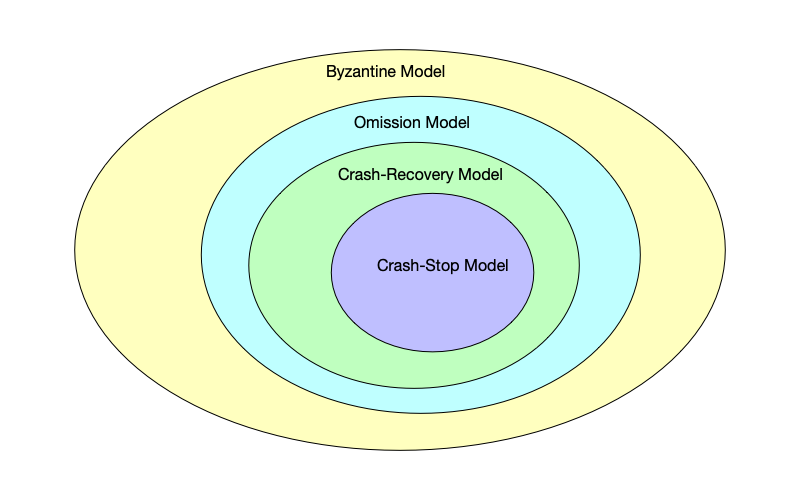
Crash-Stop Model
In the crash-stop model, after a node crashes it stops running and does not recover. Therefore, its set of failure behaviors is very small: only $\{Stop\}$.
Crash-Recover Model
In the crash-recover model, a node can recover and resume running after a crash. Therefore, the crash-stop model can be viewed as a special case where the recovery time is infinite. Its set of failure behaviors is $\{Stop, Restart\}$.
Omission Model
In the omission model, a node may drop sent messages or received messages. From this characteristic, the crash model is essentially an extreme case of the omission model. When a node crashes, it no longer sends messages or processes received messages. To an external observer, this is 100% send omission and 100% receive omission. In addition, the omission model allows nodes to be in certain intermediate states: for example, the network card is broken, so it can receive messages but cannot send them; or the CPU is busy and drops some packets.
In the crash model, once a node stops responding to messages, it can be safely assumed to be down or restarting. However, in the omission model, the same lack of response might simply mean that packets are being lost, even though the node is still alive and writing to disk. If the system incorrectly assumes the node is down and elects a new primary, it can lead to a split-brain scenario.
In summary, the set of omission-failure behaviors is $\{Stop, Restart, Drop\_Send, Drop\_Receive\}$.
Byzantine Model
The behavior pattern of the Byzantine model is that a node can send arbitrary data, including lies, forgeries, and contradictory messages. From this perspective, the omission model is just a special case: a Byzantine node can choose to “pretend not to have received a message” (simulating receive omission), or “pretend it cannot send a message” (simulating send omission), or “I simply crash” (simulating a crash). In addition, a Byzantine node can do things the omission model cannot: it does not drop messages, but it can tamper with them, for example changing “Agree” in a message to “Reject” before sending it to another node.
Although the omission model may drop packets, as long as a packet is received its content can be trusted; but in the Byzantine model, even if a node receives a packet it cannot trust it—signatures and tamper-proofing are required.
In summary, the set of Byzantine-failure behaviors is $\{Stop, Restart, Drop, Lie, Forge, \dots\}$, the union of all possible failures.
Engineers need to understand different failure models and their compatibility relationships to ensure that the designed system can correctly handle the failures that may occur in its environment, while also avoiding over-engineering, because the design difficulty varies greatly across failure models. For example, a system deployed in a trusted internal network does not need to be designed to satisfy the Byzantine-failure model; conversely, if a system is exposed to the public Internet where arbitrary nodes may join, it should be designed to satisfy the Byzantine-failure model.
Timing Models #
The assumed time bounds and communication delays of a system largely determine the algorithm used to solve the problem in the end. Timing models are generally divided into three types: synchronous, asynchronous, and partially synchronous. These three models determine how confident we can be about “delay”; this is the watershed between theory (e.g., the FLP impossibility result) and industry (e.g., Raft/Paxos).
Synchronous Model
The synchronous model is the most idealized and simplest, yet it is virtually nonexistent on the public Internet. It means that in a system, three physical properties have strict upper bounds:
- Bounded message-transmission delay: when a node sends a message, it is guaranteed to arrive within a known time $\Delta$. If $\Delta$ time passes without arrival, the system can conclude with 100% certainty that the network is broken or the other side has crashed.
- Bounded processor speed: the time for each machine to execute one step is predictable and will not be infinitely slow.
- Bounded clock drift: the clock discrepancy between any two machines will not exceed $\epsilon$.
These assumptions mean that failure detection for such a system is very simple.
Asynchronous Model
The asynchronous model represents the polar opposite of the synchronous model. It means that in a system, there are no limits on the three physical properties:
- Message delay has no upper bound: a message may wander in the network for 1 millisecond or 100 years; as long as it eventually arrives, it satisfies the model.
- Processing speed has no lower bound: a machine may suddenly be suspended by the operating system or enter a long GC pause, sleeping for several minutes before waking up.
In the asynchronous model, these assumptions imply:
- It is impossible to distinguish “slow” from “dead”: if Node A sends a message to Node B and gets no response, you never know whether Node B has crashed, the network is extremely slow, or Node B is processing complex computation.
- FLP impossibility: in an asynchronous system, as long as one node may crash, there is no deterministic consensus algorithm that can guarantee agreement is always reached.
Partially Synchronous Model
Both the synchronous and asynchronous models are too extreme; in most cases, systems operate under the partially synchronous model, which is the main battlefield of industry. Its core characteristic is that the system behaves like a synchronous system most of the time, but behaves like an asynchronous system during unpredictable, finite periods.
There are many reasons why a system may violate synchronous assumptions. We list some common ones below:
- Messages need to be retransmitted after being lost, especially in the case of network partitions, where the upper bound of delay may be infinite.
- Network congestion also causes message delays, because packets queue in switch buffers.
- Network reconfiguration may also cause large delays. In a 2012 incident at GitHub [14], packets within a single data center were delayed by more than one minute.
- When executing algorithms on a node, the expected speed is constant, because each instruction has a fixed number of CPU clock cycles. But there are also factors that may cause a running program to pause for a long time. Some possible reasons are:
- The OS kernel scheduler may preempt some running processes, pausing their execution to let other processes run.
- In garbage-collected languages such as Java, system pauses caused by garbage-collector runs (stop-the-world, STW).
- When remaining memory is insufficient, page faults and memory swapping that may occur when a program requests memory from the kernel can cause a process to be suspended.
Chapter Summary #
This chapter serves as the theoretical foundation of the book. It focuses on how to abstract and model complex distributed-system environments. We established that, unlike single-node systems, distributed systems lack shared memory and global clocks, and they must confront inherent uncertainties in network and node behavior. To meet these challenges, we use thought experiments and theoretical models to define the boundary conditions that must be considered when designing systems.
This chapter first uses the two classic generals’ problems to reveal the two most fundamental difficulties in distributed systems:
- Two Generals’ Problem (uncertainty of the network): demonstrates the “infinite acknowledgment” trap encountered when trying to reach consensus over an unreliable channel. It proves that in an unreliable communication environment, absolute consensus cannot be reached through a finite number of message exchanges. Although the TCP protocol alleviates this problem through sequence numbers and retransmission mechanisms, it is only a partial engineering solution, not a complete theoretical solution.
- Byzantine Generals’ Problem (untrustworthiness of nodes): demonstrates the challenges when malicious nodes (traitors) in the system tamper with or forge messages. Theory proves that in a system containing malicious nodes, consensus is possible only when the number of malicious nodes is less than one-third.
To analyze system behavior more precisely, we define three core models that together form the environmental assumptions for distributed-algorithm design:
- Communication model: we introduced fair-loss links, reliable links, and authenticated links. Although TCP provides reliable transport while a connection is alive, true distributed “reliable links” must be implemented at the application layer, including request-ID deduplication, application-layer ACKs, and retry strategies, to cope with connection resets and context loss after machine restarts.
- Failure model: we built a failure hierarchy from simple to complex.
- Crash-stop: the simplest model, applicable to stateless services.
- Crash-recover: the most common model in industry (e.g., databases, Kubernetes), where nodes may restart and face state loss and catch-up problems.
- Omission faults: nodes may drop received messages or fail to transmit them, making failure detection notoriously difficult.
- Byzantine fault: the most complex failure model, where nodes may arbitrarily lie or behave maliciously, encompassing all the failure types above.
- Timing model: the timing model determines the basis on which algorithms judge “timeout.”
- Synchronous model: strict upper bounds on delay, speed, and clock drift; extremely rare in practice.
- Asynchronous model: no upper bound on message delay, making it impossible to distinguish a “slow” node from a “dead” one.
- Partially synchronous model: the main battlefield of industry, assuming the system is synchronous most of the time but allowing brief asynchronous periods (such as network congestion or STW caused by GC).
Through the study of this chapter, we have not only mastered the theoretical terminology but, more importantly, understood the trade-offs between models. When designing a system, engineers must be clear about the environmental model they are in: are they handling crash-recovery in a trusted internal network (e.g., Raft), or defending against Byzantine attacks in an open network (e.g., blockchain)?
References #
-
Wikipedia: “Two Generals’ Problem”
-
E.A. Akkoyunlu, K. Ekanadham, and R.V. Huber: “Some Constraints and Trade-offs in the Design of Network Communications,” at Proceedings of the Fifth ACM Symposium on Operating Systems Principles (SOSP ‘75), Austin, Texas, USA, 1975.
-
Jim Gray: “Notes on Data Base Operating Systems,” 1978.
-
Wikipedia: “Transmission Control Protocol”
-
W. Richard Stevens: “TCP/IP Illustrated, Volume 1: The Protocols,” Addison-Wesley, 1994.
-
Wikipedia: “Byzantine fault”
-
Leslie Lamport, Robert Shostak, and Marshall Pease: “The Byzantine Generals Problem,” ACM Transactions on Programming Languages and Systems (TOPLAS), volume 4, number 3, pages 382–401, July 1982. doi:10.1145/357172.357176
-
Cynthia Dwork, Nancy A. Lynch, and Larry Stockmeyer: “Consensus in the Presence of Partial Synchrony,” Journal of the ACM, volume 35, number 2, pages 288–323, April 1988. doi:10.1145/42282.42283
-
Peter Bailis, Kyle Kingsbury: “The Network Is Reliable,” ACM Queue, volume 12, number 7, pages 20–32, July 2014. doi:10.1145/2639988.2655736
-
Wikipedia: “Write-ahead logging”
-
Satoshi Nakamoto: “Bitcoin: A Peer-to-Peer Electronic Cash System,” 2008.
-
Wikipedia: “Proof of work”
-
Cloudflare: “A Byzantine Failure in the Real World”
-
GitHub Blog: “Downtime Last Saturday”