So far, we have introduced replication and partitioning. Replication (including the consensus algorithms) improves system fault tolerance, while partitioning improves system scalability; these two techniques address the physical problems of data. In addition, data access in distributed systems often faces “logical problems”, which are solved by the transaction technology introduced in this chapter:
- Replication: The main goal is high availability and data redundancy. By storing identical copies of data on different nodes, when one node fails, the system can continue to provide service from other replicas. It answers the question: “Will my data be lost or inaccessible because one machine goes down?”
- Partitioning (Sharding): The main goal is scalability. When a single node’s storage or computing capacity cannot handle all the data and requests, we horizontally split the data across multiple nodes. It answers the question: “How does my system handle ever-growing data volumes and access pressure?”
- Transaction: The main goal is the correctness of data operations. It packages a series of operations into an indivisible logical unit, ensuring that these operations either all succeed or all fail, and that they do not interfere with each other when executed concurrently. It answers the question: “How can I ensure that a series of related operations maintain data correctness under any circumstances (concurrency, failures)?”
Why are replication and partitioning alone not enough? Let us look at a few typical scenarios:
Scenario 1: Bank Transfer (The consequences of lacking atomicity)
User A wants to transfer 100 to User B. This operation consists of at least two steps:
- Deduct 100 from User A’s account.
- Add 100 to User B’s account.
In a distributed system lacking transaction technology, the following problems may occur:
- Failure: The system crashes after completing step 1 (for example, the database node goes down). At this point, A’s money has been deducted, but B has not received it. The money has “vanished into thin air.” Even if the data has multiple replicas (replication technology), all replicas record this erroneous “intermediate state.”
- Cross-partition operation: Suppose User A’s data is in partition 1 and User B’s data is in partition 2. This transfer operation requires a coordinator to notify the two partitions to execute the operation separately. If partition 1 successfully deducts the amount, but partition 2 fails to receive it due to network issues or its own failure, data inconsistency will also result.
However, if transaction technology is used, the atomicity of the transaction guarantees that this series of operations is an “all-or-nothing” atomic unit. The system ensures that the two steps of “deduction” and “deposit” either both complete, or, if anything goes wrong in the middle, all completed steps are rolled back (Rollback), restoring the system state to what it was before the operation began. This ensures that money never disappears or appears out of nowhere.
Scenario 2: Concurrent Flash Sales (The chaos of lacking isolation)
On an e-commerce website, only one item of a certain product remains in stock. At this moment, two users (User C and User D) click the “Buy” button simultaneously.
In a distributed system lacking transaction technology, the following problems may occur:
- User C’s request arrives; the system reads the stock as 1.
- Before User C’s request completes the “deduct stock” operation, User D’s request also arrives; the system still reads the stock as 1.
- User C’s request executes “deduct stock,” and the stock becomes 0.
- User D’s request also executes “deduct stock,” and the stock becomes -1 (overselling).
- The final result: both users believe they have bought the product, while the system stock shows a negative number. This causes a serious business logic error.
However, if transaction technology is used, the isolation of the transaction ensures that multiple concurrently executing transactions do not interfere with each other, as if they were executed serially. When User C’s transaction begins processing the stock, it locks that data. User D’s transaction cannot modify the stock data until User C’s transaction completes (commits or rolls back); it either waits or reads an old value and then fails. This ensures that only one person can successfully buy the product in the end.
Scenario 3: Data integrity after a system crash (The risks of lacking durability)
An order system has just completed the creation of an important order, and all data has been written. At the moment data is flushed from memory to disk, the server loses power.
In a distributed system lacking transaction technology, if the system relies on the operating system’s buffered writes, the order data may be permanently lost. Although you may have received an “operation successful” response, the data has not actually been persisted.
The durability of transactions guarantees that once a transaction is committed, its result is permanent. Even if the system crashes, the data can be recovered. This is usually achieved through mechanisms such as Write-Ahead Logging (WAL): before modifying the data itself, the operation is first recorded in a persistent log.
We can imagine a distributed system as a large, cross-departmental company project:
- Replication technology ensures that every department has backups of core members, or complete copies of project documentation. If a core member takes leave or leaves, a backup personnel can step in to ensure the department’s work is not interrupted (high availability).
- Partitioning technology splits the project among different departments (front-end, back-end, database), improving the company’s overall processing capacity (scalability).
- Transaction technology is a “workflow” or “process rule” in project management. For example, the “product launch” workflow must include: 1. successful code deployment, 2. successful database migration, 3. successful CDN cache refresh. This workflow stipulates that all three things must be completed before the “product launch” is considered truly successful. If any step fails, the entire launch process must be rolled back to its initial state (for example, code rollback, database recovery), and it must never stop in an awkward “half-deployed” state.
In addition, transactions provide application developers with a simplified programming model. Imagine that without the various guarantees of transactions, application developers would need to:
- Manually handle rollback logic under various failure scenarios.
- Manually acquire locks to avoid concurrent conflicts.
- Write complex compensation code to repair data inconsistencies caused by partial failures.
This would make business code extremely complex, error-prone, and difficult to maintain. Transactions encapsulate all this complexity and provide developers with a simple abstraction: “You can treat a series of operations as an indivisible unit, and the system guarantees its ACID properties.” This greatly improves development efficiency and application reliability.
In this chapter, we start our discussion of transaction ACID properties from single-node database transactions, and then extend to distributed transactions involving multiple services. In distributed systems, because operations may span multiple services (for example, an e-commerce purchase involves order service, inventory service, and payment service), they face greater challenges:
- The network is unreliable, and delays, partitions, and packet loss may occur.
- Nodes may fail; servers may go down, and processes may crash.
- There is a risk of data inconsistency, where some operations succeed and some fail (for example, the order is created successfully, but inventory deduction fails).
Understanding ACID in Depth #
In a single-node database, various failures can occur:
- The database is writing data when the system crashes; after restarting the database, how to recover from the corrupted data.
- Multiple clients write multiple data items simultaneously; for example, in the e-commerce purchase example at the beginning of this chapter.
To protect application developers from being troubled by these failures, transaction technology has always been the preferred mechanism of database systems. Transaction technology provides application developers with the ACID safety guarantee. Let us first understand these properties. ACID was first proposed in [1] as a precise description of database fault-tolerance mechanisms; it is an acronym of the following four words:
- A (Atomicity): Atomicity. A transaction guarantees that modifications to multiple data items either all succeed or all fail.
- C (Consistency): Consistency. Before and after executing a transaction, the database must be in a correct state satisfying integrity constraints.
- I (Isolation): Isolation. When multiple transactions execute concurrently, the execution of one transaction should not affect the execution of other transactions.
- D (Durability): Durability. After a transaction completes, the modifications to data are permanent, even if the system fails.
Overall, the ACID properties provide a mechanism that makes each transaction act as a unit, complete a set of operations, produce consistent results, be isolated from other transactions, and have updates take effect permanently, thereby ensuring database correctness and consistency.
The following uses the bank transfer example to illustrate transaction properties. Transactions are usually marked by BEGIN and END to indicate start and end. Suppose the balances of users x and y are both 10, and the following two transactions T1 and T2 execute concurrently:
T1: T2:
BEGIN BEGIN
add(x, 1) x1 = get(x)
add(y, -1) y1 = get(y)
END print x1, y1
END
Atomicity and Durability #
Atomicity and Durability in ACID are closely related; together they form the cornerstone of transaction reliability. They act on the two complementary scenarios of transaction “failure recovery” and “success persistence”, so that the database can maintain a predictable state whether it succeeds or fails. Together, they ensure that the database will neither have incomplete operations nor lose already-confirmed operation results. These two properties together constitute the core of transaction reliability:
- Atomicity focuses on the logical correctness of transaction execution: either do it all or do none of it, never leaving an intermediate state. If any exception occurs during transaction execution (statement error, deadlock, crash, etc.), atomicity requires that all modifications already made must be undone, and the database returns to the state “this transaction never happened.”
- Durability focuses on the physical reliability of transaction results: once successful, the result is never lost, even if power is lost or a crash occurs immediately afterwards.
In short, atomicity handles failures, while durability secures successes. Only with their cooperation can consistency and recoverability of transactions under arbitrary failure scenarios be achieved. For example, in a bank transfer transaction:
- Atomicity ensures that “deducting from account x” and “depositing into account y” either both succeed or both fail.
- Durability ensures that if both operations succeed, even if the system crashes immediately, the transfer result can be recovered.
Without atomicity, it would be impossible to determine which operations have been successfully executed, and durability could not be correctly applied; without durability, even if a transaction satisfies atomicity, its result could be lost after a system failure. Next, we analyze their principles in detail.
Atomicity
Atomicity stipulates that all operations contained within a transaction must be treated as an indivisible whole. The whole ultimately has only two states: all operations succeed or no operations execute; the system never allows staying in a “half-done” intermediate state, so it is also called “All or Nothing.”
- If all operations succeed, we call it Commit.
- If no operations are executed (that is, undo all operations already performed and restore the state before the transaction began), we call it Rollback.
Taking the bank transfer example above, if atomicity is violated (for example, the system crashes after completing step 1), account A has less money, but account B has not increased. This is not only data inconsistency, but also a serious business error that causes the bank’s balance sheet to be out of balance.
Atomicity ensures that no matter what failure occurs (application crash, database downtime, network interruption), the result of this transfer transaction can only be:
- Successful commit: the balance of x decreases by 1, and the balance of y increases by 1.
- Transaction abort (Rollback): the balances of x and y remain unchanged, as if the transfer never happened.
The implementation of atomicity mainly relies on the database’s log mechanism, especially the Undo Log. Its working principle is as follows:
- Transaction start: The system starts a new transaction.
- Before modifying data, record the “reverse operation”: This is the so-called undo log, used to roll back the corresponding operation when the transaction is aborted. In a transaction, when the database wants to modify a piece of data (for example, the balance of x changes from 10 to 9), it does not directly modify the original data. Instead, it first records a “reverse operation” log in the undo log, such as: “Change A’s balance from 9 back to 10.”
- Execute data modification: After recording the undo log, the modification is performed on the data page in memory, updating the balance of x to 9.
- If everything is normal, the transaction will commit: If all operations in the transaction complete successfully, the transaction manager commits the transaction. At this point, the undo log may be marked as discardable.
- If any error occurs during transaction execution, the transaction will roll back (Rollback): During rollback, it finds transactions that have not yet committed and uses the corresponding undo logs to execute reverse operations, thereby restoring all modified data to the state before the transaction began. For example, it reads the log “Change x’s balance from 9 back to 10” and executes it to restore account A’s data.
In distributed systems, implementing atomicity is more complex and usually requires Two-Phase Commit (2PC) or its variants (such as 3PC, Paxos, Raft) to coordinate all participating nodes, ensuring that they either commit together or roll back together.
Durability
Durability guarantees that as long as a transaction commits successfully, the changes it makes to the database are permanent. Even if any failure occurs afterwards (such as database server power loss, operating system crash), the committed data will never be lost. Durability is the system’s ultimate promise of data reliability. Imagine:
- You just placed an order on an e-commerce website, and the system prompts “Order placed successfully.” If the order data is not persisted, after the server restarts, your order disappears.
- You just stored important files in cloud storage, and the system shows “Upload complete.” Without durability, a data-center power outage could cause your files to be permanently lost.
Durability ensures that the “success” receipt given by the system is authentic and trustworthy.
The implementation of durability also relies on logs, but unlike atomicity, durability relies on the Redo Log, and the core idea of implementing this mechanism is Write-Ahead Logging (WAL). The core principle of WAL is: when modifying data, write the log first, then modify the data. The working principle is as follows:
- Data modification generates a write-ahead log: When a transaction wants to modify data, it first generates a write-ahead log in memory, recording “what modification to make,” for example: “At offset Y of data page X, change the value from A to B.”
- Log is written to disk first: Before modifying the data page in memory, this write-ahead log must be written to the log file on disk and ensure that the flush to disk succeeds (fsync). This is a sequential append operation and is very fast.
- Modify the in-memory data page: After the log is persisted, the system performs the actual modification on the in-memory data page.
- Return a success response: Once the write-ahead log has been successfully written to disk, the system can return a “transaction commit successful” response to the client.
With the support of write-ahead logging, the modified data pages in memory (called dirty pages) do not need to be written to disk immediately. The database can asynchronously flush these dirty pages to disk according to its own strategy (such as batching, or when the system is idle). This is a random-write operation and is relatively slow.
With write-ahead logging, how do we recover data after a crash?
Suppose the database server suddenly loses power between step 4 and step 5. At this point, all modifications in memory are lost, but the Redo Log recorded on disk is intact. When the server restarts, the database performs a recovery process:
- Read the write-ahead log.
- It finds that a certain transaction has committed (because the log contains a commit record), but the corresponding data page may still be old (because it was not flushed to disk in time). The database re-executes the modification operations according to the contents of the write-ahead log (this is the meaning of “Redo”), restoring the data to the correct state before the crash.
Because the log is written in advance, any committed transaction modifications can be recovered by replaying the log, thereby guaranteeing durability.
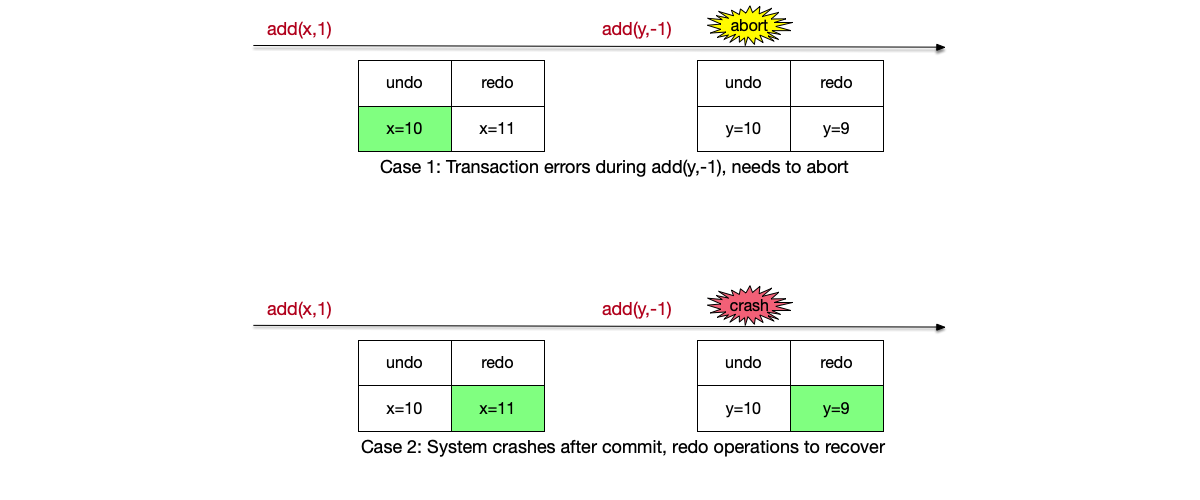
The table below summarizes the undo and redo log contents corresponding to the two operations in the bank transfer example. The figure below illustrates how these two types of logs resolve transaction abort and crash recovery; the green logs indicate operations to be redone:
| Operation | Undo Log | Redo Log |
|---|---|---|
add(x,1) |
x=10 | x=11 |
add(y,-1) |
y=10 | y=9 |
- Transaction abort: Case 1 in the figure. The transaction successfully executes
add(x,1), but fails when executingadd(y,-1). As a guarantee of transaction atomicity, all operations of the transaction must succeed or fail, so the previously successful operation needs to be rolled back. At this point the values of the two variables are x=11 and y=10; sinceadd(y,-1)was not successfully executed, the abort operation only needs to use the undo operation ofadd(x,1)(i.e., x=10) to restore the state before transaction execution, x=10 and y=10. - Crash recovery: Case 2 in the figure. Both operations of the transaction execute successfully, and the transaction is also committed successfully, but the system crashes at this time. As a durability guarantee, once the transaction commits successfully, the successfully executed transaction state must be preserved even if the system crashes. After the system recovers, it needs to redo all operations of the transaction according to the redo log, finally obtaining the state after successful transaction execution, x=11 and y=9.
Isolation #
Transaction isolation means that concurrently executing transactions must not interfere with each other; that is, the operations and data used inside one transaction are isolated from other concurrently executing transactions. There are different transaction isolation levels; among these, the most classic isolation level is Serializable, which guarantees that the final result of multiple concurrently executing transactions is exactly the same as the result of executing them one after another in some order. It provides each transaction with the illusion that it is the only transaction running in the system throughout its execution, and it cannot see the intermediate states of other transactions.
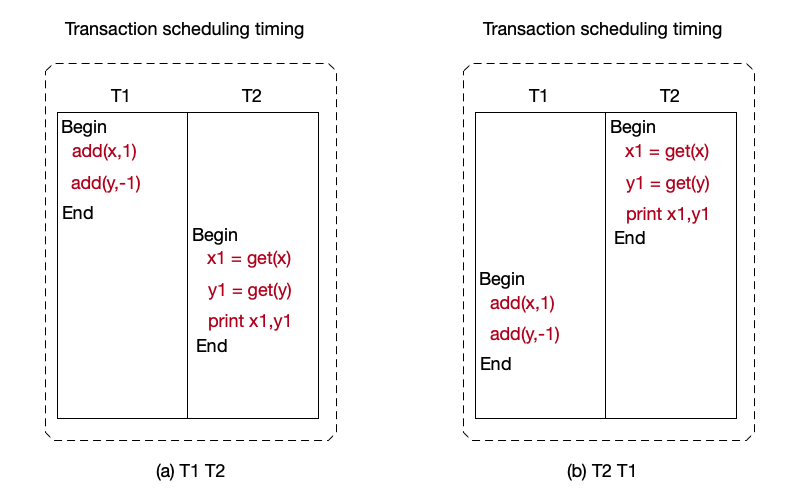
The following example illustrates the concept of serializability. Suppose the balances of users x and y are both 10, and the following two transactions T1 and T2 execute concurrently:
As shown below, the possible serial execution orders are:
- T1 T2: T2 prints “11,9”, and the final result is x=11, y=9;
- T2 T1: T2 prints “10,10”, and the final result is x=11, y=9.
If the operations in the two transactions are interleaved, serializable isolation is not satisfied. For example, if the operations of transactions T1 and T2 are interleaved as shown below:
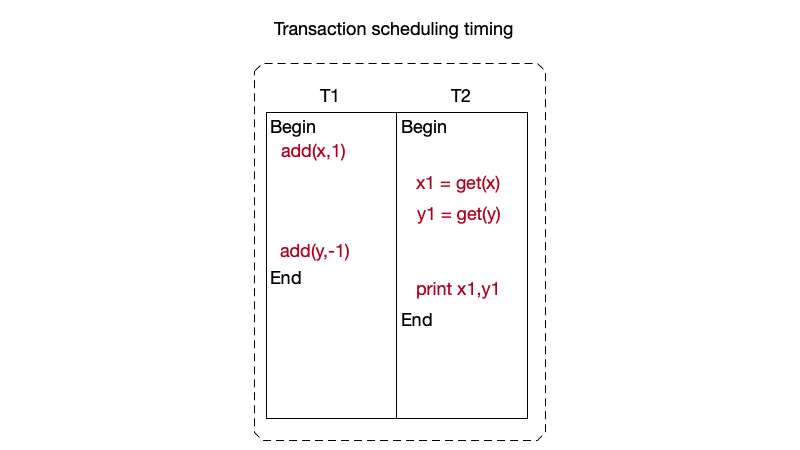
In this case, the output result is “11,10”. Although the final result after all operations are completed is also x=11, y=9, this does not conform to the serializability rule.
From the above, we can see that serializability requires concurrently running transactions to execute one after another, which affects system performance. Fortunately, database transactions have different isolation levels[2]; the serialization method introduced above is the strongest isolation level. In addition, databases provide other isolation levels of varying strength for application developers to choose the most suitable level according to different scenarios.
In order to better use databases, developers need to understand the various anomalies that may occur during concurrent transaction execution, as well as the isolation levels used to avoid these anomalies. Let us start with the various anomalies.
Dirty Read
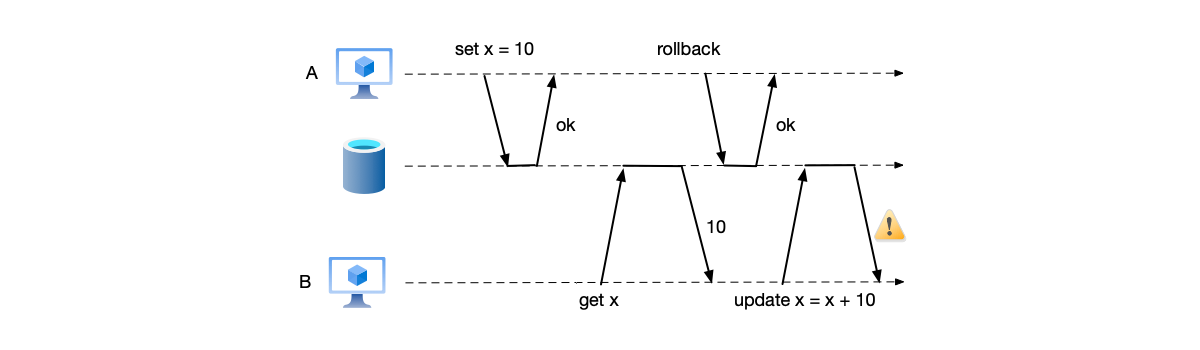
Dirty read refers to a situation in which, when multiple transactions operate on the same data simultaneously, one transaction A reads data that another transaction B has not yet committed. If A ultimately rolls back for some reason, then B has read a piece of “dirty” data that never really existed, and may make incorrect subsequent operations based on this dirty data, for example:
- When a transaction has multiple update operations, other transactions read partially updated data;
- When a transaction is interrupted and rolled back, other transactions read the rolled-back value and use it as the basis for subsequent operations.
As shown below, transaction A modifies the value of x to 10. Before this transaction commits, transaction B reads this value and executes an update operation based on it, but transaction A ultimately fails to commit, causing transaction B’s modification operation to be invalid.
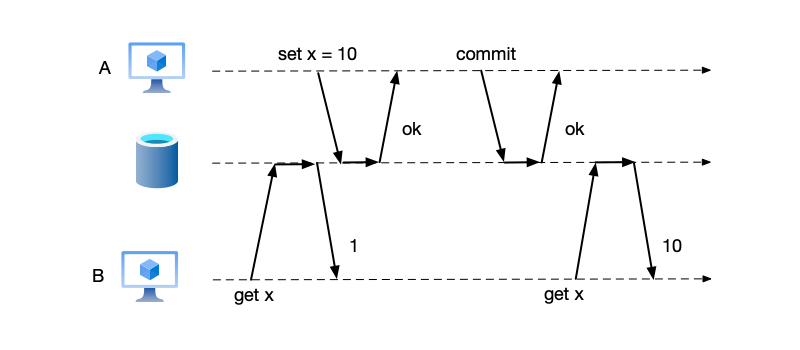
Non-Repeatable Read
Non-repeatable read refers to the situation in which, during the execution of the same transaction, two reads of the same row of data yield inconsistent results. This is because, between the two reads in the transaction, another transaction committed a modification (UPDATE) or deletion (DELETE) of that data, which destroys the logical consistency within the transaction.
As shown below, the initial value of x is 1. Transaction A modifies the value of x to 10. Before and after this transaction commits, transaction B reads different values. This phenomenon in which the same data is read multiple times within the same transaction and yields different results is called non-repeatable read, also known as fuzzy read.
The issue with non-repeatable reads is that a transaction may read inconsistent data at different times during its execution. In some scenarios, this is not a serious problem, for example:
- Reading some non-critical data: For example, some social applications read the same user’s preferences, browsing history, and other non-critical information multiple times within the same transaction; such scenarios can generally tolerate data inconsistency before and after within the same transaction.
- Cache update: For example, e-commerce platforms put product description information into caches; such cache updates have a time window, and changes in product descriptions before and after are acceptable.
However, there are also many scenarios where non-repeatable reads must be avoided. The characteristic of such problems is that they require ensuring data integrity before and after within the same transaction, for example:
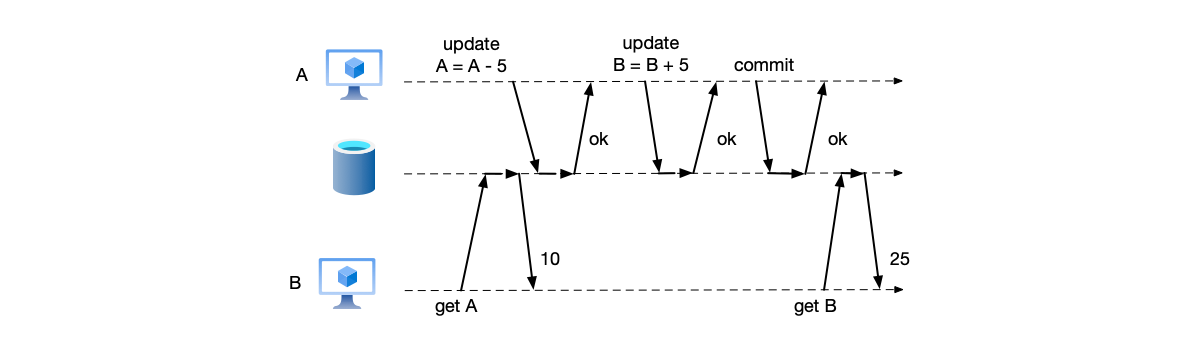
- Financial scenarios: For example, in a transfer between two users, the data-integrity requirement is that the sum of the balances of the two accounts before and after the transfer remains consistent. As shown below, the initial balances of accounts A and B are 10 and 20 respectively, but when user B checks the balances of accounts A and B before and after, the values obtained are 10 and 25, which is inconsistent with the initial total of 30.
- Inventory management: E-commerce platforms must ensure consistency of inventory data before and after; in this scenario, the data-integrity requirement is that the sum of items for sale and items sold remains consistent before and after.
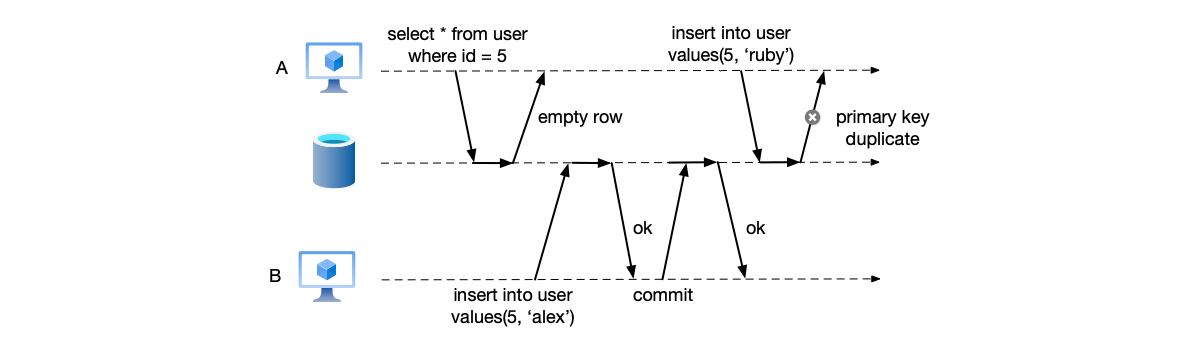
Phantom Read
Phantom read refers to the situation in which, during the execution of the same transaction, two queries executed with the same query condition return different numbers of rows.
Phantom reads and non-repeatable reads look very similar: both involve reading different data before and after within the same transaction. The difference between the two is:
- Non-repeatable read: the value of a single row of data is modified.
- Phantom read: the number of rows (or the set itself) of a batch of data has increased or decreased.
As can be seen, non-repeatable reads focus on the case where the same data is modified, while phantom reads focus on the case where a data set changes.
As shown below. Transaction A first queries the data with id=5 and gets an empty result set; transaction A believes that id=5 is not occupied. However, before it writes the data with id=5, transaction B writes the data with id=5, causing transaction A’s write to fail.
Having understood the common problem types in concurrent transactions, let us now look at the different isolation levels designed in databases, arranged from weak to strong as follows:
Read Uncommitted
Read uncommitted is the weakest isolation level, providing no guarantees; dirty reads, non-repeatable reads, phantom reads, and other anomalies can all occur at this isolation level. Therefore, it is rarely used and usually only in scenarios with extremely low data-accuracy requirements.
Read Committed
Read committed is the default isolation level in most databases. This level stipulates that a transaction can only read data committed by other transactions; therefore, dirty reads are eliminated at this level, but non-repeatable reads and phantom reads may still occur.
Repeatable Read
Repeatable Read is a stronger isolation level than read committed. This level guarantees that, within the same transaction, multiple reads of the same row of data yield consistent results. At this level, dirty reads and non-repeatable reads are eliminated, but phantom reads may still occur.
Among all isolation levels, the strongest is Serializable; this level eliminates dirty reads, non-repeatable reads, and phantom reads, but correspondingly, the degree of parallelism of serializability is also the lowest.
| Isolation Level | Dirty Read | Non-Repeatable Read | Phantom Read |
|---|---|---|---|
| Read Uncommitted | ✗ Possible | ✗ Possible | ✗ Possible |
| Read Committed | ✓ Avoided | ✗ Possible | ✗ Possible |
| Repeatable Read | ✓ Avoided | ✓ Avoided | ✗ Possible |
| Serializable | ✓ Avoided | ✓ Avoided | ✓ Avoided |
Consistency #
Above we have interpreted three properties of ACID; now let us analyze the most special and most easily misunderstood member of ACID: C - Consistency. Among the four ACID properties, A (Atomicity), I (Isolation), and D (Durability) are mainly technical guarantees provided by the database system. C (Consistency), on the other hand, is more like a business goal, a final effect achieved jointly by A, I, and D combined with application-layer logic.
The core idea of consistency in ACID is: The execution of a transaction must not destroy the integrity of database data and business rules. In other words, regardless of whether the transaction can commit successfully, before and after the transaction executes, the database must be in a valid state.
- What does a “consistent state” mean? It means that data must satisfy all preset rules and constraints. These rules can be at the database level or at the application level. These constraints include primary-key constraints, foreign-key constraints, uniqueness constraints, check constraints at the database level, as well as business-rule constraints at the application level.
- Transaction intermediate state: During transaction execution, data may temporarily be in an inconsistent (invalid) intermediate state. However, because of transaction atomicity and isolation, this intermediate state is invisible to other transactions. When the transaction finally commits, it must ensure that the data has returned to a new, consistent state.
In previous chapters, we have seen the word “consistency” in many places:
- In the consistency models section, various consistency models were discussed in detail.
- In the CAP theorem section, the “C” also stands for consistency, referring to linearizability.
However, consistency in ACID is very different from consistency in the consistency models discussed earlier:
- Consistency in ACID refers to the data inside a single database node conforming to predefined business rules and constraints (for example, the total amount in bank accounts cannot be negative). It focuses on the logical correctness of data.
- Consistency in CAP theory refers to data replicas among multiple nodes in a distributed system being the same value at any moment. It focuses on the synchronization and visibility of data among different replicas.
In simple terms, consistency in ACID focuses on “whether the business logic is correct,” while consistency in CAP focuses on “whether the data of each replica is the same.”
The guarantee of consistency in ACID is a layered, collaborative process:
- Database level: The database enforces some data rules through built-in functions; this is the lowest-level, strongest guarantee. This includes:
- Database built-in constraints; for example, if a primary key is declared, the database will ensure that the primary key is unique and non-null; if a foreign key is declared, the database will ensure that the foreign key points to a real existing primary key, ensuring that the relationship between the two is valid.
- In addition, the A, I, and D properties provided by the database are the cornerstone for achieving consistency.
- Application level: Many complex business rules cannot be understood by the database and must be guaranteed by the application program.
- Business logic: For example, in a banking system, “the total deposits of all current accounts must equal the current deposit total recorded in the bank’s general ledger.” The database itself cannot verify this rule; the application program must ensure it through calculation in every deposit and withdrawal operation.
- Transaction orchestration: The application program is responsible for beginning (
BEGIN TRANSACTION), committing (COMMIT), or rolling back (ROLLBACK) transactions, packaging a series of operations to ensure they jointly satisfy business consistency requirements.
Still using the bank transfer example above to illustrate how the system guarantees business consistency. The consistency rule for bank transfer business is: at any time, the total assets of all accounts remain unchanged. The process of using a transaction for transfer is as follows:
- Initial state: The balances of users x and y are both 10; the total assets add up to 20. Whether the transfer ultimately succeeds or not, the business consistency rule that total assets must be 20 must be satisfied.
- Execute transaction:
- Deduct 1 from user x’s account. At this point the internal state of the database is: account x is 9, account y is 10. It can be seen that at this moment the sum of the two account balances is 19, which is a transient, inconsistent intermediate state that does not satisfy the business consistency requirement above. However, because of isolation in ACID, other concurrent transactions cannot see this state; what they see is still the state before the transaction began: both users x and y have balances of 10.
- Add 1 to user y’s account. After executing this operation, the requirement that the total account assets be 20 is satisfied, and the data reaches a new state that satisfies the business rules.
- Transaction commit.
- Final consistent state: The final state is account x at 9 and account y at 11, satisfying the consistency rule that total assets are 20.
If a failure occurs in the middle (for example, a crash after operation 1), atomicity intervenes, rolling back all operations and restoring the database to the initial consistent state x=10, y=10. Durability ensures that once the commit succeeds, the new state x=9, y=11 is permanently saved.
To summarize, consistency in ACID is the ultimate goal of the system; it requires that data satisfy all preset business rules and integrity constraints before and after a transaction, and it is a business-level correctness that needs to be jointly guaranteed by the database and the application program.
Concurrency Control #
Concurrent access mechanisms can be broadly divided into two categories: pessimistic and optimistic. The pessimistic approach assumes that conflicts between transactions occur frequently, so it acquires locks before accessing resources to avoid conflicts; the optimistic approach assumes that conflicts between transactions do not occur frequently, so transactions can access resources without locks and finally determine whether there are conflicts to resolve.
According to these two divisions, this section introduces several common concurrency control mechanisms:
- Pessimistic approach: Two-Phase Locking;
- Optimistic approach: Optimistic Concurrency Control, Multi-Version Concurrency Control.
Although the optimistic approach can access resources without locks, this does not mean that the optimistic approach is necessarily more performant than the pessimistic approach. As we will see, every optimistic concurrency control mechanism must be paired with a corresponding conflict resolution solution. When resource contention is fierce, the optimistic approach can instead be slower, as a large amount of time is consumed in conflict resolution.
Two-Phase Locking #
Two-Phase Locking (2PL)[3] divides the lock-acquisition operations of a transaction into two phases to manage the transaction’s access to shared resources. Specifically, there are two types of locks; the compatibility of these two types of locks is shown below:
- Shared Lock: Allows multiple transactions to read data simultaneously.
- Exclusive Lock: Allows only one transaction to modify data.
| Shared Lock | Exclusive Lock | |
|---|---|---|
| Shared Lock | ✓ | ✗ |
| Exclusive Lock | ✗ | ✗ |
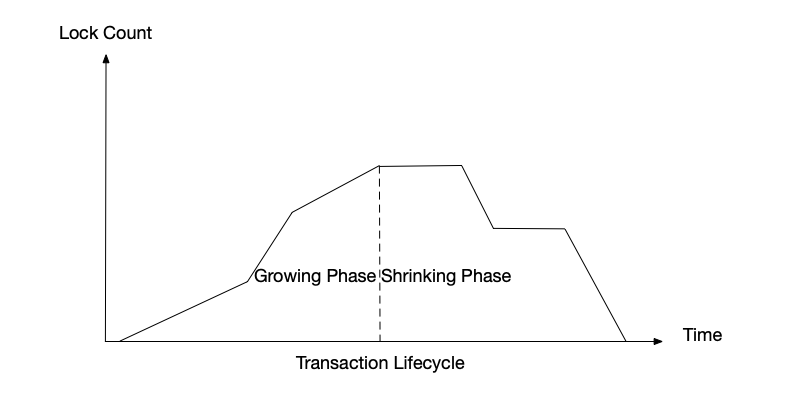
The two-phase locking protocol divides the lock acquisition and release operations of a transaction on shared resources into two distinct phases:
- Growing Phase: The transaction can acquire locks, but cannot release any locks.
- Shrinking Phase: The transaction can release locks, but cannot acquire any new locks.
Once a transaction enters the shrinking phase, it can no longer request new locks until the transaction ends.
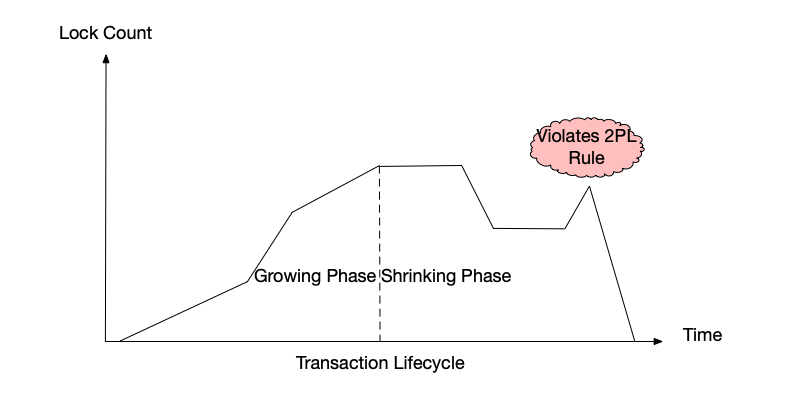
According to this rule, after a transaction enters the shrinking phase, the number of locks can only gradually decrease, as shown below.
As shown below, when a transaction’s locks begin to decrease and enter the shrinking phase, if the number of locks subsequently increases, it violates the two-phase locking rule.
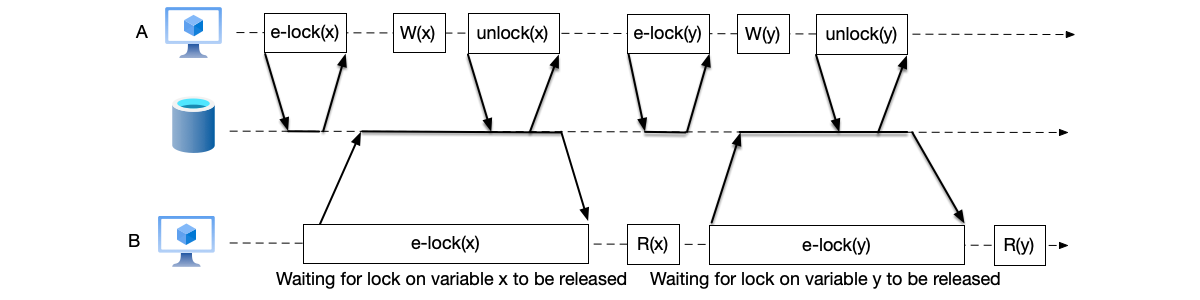
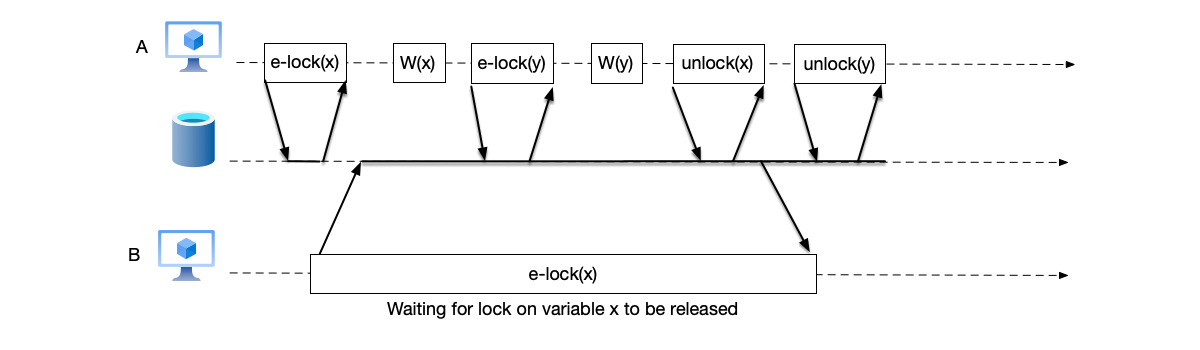
When a transaction needs to acquire a lock on a shared resource, if that resource is already locked by another transaction and the two locks are incompatible, it must wait until the other transaction releases the lock before the lock acquisition can succeed. As shown below, transaction A has acquired a write lock on variable x; at this point transaction B must wait for this lock to be released before it can also acquire a lock on variable x.
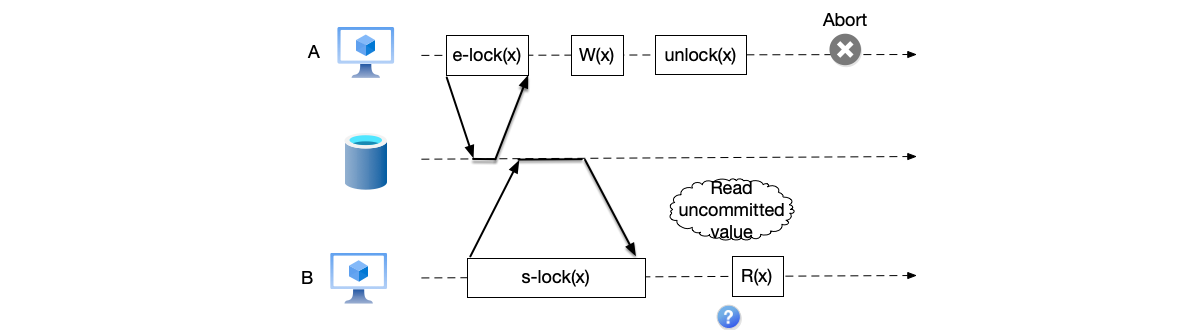
Two-phase locking works well in most cases, but in some situations it can expose uncommitted data, causing the “dirty read” problem. As shown below, after transaction B reads the value modified by transaction A when transaction A releases the lock on variable x, transaction A subsequently aborts and rolls back its changes, so transaction B has read dirty data.
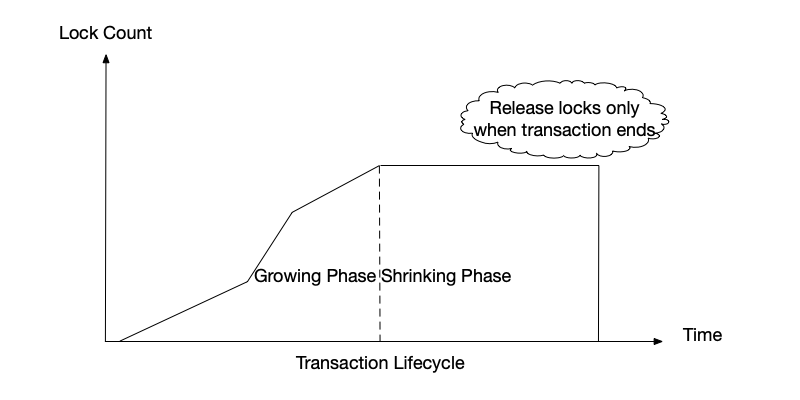
To solve the dirty read problem caused by two-phase locking, a variant of 2PL called Strong Strict Two-Phase Locking (SS2PL) was introduced. Unlike 2PL, SS2PL only begins to release locks after the transaction ends (abort or commit). As shown below, locks are only released when the transaction ends.
The figure below is an example of Strong Strict Two-Phase Locking; transaction A does not release its locks until commit, avoiding dirty reads.
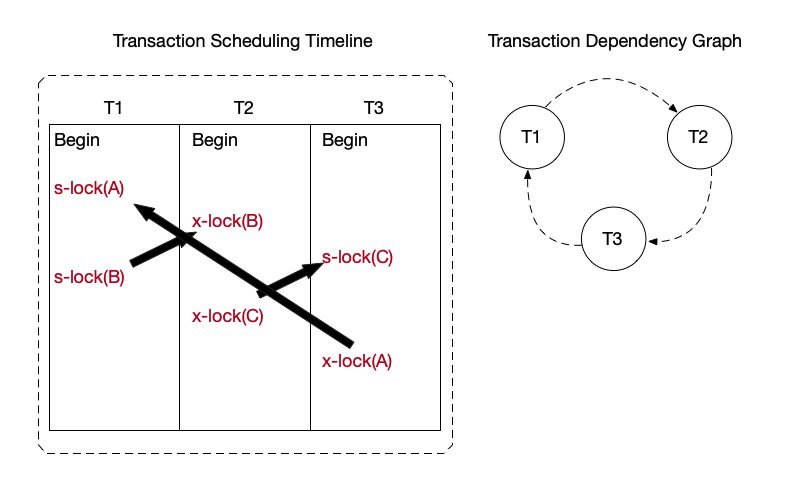
Two-phase locking may cause deadlock among concurrent transactions. As shown below, transaction T1 wants to acquire a shared lock on object B, but depends on transaction T2 releasing the exclusive lock on object B; transaction T2 has acquired an exclusive lock on object C, but depends on transaction T3 releasing the shared lock on object C; finally, transaction T3 has acquired an exclusive lock on object A, but depends on transaction T1 releasing the shared lock on object A. In this scenario, the dependency relationships among the three transactions form a directed cycle, thus causing a deadlock.
Optimistic Concurrency Control #
Two-phase locking is pessimistic in handling possible conflicts in concurrent transactions: it assumes conflicts are frequent, so it prevents them by acquiring locks on resources in advance. The optimistic approach, by contrast, assumes conflicts between transactions do not occur often, so it does not lock resources during transaction execution, and performs conflict detection only when the transaction commits, resolving any conflicts that arise.
The Optimistic Concurrency Control (OCC)[4] introduced here embodies this idea; it was proposed in 1981 in the paper “On Optimistic Methods for Concurrency Control”[5].
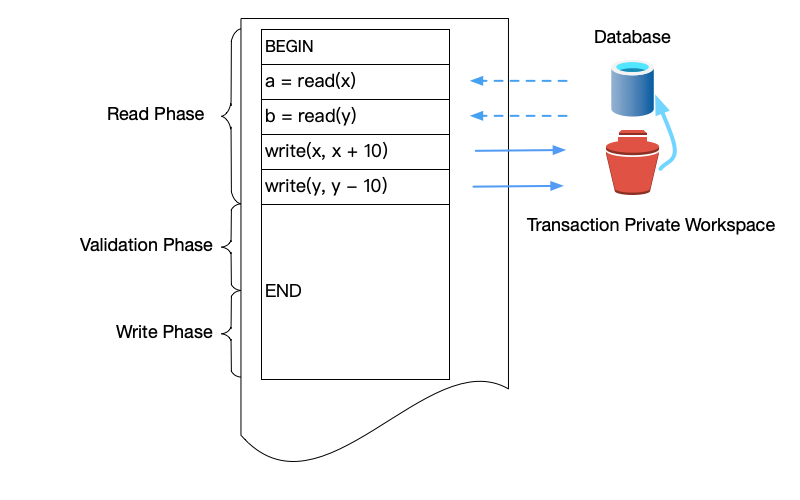
As shown below, the execution flow of optimistic concurrency control is divided into three phases:
Read Phase
In this phase, the transaction can read data and perform computations, but all modifications occur only in the transaction’s local private workspace (for example, a copy in memory), and do not directly modify the database.
- Read data: When a transaction needs to read a data item, it reads the latest committed version of the data into its own private workspace.
- Make modifications: The transaction modifies the data in its private workspace. These modifications are completely invisible to other transactions.
This phase has no locks, so there is no waiting, and read/write efficiency is very high.
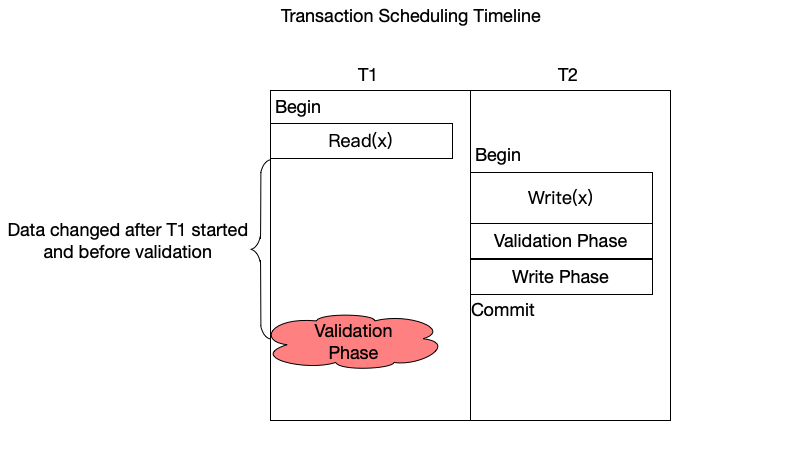
Validation Phase
When a transaction is ready to commit, it enters the validation phase, which is the core and essence of optimistic concurrency control. The system checks whether, during the execution of this transaction, modifications by other transactions have conflicted with it.
The essence of validation is to check the serializability order of transactions. A common rule is: all data involved in the read operations of transaction T must not have been modified by any other committed transaction after T began reading and until T completes validation. In other words, the “read set” of transaction T must be up-to-date. If its read set has been tainted, then the calculations it made based on this read set lose their correct premise.
In specific implementations, when each transaction starts, the system usually assigns it a unique monotonically increasing timestamp. During validation, the transaction T being validated is checked for conflicts with all other transactions T’ that started before it but completed validation after it. If it is found that data involved by transaction T already has newer data in the database, this means a conflict has occurred.
Write Phase
If the validation phase passes successfully, the transaction enters the write phase. The system atomically writes all modifications in the transaction’s private workspace back to the global database, including using the transaction’s timestamp to update the latest timestamp of the data, which provides a basis for other transactions to perform conflict validation. After the write is complete, the transaction’s modifications become visible to other transactions.
If the validation phase fails, this means a conflict has occurred. The transaction is completely rolled back (its private workspace is simply discarded). The system can usually choose to abort and report an error, or automatically restart the transaction. After restart, it re-executes based on the new data state.
The key point of optimistic concurrency control is how to verify that the read and write data of two transactions do not conflict. The key is to determine whether, after the transaction began reading and until validation is completed, the data read by the transaction has been modified. The following are two scenarios in which conflicts occur:
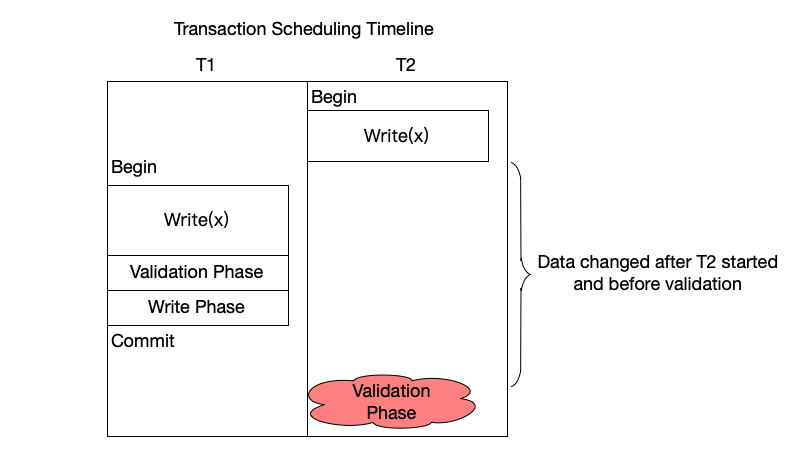
Write-Write Conflict
Write-write (WW) conflict refers to the situation in which, if two transactions both have modification operations on variable x, the modification of one transaction overwrites that of the other.
As shown below, transactions T1 and T2 modify the same data x. During the start and validation of transaction T2, transaction T1 completes its commit, so validation fails and the transaction needs to be re-executed.
Read-Write Conflict
As shown below, Read-Write (RW) conflict refers to the situation in which data read by one transaction is modified by another concurrent transaction, which also causes validation to fail.
Optimistic concurrency control does not acquire locks during execution; in scenarios with low conflict rates, its performance is much higher than lock-based protocols. Because no locks are requested, deadlocks are fundamentally avoided. However, if transactions frequently conflict, a large amount of rollback and retry will bring huge overhead, and performance may even be worse than simple locking. A long transaction may be repeatedly preempted by short transactions, causing multiple validation failures and rollbacks.
Optimistic concurrency control’s idea of using timestamps to verify data versions can also be applied at the application level. For example, a field version can be added to a data table to indicate the data version. When submitting a modification, the update is performed only if the data version is the version originally read; otherwise, the current latest data is read again and the operation is retried:
UPDATE table SET data = new_value, version = 2 WHERE id = 123 AND version = 1;
If the “number of affected rows” returned by this UPDATE statement is 0, it means that, after it read the data and before it updated it, another transaction has modified the data (version is no longer 1), i.e., validation failed. The application layer can catch this signal and roll back or retry. This is essentially the implementation of optimistic concurrency control at the SQL level.
Multi-Version Concurrency Control #
Multi-Version Concurrency Control (MVCC)[6] achieves concurrency control by creating multiple versions of data copies in the database. It was first proposed in the 1978 doctoral dissertation “Naming and Synchronization in a Decentralized Computer System”[7], and was described in detail and introduced into the field of database concurrency control in the 1981 paper “Concurrency Control in Distributed Database Systems”[8].
The basic principle of MVCC is that the database management system maintains multiple physical copies of a single logical object:
- When a transaction writes to an object, the database management system creates a new version of that object.
- When a transaction reads an object, it reads the latest version that existed when the transaction began.
Concurrently executing transactions operate on physically isolated data, preventing them from interfering with each other. In one sentence: write operations do not block read operations, and read operations do not block write operations (Writers do not block readers, readers do not block writers).
Different database systems implement MVCC differently; the following briefly explains the basic principles without being limited to a specific database system implementation.
For each record, in addition to the value of the record, the database also maintains two transaction-related data items: Begin and End, indicating the valid transaction-period range of that version of the data, used to control which transactions can see this version of the data. When End is infinity, it means this version of the data is currently the latest; when End is null, it means this version of the data has not yet been committed by a transaction.
After versioning is added to records, the transaction execution logic is modified as follows:
-
Read operation: When a transaction wants to read a record, it can only read the latest data satisfying the following conditions:
- Begin is less than or equal to the current transaction ID.
- End is greater than the current transaction ID (when End is infinity, this condition is also satisfied).
These two conditions ensure that the transaction reads the latest data before the transaction began.
-
Write operation:
- When a transaction modifies a record, it does not directly overwrite the original data, but first copies the latest record.
- It modifies the data on the copied record, and the Begin of this new record is the current transaction ID.
-
Commit transaction:
- If other transactions with transaction IDs smaller than this transaction are currently executing, it needs to wait for these transactions to commit first.
- Compare the data transaction IDs of the modifications; if they are inconsistent with the transaction IDs originally read, choose to abort or restart the transaction.
- Change the End of the records modified by this transaction to infinity, indicating that it is currently the latest version, and at the same time change the End of the previous last version to this transaction’s ID.
Taking the figures below as examples to illustrate the working principle of MVCC, two transactions T1 and T2 execute concurrently and modify the same record:
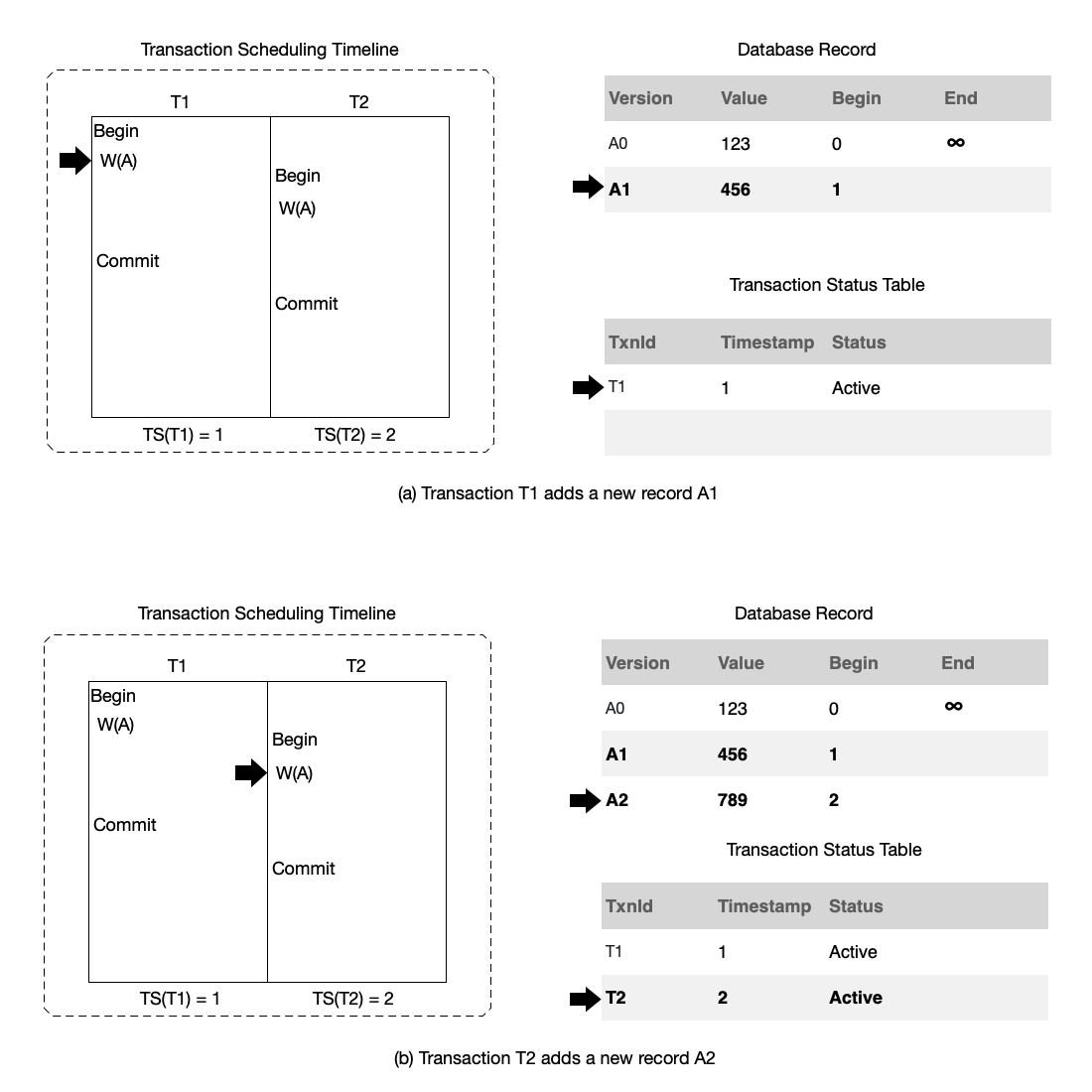
- (a): Transaction T1 begins execution and modifies record A. It will add a new version A1. The Begin time of this record is the timestamp 1 of transaction T1. At the same time, because transaction T1 has begun execution, a status for transaction T1 is also added to the transaction status table.
- (b): Transaction T2 begins execution and modifies record A. It will add a new version A2. The Begin time of this record is the timestamp 2 of transaction T2. At the same time, because transaction T2 has begun execution, a status for transaction T2 is also added to the transaction status table.
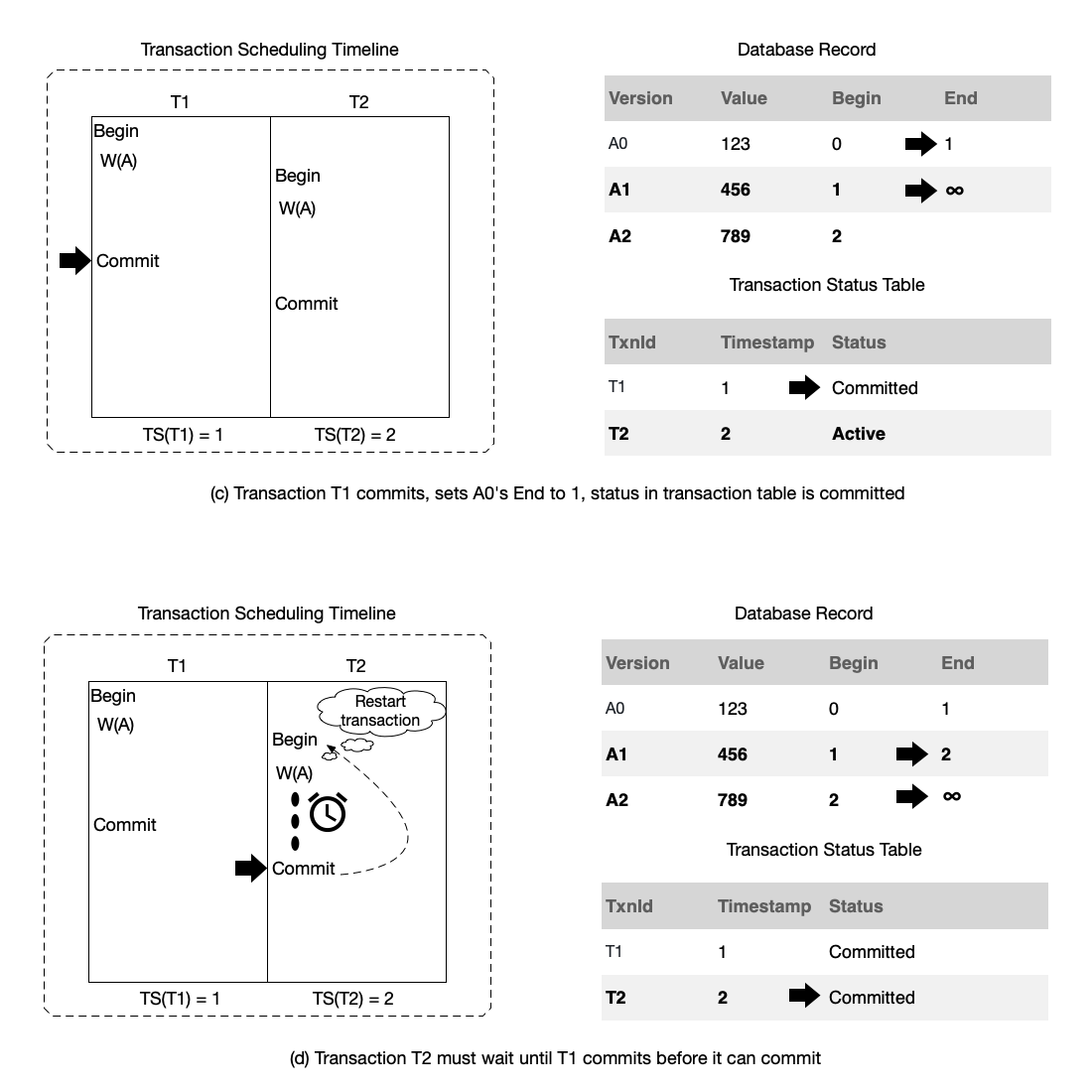
- (c): Transaction T1 commits. It changes the End timestamp of the current latest record A0 to the timestamp 1 of transaction T1, changes the End time of record A1 to ∞, indicating that this record is currently the latest, and finally changes the status of transaction T1 in the transaction status table to “committed.”
- (d): It is worth noting that, if transaction T2 commits and finds in the transaction status table that transaction T1, which has an earlier time than itself, has not yet committed, it needs to wait until transaction T1 commits before it can commit. When committing, it finds that the latest version of data A is 1, not version 0 when transaction T2 began, so transaction T2 chooses to restart the transaction, read the latest data A1, and modify it again. After restarting the transaction, no further conflicts are found, and it can complete the commit. Like transaction T1, it needs to change the End time of the previous latest record to the timestamp 2 of this transaction, change the End time of record A2 to ∞, indicating that it is currently the latest data. After all this is completed, it changes the status of the transaction to “committed.”
From the above flow, we can see that in multi-version concurrency control, different versions of the same data form a linked-list relationship in chronological order; the earliest data is at the head of the linked list. This also provides convenience for implementing time-travel queries. As shown below, three versions of data A form a linked list in chronological order; each node has a pointer to the previous version of the data, and each data item has its own [start timestamp, end timestamp]. If we need to query the data at a certain time, the process is as follows:
- First get the current latest data. If the query time is greater than the start time of the latest data, return the latest data.
- Otherwise, go back to the previous data; if the required query time falls within the time range of that data, return the data; otherwise continue searching forward.
- If no data satisfying the requirement is found all the way to the head of the linked list, i.e., the query time is earlier than the start timestamp of the earliest version, return the data at the head of the linked list.

However, precisely because the same data has multiple versions, a large amount of data redundancy is created. In addition to multiple data versions when transactions succeed, redundant data may also be produced when transactions abort (for example, when a data conflict with another transaction is found at commit time). This uncommitted data is called orphan data. Both types of data need to be cleaned up periodically (this process is usually called vacuum[9]). The logic for finding data to be cleaned up is similar to that of time-travel queries: traverse the data linked list according to a time, find data versions before this time, and clean them up.
MVCC has become the concurrency control solution of choice for many modern mainstream databases (such as PostgreSQL[10], MySQL InnoDB[11])[12].
Write Skew
Although multi-version concurrency control technology can prevent most of the anomalies mentioned earlier, it cannot solve the write skew problem. Write skew is a concurrency anomaly that occurs when multiple transactions concurrently read different parts of the same data set and update different parts of that data set based on what they read, ultimately causing the database state to violate some consistency constraint. Its core characteristics are:
- Non-overlapping read sets: the data items (rows) read by each transaction are different.
- Non-overlapping write sets: the data items (rows) updated by each transaction are also different.
- Global constraint exists: although the read and write rows are different, there is a global, cross-row business-rule constraint among these rows. Executing any single transaction alone can maintain the constraint, but after concurrent execution, the constraint is violated.
In simple terms, write skew is the database version of “the blind men and the elephant”[13]: each transaction only sees a part of the data (and that part itself is valid), and makes a locally correct decision based on that partial information, but their decisions combined violate the overall global rule.
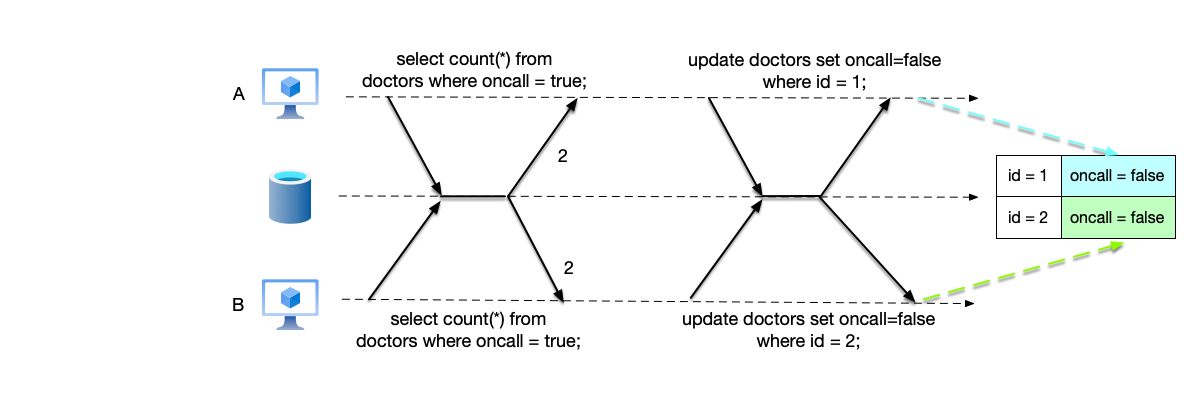
Taking a hospital on-call system as an example to illustrate the write skew problem. The hospital on-call system requires that at least one doctor be on call at any given time. The table below is the doctors’ on-call schedule; the field oncall indicates whether the doctor is on call. It can be seen that currently two doctors are on call. As shown below, two doctors simultaneously query the number of currently on-call doctors with the condition oncall=true, and both get the result 2, satisfying the condition that more than one doctor is on call. They then set their own status to off-duty (oncall=false). Because the two doctors modify their own data separately, even multi-version concurrency control cannot detect a data conflict, ultimately causing a violation of the on-call rule.
| Field | name | id | oncall |
|---|---|---|---|
| A | 1 | true | |
| B | 2 | true |
Unlike “lost update,” lost update occurs when two transactions modify the same data item, while in write skew transactions usually modify different data items. This anomaly usually occurs under medium isolation levels such as snapshot isolation or repeatable read, because these levels cannot detect this kind of logical conflict.
It is worth noting that write skew is not an accidental anomaly under MVCC, but a typical problem specific to the Snapshot Isolation (SI)[14] model. Most databases based on MVCC have a default isolation level that is essentially snapshot isolation. Under this level, each transaction seems to have a “frozen” snapshot of the database at a specific moment; the transaction makes business decisions based on the state in that snapshot (for example, currently only one doctor is on call). The root cause of write skew is that the premise (Premise) on which the transaction based its decision is no longer valid at commit time because of modifications by other concurrent transactions, but the traditional snapshot isolation mechanism cannot perceive this cross-record logical dependency.
At lower isolation levels (such as read committed or repeatable read), write skew can be prevented by manually acquiring locks. The most common method is SELECT ... FOR UPDATE, which acquires an exclusive lock (or upgrade lock) on the rows read when the transaction reads the data.
-- Both transactions T1 and T2 execute code similar to the following
BEGIN;
-- Read and lock all on-call doctor records
SELECT * FROM on_call_doctors WHERE oncall = true FOR UPDATE;
-- Suppose the query returns two rows, A and B, and count > 1
-- Application code checks count
-- If allowed to go off duty, update
UPDATE on_call_doctors SET oncall = false WHERE name = 'A'; -- or 'B'
COMMIT;
Its execution principle is: when transaction T1 executes SELECT ... FOR UPDATE, it locks the records of A and B. At this point, when transaction T2 tries to execute the same query, it must wait until T1 commits or rolls back and releases the locks. In this way, concurrent execution becomes serial execution, and write skew will not occur.
In addition, modern database theory has proposed the more efficient Serializable Snapshot Isolation (SSI) algorithm. SSI is an optimistic concurrency control mechanism that retains the high-performance advantage of MVCC “reads do not block writes”; by tracking read-write dependency relationships among transactions in the background, it automatically detects and aborts transactions that may cause write skew. Currently, the Serializable level of mainstream databases such as PostgreSQL uses this technology[15], ensuring strict consistency while minimizing performance losses caused by lock contention.
Distributed Transactions #
So far, we have discussed in depth the relevant technologies of single-node database transactions. However, when evolving from single-node databases to distributed transactions, system complexity grows exponentially. Below, we use the example of a user placing an order on an e-commerce website to illustrate the difference between the two architectures.
A typical user order-placing process includes three core steps: creating an order, deducting inventory, and finally paying.
If a single-node database architecture is adopted, the operations on the data tables to be updated in these steps can be placed in the same transaction. In this case, the ACID properties of the single-node database transaction can well satisfy the needs of this business, and all complex technical difficulties such as concurrency control and failure recovery are perfectly handled by the database “black box.” This is the simplest and most reliable pattern.
Now the business has grown, and microservice decomposition is needed. The above three operations are split into three different services: order service, inventory service, and payment service, each with its own independent database. At this point, the single-node database transaction can no longer satisfy this architecture. The following briefly lists the complexity and difficulties introduced under the distributed architecture.
Compromised Atomicity
Because multiple services are involved, the problem of partial failure may occur, which will destroy the system’s atomicity. For example, the order is created successfully and the inventory is deducted, but when calling the payment service, the network times out or the payment service is unavailable.
Compromised Isolation
In addition, the system will expose intermediate states during the call process. For example, after the order service and inventory service succeed, but before the payment service is completed, other businesses or users may see this inconsistent state. Suppose user A’s order-placing process is in progress, and the inventory has already been deducted. At this point user B comes to query the inventory of this product and sees a reduced (but not yet finalized) inventory quantity. If user A’s order ultimately fails and the inventory is rolled back, then what user B saw is “dirty” data.
From single-node to distributed, we are actually exchanging huge system complexity (code, architecture, operations) for system scalability, availability, and team independence. This is why a common rule in software architecture is: “If a monolith can solve the problem, don’t rush into microservices.” Because once you step into the distributed domain, problems that the database originally solved transparently for you now all need to be handled manually.
Just now, through the example of “user placing an order,” we clearly saw the series of thorny problems faced when migrating from a single-node database to a distributed microservice architecture. This painful reality forces us to think about a fundamental question: in the distributed world, can we still pursue that “perfect,” textbook-style ACID transaction as in the past?
The answer is: usually not, and we should not. To solve these problems, the industry has developed a whole new set of theories and practices, which are distributed transaction solutions, and the core guiding ideology behind them is exactly the BASE theory.
The goal of distributed transactions is to guarantee data consistency of a complete business process in a system composed of multiple independent services and multiple independent databases. They are mainly divided into two schools:
- Hard transactions: Pursue strong consistency of data, trying to simulate ACID properties in a distributed environment to the greatest extent, especially in isolation and atomicity. Representatives include Two-Phase Commit (2PC) and Three-Phase Commit (3PC). These solutions usually achieve consistency by locking resources for a long time, at the cost of low performance, synchronous blocking, and poor availability. In high-concurrency Internet scenarios, this is almost unacceptable.
- Soft transactions: Abandon strong consistency and accept that data may be inconsistent for a certain period of time. They no longer pursue “all operations succeed or fail simultaneously,” but instead promise “if something goes wrong, I have a way to correct it and make the data eventually consistent.” Their advantages are extremely short resource locking time (or even none), high degree of asynchronization, system throughput and availability far exceeding hard transactions. Representatives include SAGA, TCC, etc.
Today, soft transactions have gradually become the mainstream choice for distributed transactions, and their theoretical cornerstone is the BASE theory. In the CAP theorem, the three constraints are too rigid; as a supplement to the CAP theorem, in 2008 eBay systems architect Dan Pritchett proposed the BASE theory in the paper “BASE: An ACID Alternative”[16]. It is an acronym of Basically Available, Soft state, and Eventually consistent.
In the CAP theorem, C adopts linearizability, requiring the entire system to behave like a single replica at any moment, with written data immediately reflected on all nodes in the system. The BASE theory chooses weaker eventual consistency in exchange for overall system availability:
- Basically Available: In strong-consistency solutions (such as 2PC), a service failure or network blockage can cause the entire transaction process to freeze and the system to become unavailable. BASE theory holds that the core functions of the system should always be available; when some nodes of the system fail, performance degradation or partial non-core function loss is allowed. For example, increased latency, queuing to log in to a game, etc., are common strategies when basic availability is degraded.
- Soft State: Soft state is relative to the “hard state” of linearizability required by the CAP theorem. Linearizability requires data modifications to be immediately synchronized to all nodes. Because the same data is stored on multiple nodes and data may take time to propagate to each node, this means the database cannot strongly guarantee data integrity. BASE theory holds that we should acknowledge and accept the existence of this “intermediate state”; soft state allows intermediate states for transition.
- Eventually Consistent: BASE theory holds that synchronizing data among nodes takes time, modifications cannot immediately be synchronized to all nodes, and the system is allowed to have temporary inconsistency (soft state), but a mechanism must be designed (for example, compensation operations in Saga mode) to ensure that after the process succeeds or fails, all related data can eventually reach a logically self-consistent, consistent state.
BASE theory is the result of balancing consistency and availability in the CAP theorem. Its core idea is: abandon strong consistency, and according to the characteristics of each service, adopt appropriate methods to make the system eventually consistent. BASE theory describes a system that makes a best-effort attempt to ensure all queries return results, but the cost is that the returned results may sometimes reflect a slightly stale data version. According to the CAP theorem’s three-choose-two classification, a system described by BASE theory is more like an AP system.
In the paper, Dan Pritchett demonstrated how to ensure soft availability by sacrificing strong consistency. Taking transfer as an example, user A transfers money to user B, and the two accounts are in different banks:
- Create a message table to store operations that need to add money to accounts in the bank.
- In the banking system where user A is located, start a transaction, deduct money from A’s account, and at the same time insert a record into the message table indicating that money needs to be added to user B’s account.
- In the banking system where user A is located, commit the transaction; if the transaction commit fails, delete the newly added data from the message table.
- Another process periodically polls the message table, executes the operations in it, and only deletes the data from the message table after successful execution.
In this example, the system is not in a data-consistent state for a period of time (the sum of the balances of users A and B may be inconsistent), but the system will eventually reach consistency, in exchange for improved overall system availability. However, this implementation cannot guarantee data isolation. For example, if other users see user B’s account balance before the money has been added, they still see the old account balance; for scenarios with high isolation requirements, other solutions must be chosen, which will be introduced later in this chapter.
After understanding the CAP theorem and BASE theory, we know that in distributed transactions there are two different solutions: strong consistency and eventual consistency:
- Strong consistency solutions: Two-Phase Commit, Three-Phase Commit, Google Spanner.
- Eventual consistency solutions: TCC transactions, SAGA transactions.
The following sections expand on these different solutions.
Two-Phase Commit #
Classic Two-Phase Commit Flow
The first solution for implementing strong-consistency distributed transactions is Two Phase Commit (2PC)[17]. In this solution, there are two types of subsystems:
- Transaction Manager (TM): responsible for local transaction concurrency control and failure recovery functions.
- Transaction Coordinator (TC): responsible for starting and coordinating distributed transactions, dividing distributed transactions into two phases for TM execution.
During each distributed transaction execution, there can be only one transaction coordinator, but the transaction coordinator can also be a transaction manager at the same time.
A typical two-phase commit flow is shown below, divided into the following two steps:
- Prepare Phase: In this phase, the coordinator sends a Prepare message to all participants of the transaction, asking whether they are ready to commit the transaction.
- If a participant is ready to commit the transaction, it persistently records the content of what the transaction commit will do locally, but does not actually commit. This means that during the prepare phase, after persisting data, the participant also needs to maintain data isolation and cannot release locks to make the data visible externally. If the participant is a database, what needs to be done in the prepare phase is to write the corresponding modifications in the database transaction, but not commit.
- If a participant encounters an error during the prepare phase, it replies with an Abort message to the coordinator, indicating that the transaction should be aborted.
- Commit Phase:
- When the coordinator receives Ready responses from all participants, it considers the distributed transaction ready to commit, and at this point sends a Commit message to all participants; all participants execute the transaction commit operation.
- If any participant replies with Abort, or if not all participants’ responses are received within the timeout period, the coordinator considers that the transaction needs to be aborted and sends an Abort message to all participants to abort the transaction.
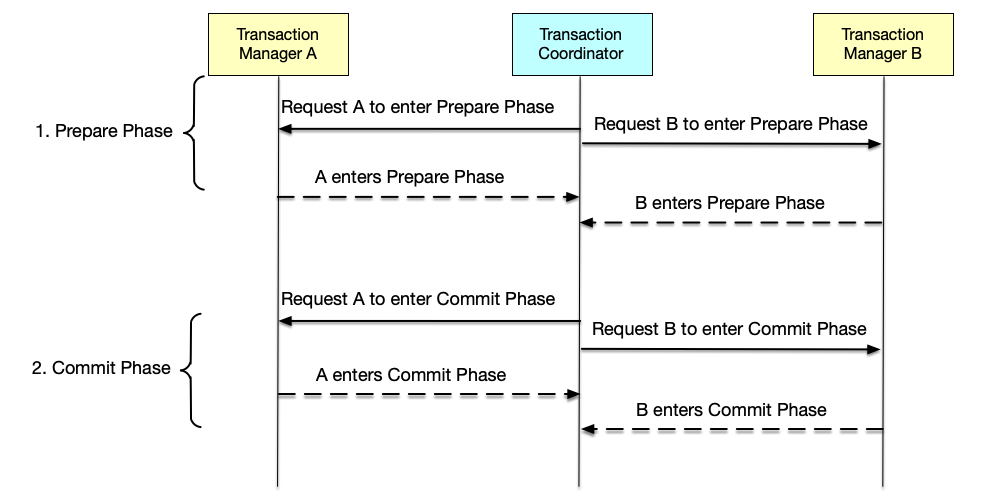
The two-phase structure allows the coordinator to confirm with all participants during the prepare phase whether the transaction can be committed. In this phase, participants can decide whether to commit the transaction and also have the right to veto and abort the transaction. However, once a participant agrees to commit the transaction, the decision is no longer in the participant’s hands. Therefore, the first phase is an irrevocable promise made by the participant to the coordinator. Thus, after the coordinator collects all participants’ first-phase responses and persists the transaction’s Commit or Abort information, the transaction will no longer change.
The principle of two-phase commit is not complicated, but its implementation has several flaws:
- Single point of failure: The coordinator in two-phase commit becomes a single point of failure. If a participant crashes, according to the two-phase commit flow described above, the coordinator will abort the transaction if it has not received all participants’ responses within the timeout. However, if the coordinator crashes, participants will wait indefinitely until the coordinator recovers.
- Synchronous blocking problem: During two-phase commit, all participants and coordinators work as a unified whole, requiring three data persistences and two remote server calls to complete; the final completion time depends on the last completed operation time in this whole.
- Data consistency problem: In the commit phase, if some participants do not receive the Commit message from the coordinator due to network failures, this will cause only some participants to execute the commit operation, resulting in system data inconsistency.
Three-Phase Commit #
To alleviate the single-point and prepare-phase performance problems in two-phase commit, the Three Phase Commit (3PC)[18] protocol was proposed. Building on 2PC, it further divides the prepare phase into two phases, called CanCommit and PreCommit, and renames the commit phase as DoCommit. The working steps of three-phase commit are as follows:
- CanCommit phase: Also called the inquiry phase. In this phase, the coordinator sends a CanCommit request to all participants, asking whether they are ready to commit the transaction. Participants evaluate whether they can complete the transaction based on their own conditions and reply to the coordinator.
- PreCommit phase: Also called the prepare phase. If all participants reply that they can commit the transaction, the coordinator sends a PreCommit request to all participants. Participants persist the operations but do not commit, to ensure data isolation, and reply to the coordinator that they are ready to commit the transaction.
- DoCommit phase: Also called the commit phase. If all participants reply that they are ready to commit the transaction, the coordinator sends a DoCommit request to all participants, notifying them to commit the transaction. In this phase, if a participant does not receive the coordinator’s DoCommit message before the timeout expires, the default strategy is to commit the transaction.
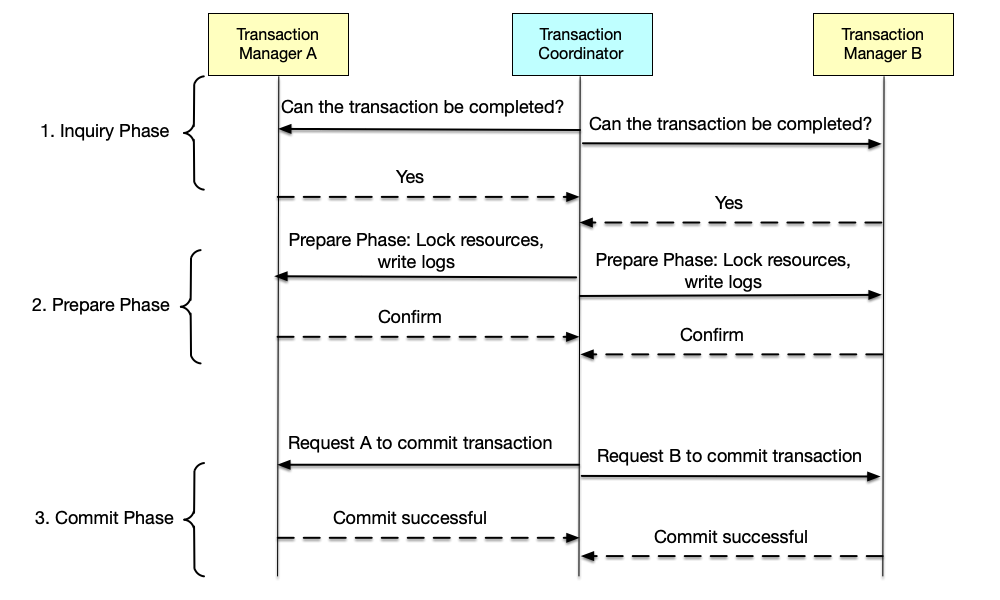
Compared with the 2PC protocol, the 3PC protocol makes the following modifications:
- The Prepare phase of the 2PC protocol is divided into CanCommit and PreCommit phases. The reason for this division is that, in the prepare phase, persisting data by participants is a heavy operation; once another participant replies that it cannot commit the transaction, the previous persistence work of other participants must be rolled back. The new CanCommit phase first asks each participant whether it can commit the transaction, and only after all participants agree does it execute the persistence operation of the prepare phase; the probability of success is much higher.
- In the 2PC protocol, once the coordinator crashes, participants must wait until the coordinator recovers before they can continue working. In the 3PC protocol, after the first two phases pass, the probability of transaction rollback is very small, so if after the PreCommit phase a participant does not receive the coordinator’s DoCommit message before the timeout expires, it will commit the transaction by default.
Although the 3PC protocol improves the single-point and prepare-phase performance problems of the 2PC protocol, in the case where the transaction can commit normally, 3PC has one more inquiry round than 2PC. In addition, the data consistency problem of 3PC has not been solved. For example, if after the PreCommit phase the instruction sent by the coordinator is to abort the transaction, but only some participants receive this instruction, other participants that do not receive this instruction will execute the default commit operation after the timeout, and data inconsistency will still exist.
As shown below, the transaction coordinator and two transaction managers have completed the inquiry phase and the prepare phase, and reached the commit phase. At this time, transaction manager A is network-partitioned from the coordinator, so it has not received the coordinator’s message, and adopts the default timeout behavior: commit the transaction. The coordinator, for some reason, decides the transaction had failed and sends an abort-transaction message to manager B, and manager B rolls back the transaction. The final system state becomes: manager A committed the transaction, while manager B rolled back the transaction; the data of the two is inconsistent.
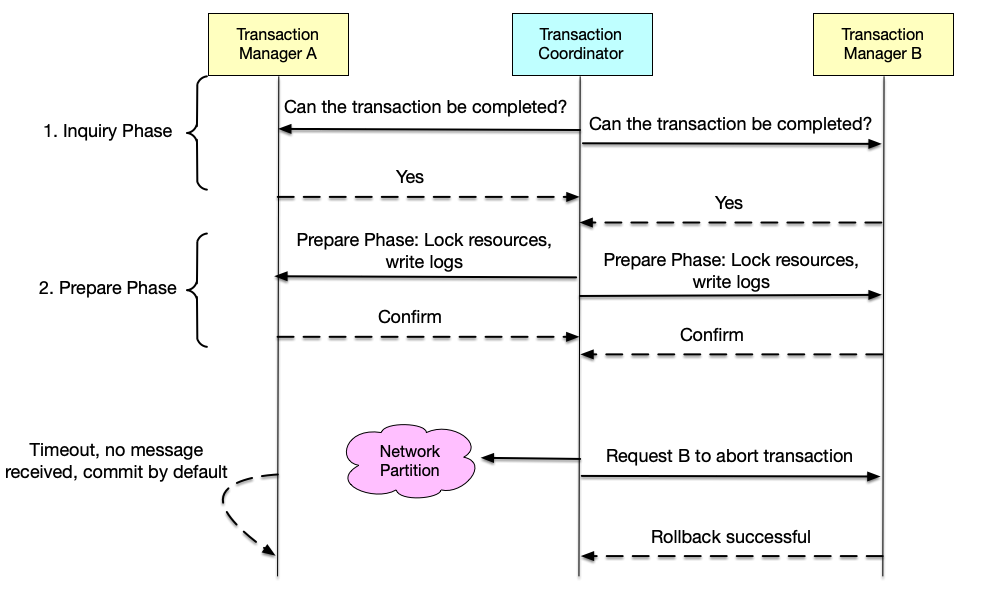
3PC tries to use “timeout,” a mechanism that relies on time assumptions, to solve distributed problems. As we explained in the time chapter, in asynchronous networks, timeout does not necessarily mean failure; it may just be slow. Making automatic-commit decisions based on timeout is extremely dangerous.
Google Spanner #
Through the previous analysis, we can see that the biggest problems of 2PC are poor performance and single-point failure, and subsequent 3PC has not solved these problems either. In this section, we introduce the implementation of the Google Spanner[19] system, which is an industrial-grade strong-consistency distributed transaction implementation.
The main features of Spanner are:
- Provides External Consistency: Spanner provides the highest level of consistency in distributed systems. Thanks to the TrueTime mechanism, Spanner can anchor the commit order of transactions to the physical order of time. This means that if a transaction T1 commits before T2 in physical time, the system can guarantee that all clients observe T1 happening before T2, thus presenting a global view of linearizability.
- Supports Strict Serializability: Spanner’s distributed read-write transactions fully follow ACID properties and provide Serializable isolation level by default. The system eliminates concurrent anomalies such as dirty reads, non-repeatable reads, and phantom reads through the Two-Phase Locking (2PL) mechanism, without requiring application-layer intervention to handle complex concurrency conflicts.
- Global horizontal scaling and cross-shard atomicity: Spanner automatically splits data into multiple shards (Shards/Tablets) distributed across global data centers. By combining Two-Phase Commit (2PC) with the Paxos protocol, Spanner guarantees strict atomicity for distributed transactions spanning multiple shards: all changes are either fully persisted or fully rolled back, thereby shielding the complexity of the underlying shards.
In terms of specific implementation, Spanner adopts a layered architecture: the lower layer uses the Paxos consensus algorithm to ensure data replication and high availability across data centers and even continents; the upper layer uses Two-Phase Commit (2PC) and Two-Phase Locking (2PL) protocols, combined with the original Commit Wait mechanism, to implement cross-shard distributed transactions. This design makes Spanner the world’s first true “global database” (the progenitor of NewSQL). It not only frees developers from tedious data sharding and consistency handling, but also provides a theoretical foundation and engineering model for later emerging open-source distributed databases such as CockroachDB and TiDB.
This section will systematically analyze Spanner’s implementation principles, focusing on how it uses physical clocks to define global transaction order, and how TrueTime, Paxos, and distributed lock mechanisms work together at different levels.
Overall Architecture #
Spanner’s architecture is designed to meet global scalability, high availability, and multi-data-center deployment requirements. As shown below, from a macro perspective, Spanner adopts a layered hierarchical structure, from top to bottom: Universe, Zone, and specific Spanner server nodes.
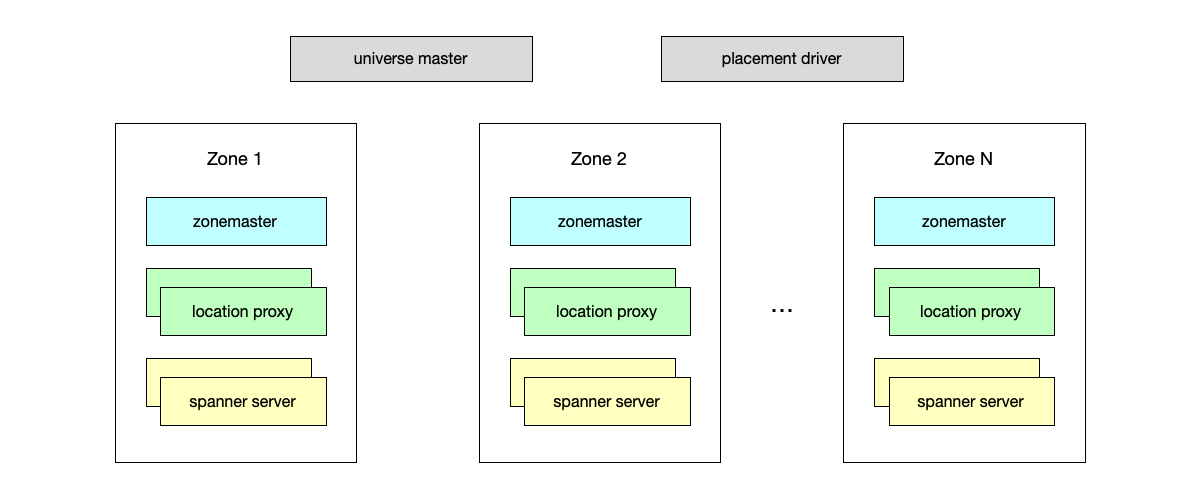
- Universe: Spanner’s top-level deployment unit is called a Universe. A Universe usually covers an enterprise’s global data deployment. Although multiple Universes can theoretically be deployed, in production environments Spanner is designed as a globally unique singleton system, thereby providing a unified namespace and resource management.
- Zone: Inside a Universe, it is divided into multiple Zones. A Zone is Spanner’s physical deployment unit and also the basic physical isolation domain. A Zone contains a cluster of physical servers, usually deployed in a specific data center. A Zone is the basic dimension of data replication and fault isolation: data is replicated to multiple Zones in different data centers to prevent data loss caused by a single point of failure or a single data center outage.
Within a Zone, the following core components are included:
- Zone Master: responsible for managing all Spanner servers in the Zone, assigning data shards (Tablets) to specific Spanner servers, and handling load balancing.
- Location Proxy: acts as the routing layer between clients and Spanner servers, forwarding client requests to the correct Spanner server based on data location information.
- Spanner server: the core work unit responsible for storing and processing data. It directly responds to client read/write requests.
In addition, there are two core services:
- Universe Master: This is a global singleton console, mainly used to monitor the state of the entire Universe and provide an interactive debugging interface for Zone status information.
- Placement Driver: responsible for cross-Zone data migration and scheduling. This component periodically communicates with Spanner servers in each Zone, monitors load status, and triggers automatic data migration when necessary to meet replication strategies or perform load balancing.
Spanner server is the core of system operation; each Spanner server is responsible for managing hundreds or thousands of data shards. As shown below, Spanner server mainly contains the following modules from bottom to top:
- Tablet: The basic data unit managed by Spanner server is called a Tablet. The Tablet concept is similar to the same-name concept in Bigtable; it is a set of key-value pairs in the form
(Key: string, Timestamp: int64) -> String. This structure naturally supports Multi-Version Concurrency Control (MVCC), rather than being a simple KV store, which enables Spanner to efficiently support snapshot reads. - Paxos: To ensure data consistency, the metadata and logs of each Tablet are synchronized through the Paxos protocol among replicas in different Zones. Each Tablet corresponds to a Paxos Group. In Spanner server, the Paxos state machine is responsible for persisting write-operation logs and coordinating state among replicas.
- Lock Table: On the Leader replica of a Paxos group, a lock table is maintained. This component is used to implement the Two-Phase Locking (2PL) mechanism, responsible for managing row-level locks or range locks in read-write transactions to ensure transaction isolation. Note that read-only transactions using optimistic concurrency control do not need to access the lock table.
- Transaction Manager: Each Spanner server runs a transaction manager responsible for coordinating distributed transactions. For transactions involving only a single Paxos Group, this manager can independently act as the coordinator; for transactions spanning multiple Paxos Groups, the multiple Transaction Managers involved work together, one of which is selected as the coordinator and the rest act as participants, jointly executing the Two-Phase Commit (2PC) protocol.
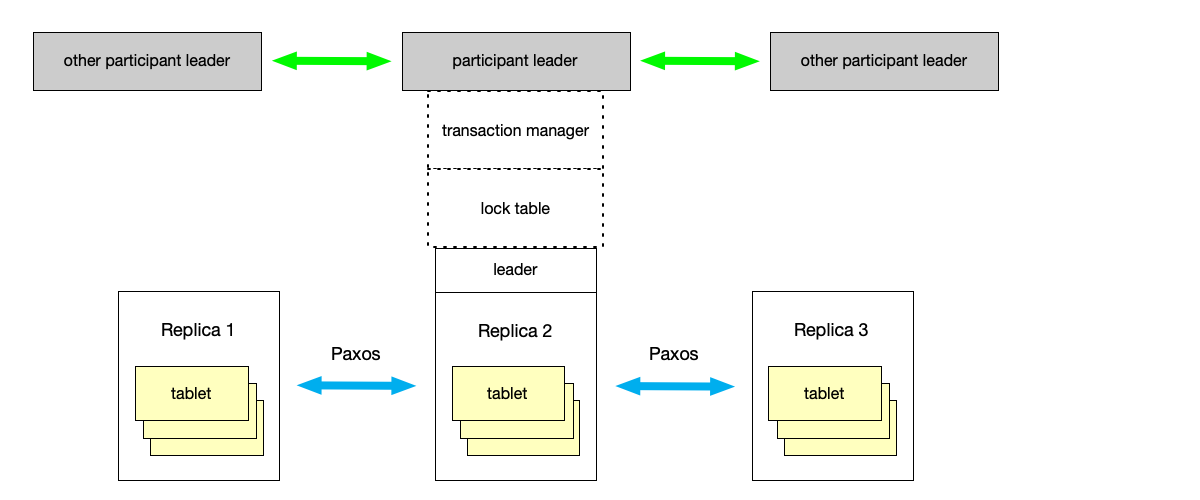
True Time #
We explained in the time chapter the limitations of physical clocks as time in distributed systems. In traditional distributed systems, due to clock drift, clocks among nodes are difficult to keep precisely synchronized. Therefore, system design usually relies on logical clocks to establish the causal order of events. However, Spanner does not adopt the logical clock solution, for the following reasons:
- Spanner wants to achieve linearizability, while the essence of logical clocks is capturing only causal relationships within the system; it implements causal consistency and cannot perceive the order of events happening outside the system.
- A core feature of Spanner is supporting efficient, lock-free snapshot reads at any point in time. If logical clocks were used, implementing this feature would face huge performance penalties: when a user requests to “read the current latest data,” the system cannot immediately determine what “current” is. To construct a globally consistent snapshot, the system must consult all relevant shards (even the entire network), asking them for their current logical clock progress, to negotiate a global “safe snapshot point.” This would cause unacceptable communication delays in cross-continental distributed systems.
- Although vector clocks can describe causal relationships more precisely than Lamport clocks, they are not feasible at Spanner’s scale. The size of vector clocks is proportional to the number of participating nodes in the system (O(N)). Spanner has thousands of Spanner servers and millions of Tablets. If such huge vector information were carried in the metadata of each transaction, network bandwidth and storage space would be consumed by metadata.
Logical clocks are theoretically elegant and require no special hardware, but they push the responsibility of “ordering” to the application layer (requiring the application to pass tokens) or cause read performance to be low. Spanner introduces TrueTime, which uses a combination of software and hardware to compress time uncertainty into a very small physical window, thereby creating an ideal environment with a globally synchronized clock at the software level.
Spanner does not try to eliminate physical clock error, but through the TrueTime mechanism quantifies this error and explicitly exposes it to upper-layer applications, thereby building a globally unique physical time benchmark in a distributed environment.
TrueTime’s high availability and accuracy are first built on a large and redundant hardware foundation. Google has deployed dedicated Time Master nodes in data centers around the world. To eliminate single points of failure and reduce errors, Time Masters adopt a strategy of mixed deployment of two physical time sources:
- GPS receivers: Most Master nodes are equipped with GPS receivers that can directly receive atomic clock signals from global positioning system satellites. The advantage of GPS is high long-term accuracy and extremely small error.
- Atomic clocks: To cope with GPS signal interference or antenna failures, Google deploys atomic clocks on some Master nodes. Although atomic clocks have slight drift, their short-term stability is extremely high, and they can provide a reliable backup time source during calibration by GPS.
Spanner communicates with Time Master nodes through a Time Daemon running on each Spanner server. It periodically polls time information from multiple Time Masters (including those in the local data center and remote data centers). The Daemon uses a variant of the Marzullo[20] algorithm to filter out anomalous clock sources and calculate the deviation range of the local machine clock relative to the reference time.
The TrueTime API is fundamentally different from traditional gettimeofday() or System.currentTimeMillis(). It does not return a single, possibly deviated time point, but returns a time interval containing the error range. TrueTime’s core interface TT.now() returns a time interval object TTinterval:
TT.now() = [earliest, latest]
This interval indicates that, at the time the method is called, the real absolute time t_abs must fall within this interval, i.e., earliest ≤ t_abs ≤ latest. The width of this interval is determined by the error term ε, i.e., [t−ε, t+ε]. The span of this interval is denoted as 2ε, where ε represents the uncertainty half-width of the time. In Google’s production network environment, the average value of ε is usually very low, but during network partitions or extremely high system load, ε may increase.
TrueTime provides the following three core methods:
TT.now(): returnsTTinterval: [earliest, latest].TT.after(t): returns true if the current time is determined to be later than timestamp t (i.e.,TT.now().earliest > t).TT.before(t): returns true if the current time is determined to be earlier than timestamp t (i.e.,TT.now().latest < t).
The ultimate purpose of the TrueTime API is to achieve Spanner’s External Consistency, i.e., linearizability. To this end, Spanner introduces the Commit Wait strategy.
When a transaction T_i tries to commit, Spanner assigns a commit timestamp s_i to that transaction. To guarantee that if transaction T_1 completed before transaction T_2 began, s_1 < s_2 always holds, Spanner must follow the following two rules:
- Timestamp anchoring: The commit timestamp s_i of transaction T_i must be greater than or equal to the value of
TT.now().latest(i.e., s_i ≥TT.now().latest). - Commit wait: Before writing data to persistent storage and externally declaring transaction success, the coordinator must wait until, due to the natural passage of time, the timestamp s_i has definitively become “past.”
Specifically, the system must wait until the current TT.now().earliest is greater than the selected timestamp s_i, i.e.:
TT.after(s_i) → true
The figure below shows an example of Spanner’s transaction commit wait strategy. In the figure, transaction T_1 issues a commit request at time t_1, and this time must wait until t_2 before the commit is considered complete; the span of these two time intervals is 2ε; transaction T_2, which starts after T_1, must have a start time t_3 satisfying t_3.after(t_2) → true.
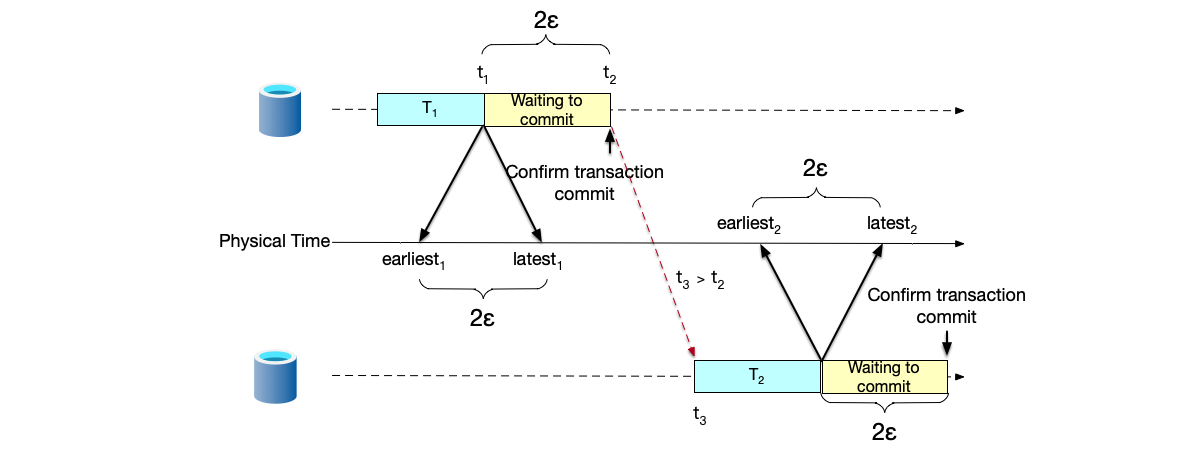
This wait duration is usually 2ε. Through this forced wait, Spanner ensures that at the moment the transaction commits, physical time has indeed passed beyond s_i.
Because of the existence of the Commit Wait mechanism, the lower bound of write-transaction commit latency is strictly locked at 2ε. Therefore, one of Spanner’s engineering goals is to compress this uncertainty window as much as possible while ensuring correctness. TrueTime’s error mainly consists of two parts: local clock drift and network communication delay.
Between two synchronizations, the uncertainty of the local machine clock grows linearly with time, presenting a “sawtooth” pattern. To control the magnitude of this growth, the Time Daemon on Spanner servers polls Time Masters at a very high frequency (usually every 30 seconds, or even higher). The higher the polling frequency, the smaller the drift error accumulated by the local clock between two calibrations, thereby maintaining a low baseline for ε.
To minimize network communication delay, Spanner has made deep optimizations in physical deployment:
- Proximity deployment of Time Masters: Although Time Masters are globally distributed, when Spanner servers poll time, they prioritize synchronizing with Time Masters located in the same data center or nearby regions with low-latency communication links.
- Tail-latency elimination: Jitter occasionally occurs in network communication. When TrueTime’s client daemon polls multiple Masters, it uses logic similar to a variant of the Marzullo algorithm to automatically identify and discard Master data with abnormally long response times, using only those time sources with the fastest responses and highest consistency to calculate the current reference time.
Spanner uses high-performance network infrastructure, high-frequency time synchronization protocols, and strict outlier elimination algorithms to usually keep ε at the millisecond level (about 1ms to 7ms at the time of the paper, averaging about 4ms; in recent years, with hardware upgrades, it has further decreased). This engineering-level extreme compression makes the latency loss caused by Commit Wait acceptable in actual business scenarios, thus achieving a balance between strong consistency and high performance.
Distributed Transactions #
With the TrueTime mechanism to guarantee the commit order among transactions, let us look at how Spanner combines TrueTime, the Paxos algorithm, 2PL, 2PC, and other technologies to implement distributed transactions. Spanner supports the following types of transactions: Read-Write Transaction, Read-Only Transaction, and Snapshot Read. These three modes are built on the TrueTime API and Multi-Version Concurrency Control (MVCC), but adopt different strategies in lock mechanism, timestamp assignment, and replica interaction.
Read-Write Transactions
Read-write transactions are the only transaction type in Spanner that supports write operations. To ensure ACID properties, Spanner combines the following key technologies:
- Two-Phase Commit (2PC) is used to ensure atomicity across shards.
- Paxos is used to ensure single-shard high availability and durability.
- TrueTime ensures global temporal consistency.
Before diving into the flow, we must first clarify Spanner’s basic data unit. As shown below, Spanner splits data into Tablets; the data of each Tablet is maintained by a Paxos Group. This Group contains multiple geographically distributed replicas, which elect a Leader through the Paxos protocol.
- All write operations must be processed by the Paxos Leader.
- All lock management (Lock Table) is maintained in the Leader’s memory.
- Transaction durability relies on writing log entries to the majority of the Paxos Group.
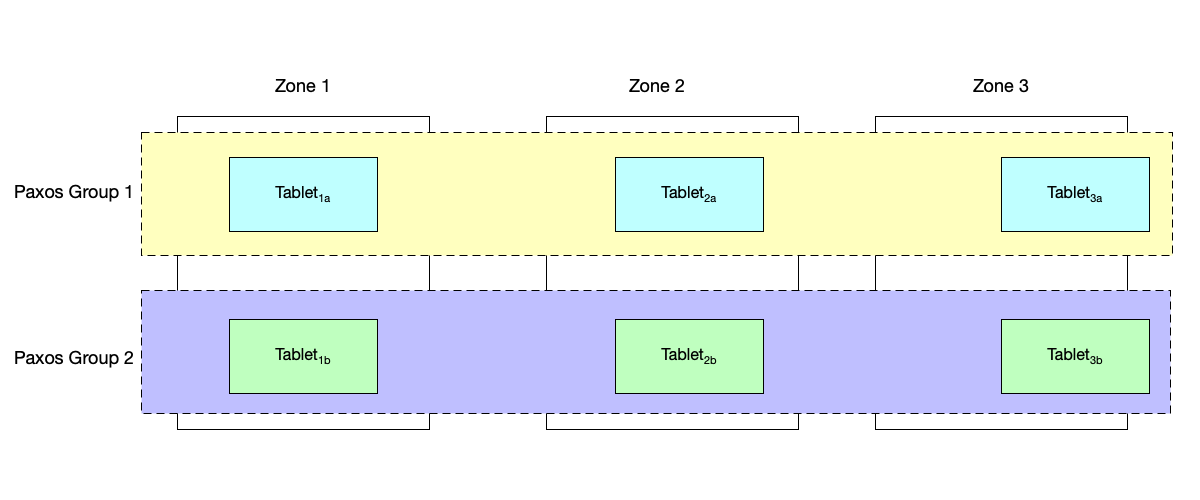
When a transaction involves multiple Tablets, it involves multiple Paxos Groups, and Two-Phase Commit (2PC) needs to step in.
Suppose a transaction T needs to modify data on Paxos Group A and Group B; Spanner will automatically select one of the Groups (for example, Group A) to act as the Coordinator, while the other participating Groups (such as Group B) are called Participants.
The whole process follows the standard 2PC protocol, but is strengthened by TrueTime at key steps. The core flow is as follows:
-
Read phase and pessimistic locking: When a transaction performs read operations, it must first obtain read locks (Read Locks) on the relevant data. If data is distributed across multiple Paxos Groups, the transaction will apply for locks from the Leaders of each group separately. This pessimistic locking mechanism ensures data isolation during transaction execution. Importantly, all write operations are cached at the client before transaction commit and do not immediately interact with the server.
-
Commit phase: When the client initiates a commit request, a transaction involving multiple Paxos Groups will start the Two-Phase Commit (2PC) protocol.
- Coordinator election: one of the Paxos Groups is selected as the Coordinator.
- Timestamp anchoring: The coordinator is responsible for assigning a globally unique commit timestamp S_commit to the entire transaction. According to the characteristics of TrueTime, the coordinator must ensure that S_commit satisfies two conditions:
- Monotonicity: S_commit is greater than all timestamps recorded by participants during the Prepare phase.
- Timeliness: S_commit must be greater than
TT.now().latestwhen the coordinator received the commit request.
-
Commit wait: This is the key to Spanner’s linearizability guarantee. Before S_commit is truly applied and externally declared successful, the coordinator must perform “commit wait.” It continuously checks TrueTime until the following condition is satisfied:
TT.now().earliest > S_commitThis wait ensures that on the physical timeline, the effective moment S_commit of the transaction has become a determined past. Therefore, any new transaction that begins after the transaction commits (i.e., physically later than the commit completion moment) will obtain a timestamp definitely later than S_commit.
The following uses the classic bank transfer as an example to illustrate Spanner’s read-write transaction flow:
Write(A, A - 50)
Write(B, B + 50)
The sequence diagrams of the flow are shown in the figures below. The figure has the following roles:
- Client: the business side that initiates the transaction.
- Paxos Group 1 Leader (Participant Leader): the shard-group Leader holding data A, only responsible for handling the locks and writes of its own data.
- Paxos Group 2 Leader (Coordinator Leader): the shard-group Leader holding data B, in addition to handling data B, also responsible for directing the entire transaction submission process (deciding timestamp, executing wait).
It should be noted that the figure omits the process in which the two Paxos Groups use the Paxos algorithm to replicate data to other replicas within the group, and assumes that in this transaction, Paxos Group 1 acts as the participant and Paxos Group 2 acts as the coordinator.
The main steps in the figure are as follows:
- Phase 1 (steps 1-6): The client sends read requests for data A and B to the Leaders of the two Paxos Groups respectively, obtaining shared locks. After obtaining the data for A and B, the client does not immediately send requests, but first computes locally and buffers write operations.
- Phase 2 (steps 7-13): The Prepare phase of Two-Phase Commit. When the client decides to commit, the system enters the first phase of 2PC. The client distributes the buffered write operations to all relevant Participant Leaders and the preselected Coordinator Leader.
- Phase 3 (steps 14-16): Timestamp arbitration and commit wait phase. The coordinator will select a globally unique commit timestamp S_commit. To ensure external consistency, this timestamp must be strictly greater than all preparation times suggested by participants, and must be greater than the possible upper bound of the current moment (
TT.now().latest). This step binds the logical transaction to physical time. - Phase 4 (steps 17-23): Once the waiting period ends, the coordinator writes the Commit record within the Paxos group and immediately informs the client that the transaction is successful. To improve response speed, the coordinator usually asynchronously notifies other participants to commit. Because participants have previously recorded the Prepare state in persistent logs, they only need to apply updates with the determined S_commit as the version number and release locks after receiving the instruction.
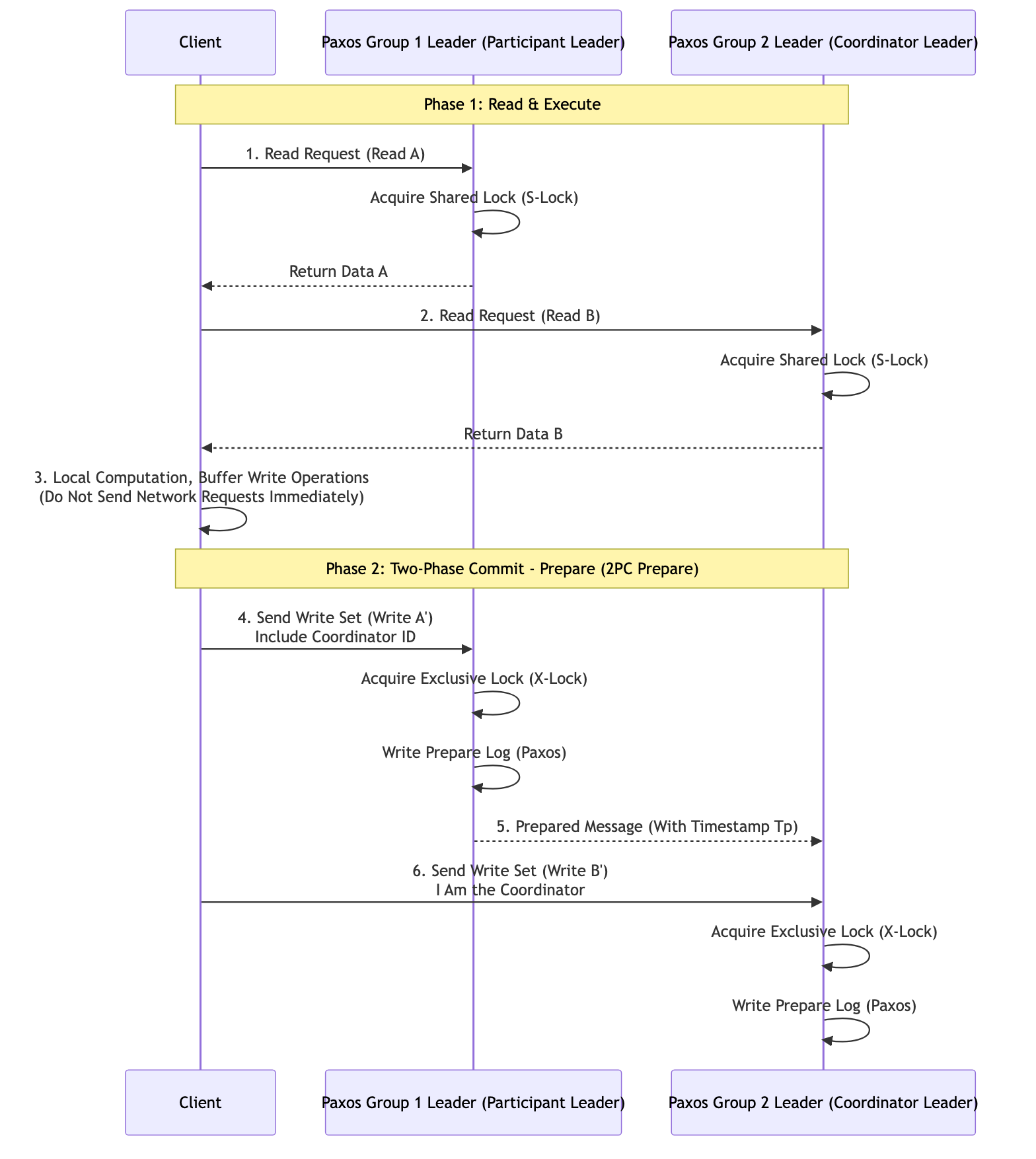
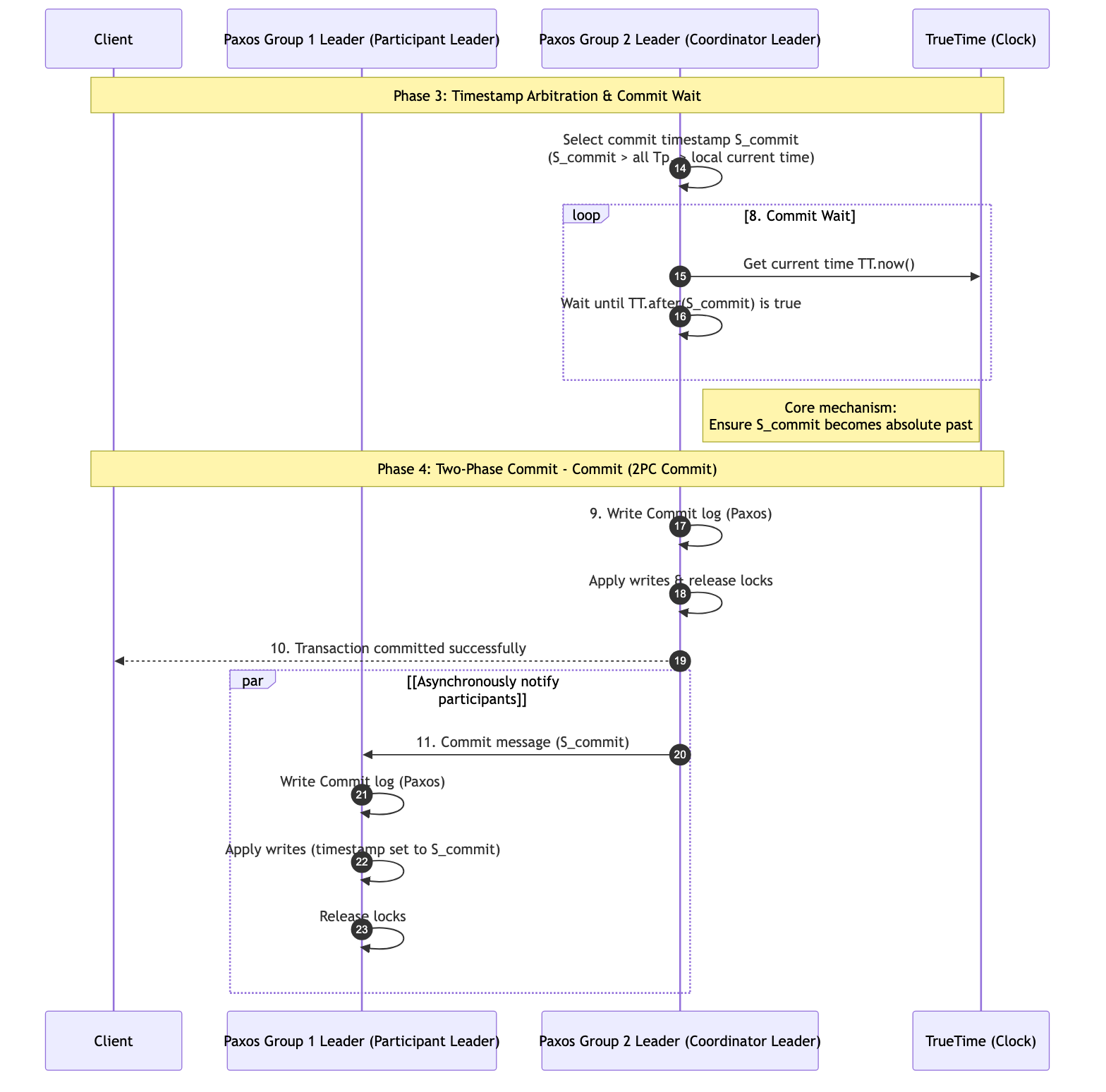
Snapshot Reads and Read-Only Transactions
In traditional strongly consistent databases, read operations often need to acquire locks (S-Lock) to prevent conflicts with write operations, which significantly reduces system throughput in high-concurrency scenarios. A major technical breakthrough of Google Spanner is that it uses Multi-Version Concurrency Control (MVCC) and the TrueTime API to implement lock-free read-only transactions.
Spanner’s read-only transactions have the following key characteristics:
- Lock-free mechanism: Read operations never block write operations, and vice versa.
- External consistency: By default, read-only transactions guarantee reading all data committed before the transaction began (i.e., strong consistency).
- Globally consistent snapshot: Even if data is distributed across global data centers, the transaction can see a consistent view of the entire database at a specific point in time T.
The foundation of read-only transactions is snapshot reads. Because every write operation in Spanner is stamped with a timestamp based on TrueTime, the database actually stores multiple versions of data. When executing a snapshot read, Spanner first determines a read timestamp T_read. The system guarantees: for any transaction committed before T_read (≤ T_read), its result is visible to this read; for any transaction committed after T_read (> T_read), its result is completely invisible to this read.
The execution of read-only transactions can be divided into two main phases: timestamp selection and safe read.
Timestamp selection is the key step in determining the consistency level. To guarantee linearizability, i.e., “see all writes that just happened,” Spanner must choose a sufficiently new timestamp.
- Strategy: Spanner sets T_read to the upper bound of the current moment, i.e., T_read =
TT.now().latest. - Principle: Combined with the Commit Wait mechanism in write transactions, any write transaction that has received a “commit successful” response must have a commit timestamp S_commit smaller than the current moment. Therefore, using
TT.now().latestas the read time point will inevitably cover all committed history.
After determining T_read, the client can send read requests to any replica containing the target data, not just the Leader, which makes Spanner’s read performance scale linearly with the number of replicas.
However, how to ensure that the selected replica (possibly a follower) already has data at time T_read? Here the concept of Safe Time (t_safe) is introduced.
Each replica maintains a t_safe value. It indicates that the replica has synchronized all logs with timestamps less than or equal to t_safe through the Paxos protocol. In other words, the replica is certain that all transactions before t_safe have been synchronized to it locally.
When a replica receives a read request with timestamp T_read, it performs the following judgment:
- If T_read ≤ t_safe: This means the replica’s data is new enough, and it can execute the read and return the result immediately. This is the most ideal situation, completely non-blocking.
- If T_read > t_safe: This means the replica’s data is lagging and has not yet synchronized to the state at time T_read. At this point, the replica must wait until it synchronizes new logs through Paxos and t_safe advances past T_read.
The figure below is a sequence diagram of Spanner’s read-only transaction execution flow.
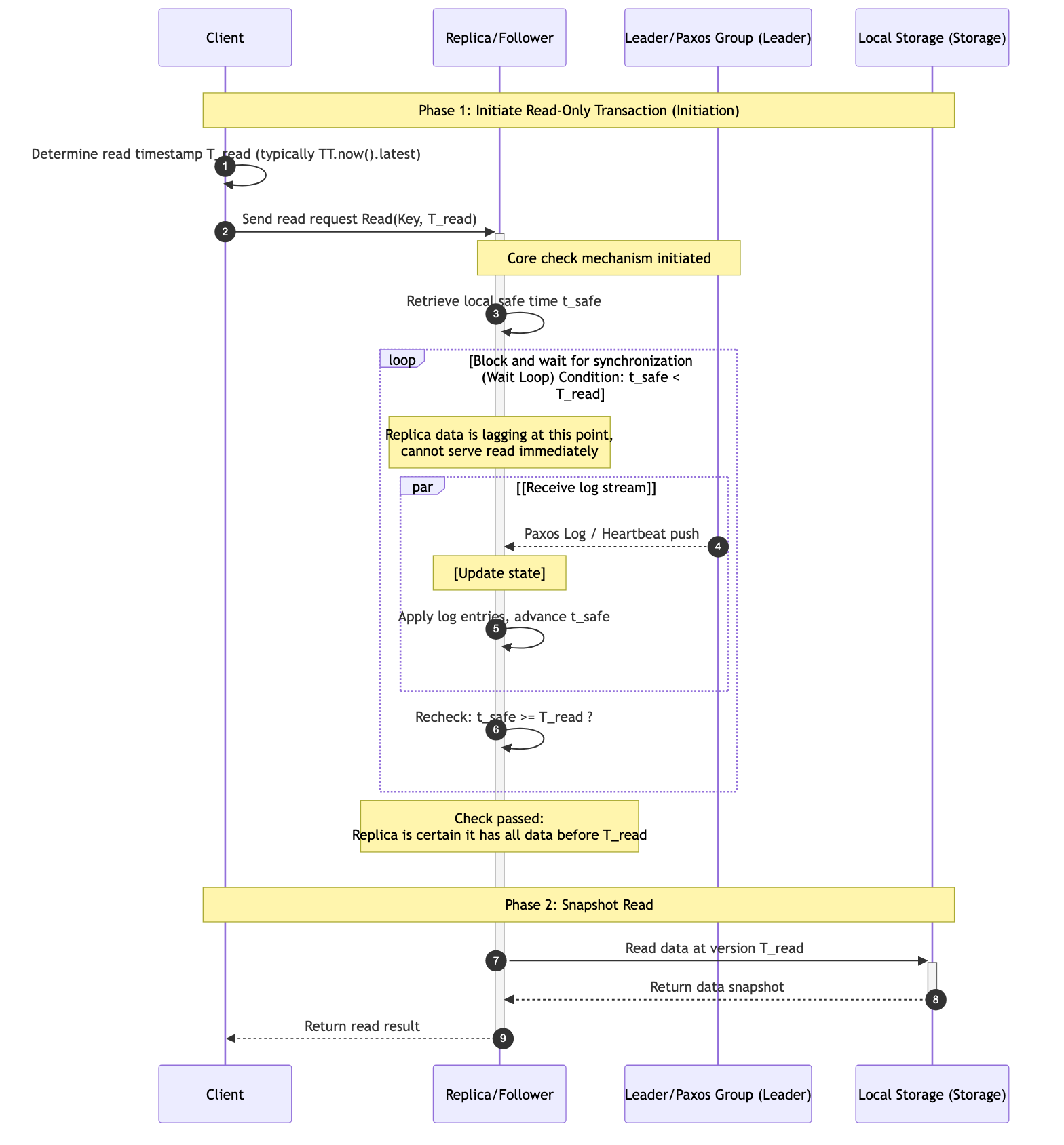
If a read-only transaction needs to read data A and B located in different Paxos Groups (different shards), the flow is as follows:
- Determine global timestamp: The client or coordinator node determines a unified T_read at the start of the transaction (for example,
TT.now().latest). - Concurrent dispatch: The client carries this same T_read and concurrently sends read requests to the replica holding A and the replica holding B.
- Independent execution: The A replica and B replica process requests independently according to their own t_safe.
- Result aggregation: The client receives all results.
Summary #
Traditional 2PC algorithms have two major problems: single-point failure and poor performance. Spanner introduces TrueTime and Paxos on top of 2PC to solve these two problems:
- Single-point failure: In traditional 2PC, if a node crashes, the transaction gets stuck. In Spanner’s architecture, every participant and coordinator in 2PC is not a single node, but a Paxos group; even if a node within it crashes, the transaction can continue to run and complete, avoiding the single-point failure problem. 2PC solves the atomicity problem across shards. That is: how to make different data succeed or fail together. Paxos solves the high-availability problem. That is: how to keep multiple replicas of the same data consistent.
- Read/write performance: Another pain point of traditional 2PC is performance, especially because read operations are also locked. Under strong consistency requirements, read operations must wait for write operations to complete (lock conflict), or read operations must ask the Leader (network latency). Aiming at the “read-more-write-less” characteristic of Internet applications, Spanner uses MVCC (Multi-Version Concurrency Control) to implement near-perfect read-only transactions. Through the Safe Time mechanism, Spanner allows clients to perform strongly consistent reads on any replica (including non-Leader replicas). This “lock-free read” not only greatly improves the system’s parallel processing capability, but also disperses traffic to edge nodes around the world, significantly reducing user access latency.
TCC Transactions #
In the transfer example given when explaining BASE, the system does not satisfy isolation requirements; before final consistency is reached, the sum of the balances of the two accounts in the system may be inconsistent. In some business scenarios with isolation requirements, this is unacceptable. For example, in an e-commerce shopping scenario, if the customer receives a payment success response before inventory is deducted, overselling may occur.
The TCC introduced in this subsection is another common mechanism for implementing distributed transactions. It was originally proposed by Pat Helland in 2007[21]. TCC is the acronym of Try-Confirm-Cancel. TCC is a compensating distributed transaction solution that ensures eventual consistency through business-logic splitting and compensation mechanisms.
The core idea of TCC transactions is “Resource Reservation.” It is a variant and optimization of two-phase commit. Unlike traditional two-phase commit protocols, TCC transactions do not lock database resources for a long time, but elevate the granularity of locks from the “database” level to the “business” level, controlled by the application (code) itself.
TCC transactions decompose a complete business operation into two phases:
Phase 1: Try (Attempt/Reserve)
In the first phase, all resources required by the business are checked and reserved. This is not the real execution of the business, but a preparatory operation. For example, instead of directly deducting inventory, “freeze” the inventory; instead of directly deducting payment, “freeze” the corresponding amount in the user’s account. All operations in the first phase must be reversible, i.e., they have corresponding undo operations.
Phase 2: Execute Confirm or Cancel Based on Try Phase Results
If all participants’ Try operations succeed, the Confirm operation will be executed, which truly executes the business and completes the final change of resources. The Confirm operation uses the resources reserved in the Try phase to complete the operation. For example, the “frozen” inventory becomes “deducted”; the “frozen” amount is actually transferred from the user’s account. The Confirm operation must be idempotent, because retries may occur due to network failures.
If any participant’s Try operation fails, the Cancel operation will be executed, which cancels all reservations made in the Try phase and releases resources, restoring data to the state before the transaction began. For example, unfreeze the previously frozen inventory; unfreeze the amount in the user’s account. The Cancel operation must also be idempotent.
Because the three-phase interfaces are implemented by the business, the following matters need attention:
- TCC’s Confirm phase and Cancel phase may be called multiple times due to network retries, etc., so they must be implemented as idempotent interfaces supporting repeated calls.
- It is necessary to handle cases where messages from different phases may arrive out of order, such as the Cancel phase arriving before the Try phase in the same transaction.
- Because TCC transactions provide three-phase interfaces by services, isolation also needs to be provided by the business. For example, resources locked in the Try phase must not be visible or modifiable by other transactions.
Taking cross-bank transfer as an example, suppose user A (bank 1) wants to transfer 100 to user B (bank 2). The three-phase flow to be designed is shown below:
| Service | Try | Confirm | Cancel |
|---|---|---|---|
| Bank 1 (payer) | 1. Check whether A’s balance is greater than 100. 2. Freeze 100 in A’s account. | Deduct the “frozen” 100 from A’s account. | Unfreeze the “frozen” 100 in A’s account. |
| Bank 2 (payee) | Check whether B’s account is valid and in normal status. | Add 100 to B’s account. | Do nothing |
TCC transactions usually require a coordinator responsible for interacting with the various services involved in the transaction. The figures below demonstrate the success and failure flows of cross-bank transfer.
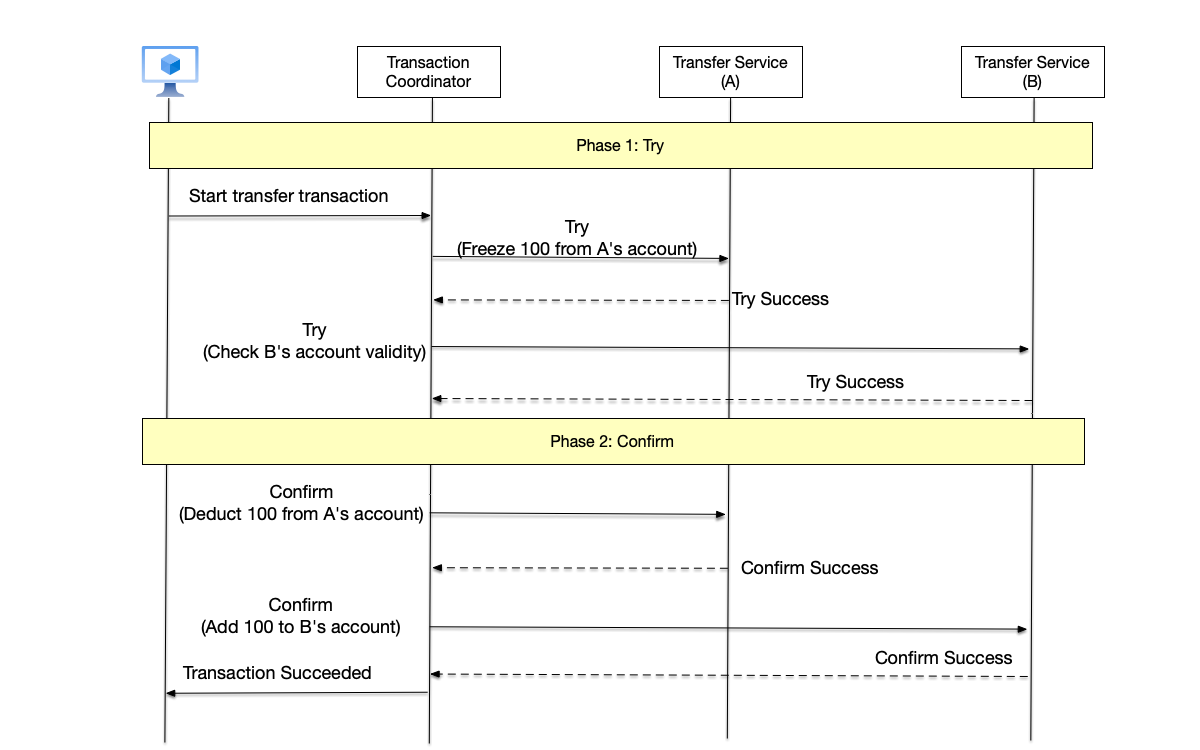
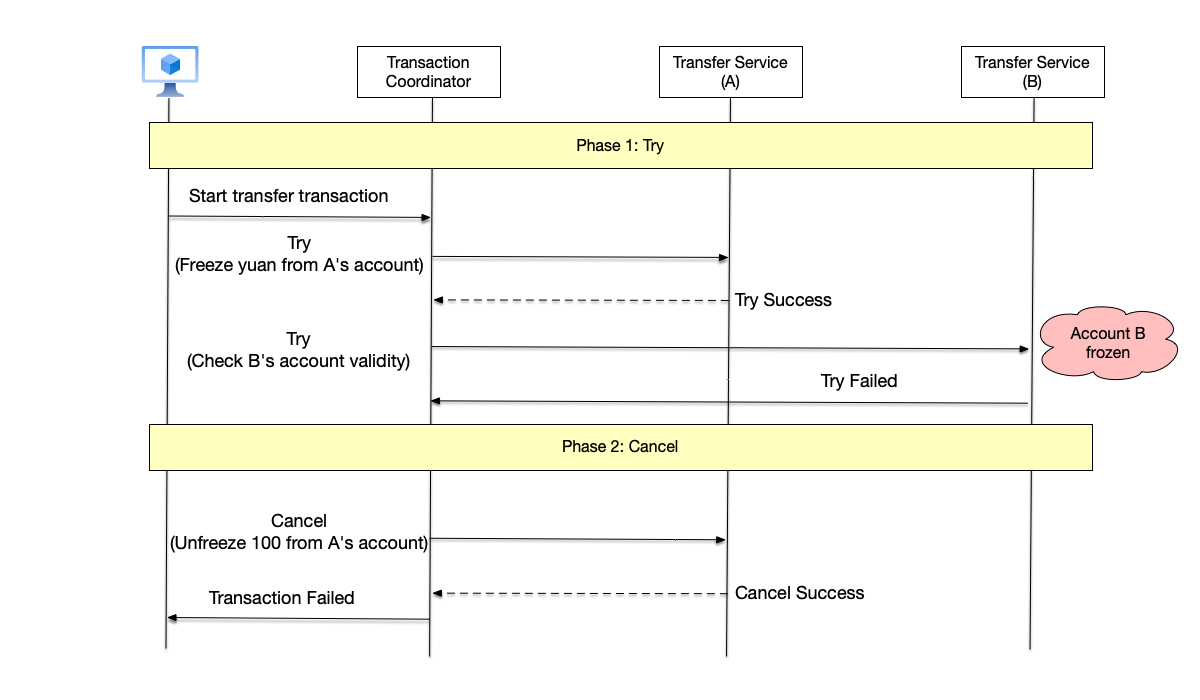
As can be seen, the TCC transaction process is very similar to two-phase commit, but has the following differences:
- 2PC acts at the resource layer, while the three interfaces of TCC transactions are provided by the business; this also means that TCC transactions have stronger intrusion into the business and higher business transformation costs.
- In the Prepare phase of 2PC, all participants vote on whether to prepare; in the Try phase of TCC transactions, there is no preparation vote, but resources are frozen.
- The business needs to implement different rollback strategies according to different failure reasons, and also needs to ensure the idempotency of Confirm and Cancel interfaces.
SAGA Transactions #
TCC transactions have strong intrusion into the business, requiring the business to implement TCC’s three-phase interfaces. For some business scenarios with long processes, many steps, and the need to call third-party company services, it is difficult to require these external services to cooperate with TCC transaction interfaces. For example, in some e-commerce scenarios, it is necessary to call external banking systems’ deduction services, and it is difficult to require these third-party services to follow TCC transaction interface specifications.
For such business scenarios, the SAGA distributed transaction pattern was first proposed in 1987[22] to improve the efficiency of Long Lived Transactions, and is more suitable for business scenarios with long processes, many steps, and difficulty implementing TCC transaction three-phase interfaces. In this sequence, each local transaction completes its own business operation within its service and commits immediately. If a certain step in the entire SAGA process fails, the system will call a series of Compensating Transactions to undo all previously successful local transactions, thereby bringing the entire system back to a consistent state. Simply put, SAGA’s philosophy is: allow moving forward, but ensure there is a way back.
Specifically, a SAGA distributed transaction consists of the following two parts:
- Local transactions: SAGA splits a large distributed transaction into n small subtransactions, named T_1, T_2 … T_n. These subtransactions will be executed sequentially, and each subtransaction should be considered an atomic operation. For example, in a purchase action, it can be divided into deduction, inventory deduction, and shipment subtransactions. If each subtransaction can correctly commit in execution order, the effect is equivalent to the successful commit of the large distributed transaction.
- Compensating transactions: For each subtransaction, design the corresponding compensation operation, such as “cancel order,” “return inventory,” etc., named C_1, C_2 … C_{n-1}, used when a certain subtransaction execution fails to execute reverse compensation operations for previously successful subtransactions.
Taking a banking system deduction operation as an example, if in a TCC transaction the banking system needs to implement the Try interface of the TCC transaction, in this interface it freezes the corresponding amount in the account and ensures that the frozen amount is not visible to other transactions before the transaction commits or rolls back; in addition to implementing the account freezing operation, the banking system also needs to implement an undo freeze operation for rollback calls. If SAGA transactions are used, the banking system does not need to implement extra interfaces, because the compensation operation corresponding to the deduction operation only needs to add the corresponding amount back to the account; this interface is already implemented by the banking system, and is controlled by the distributed transaction initiator to execute.
As can be seen, compared with TCC transactions, SAGA distributed transactions have less intrusion into the business and smaller transformation scope, and are especially suitable for businesses that need to call third-party services or legacy services.
When a SAGA transaction execution fails, there are two recovery modes, as shown below:
- Forward Recovery: If a certain subtransaction T_i fails, in this mode it will keep retrying until it succeeds. For example, in an e-commerce shopping scenario, if deduction succeeds, shipment must be guaranteed to succeed, otherwise it will keep retrying.
- Backward Recovery: If a certain subtransaction T_i fails, the compensation operations of the subtransactions that have already successfully executed before it will be called in turn to complete the transaction rollback. After subtransaction T_i fails, compensation operations will start from C_{i-1}.
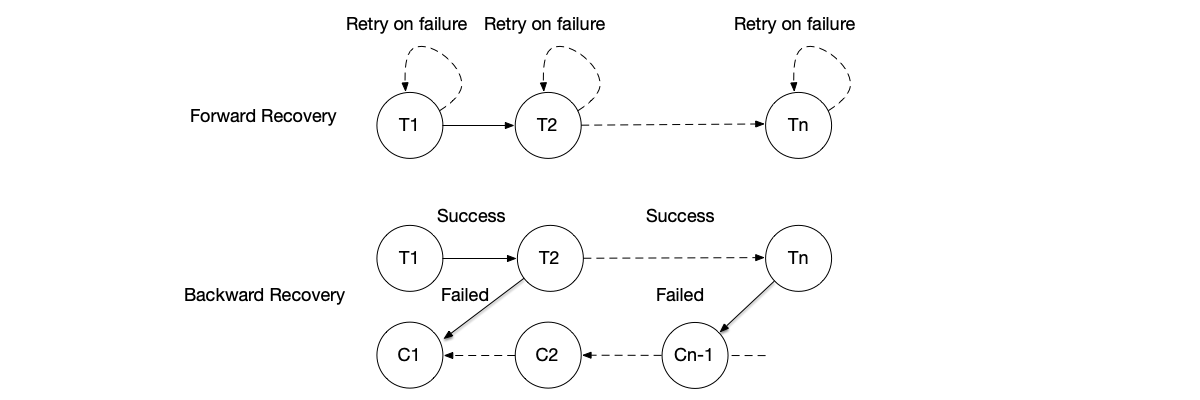
Taking an airplane ticket purchase system as an example, explain the forward and reverse flows in SAGA:
- Forward flow:
- Create an airline ticket order, reserving 15 minutes.
- Lock the seat on the corresponding flight; within the reservation time, no one else is allowed to book it.
- Initiate a payment order request to the user.
- If the user pays successfully, confirm the order purchase success and send a notification to the user.
- Reverse flow: If the user does not complete payment within the reserved 15 minutes (for whatever reason), the corresponding compensation operations are: unlock the seat on the corresponding flight and cancel the order.
Because SAGA transactions divide a distributed transaction into multiple subtransactions for execution, each subtransaction is an atomic operation, and data isolation cannot be guaranteed between subtransactions. This means that when a SAGA transaction is not yet complete, other transactions can see the intermediate state. For example, after the user’s bank account has been deducted but before inventory has been deducted, the user’s bank account data has been deducted, but the inventory quantity in the product service has not yet changed. It can be seen that SAGA transactions have weak data isolation, so SAGA transaction business scenarios require subtransactions to be relatively independent and have low isolation requirements. Therefore, services using SAGA transactions must be designed to handle this “dirty read” scenario. For example, order status can be designed as Pending rather than directly Completed.
SAGA transactions guarantee eventual consistency, not strong consistency. After a subtransaction fails, the system will be in an inconsistent state for a short time (for example, inventory is deducted, but the order is ultimately cancelled), and the business state can only be restored after compensation is completed.
In addition, compensation operations in SAGA transactions must satisfy idempotency, because compensation operations may be retried (for example, due to network failure), and executing once must produce the same result as executing multiple times. In the case of compensation operation failure, the situation may be very complex. For example, in an e-commerce service, if final payment fails and inventory compensation is needed, what if this step also fails? If it keeps failing, this scenario may require manual intervention based on logs.
Finally, not all types of operations can be compensated. For example, if an operation is “send an email” or “ship a product,” this type of operation cannot truly be “undone,” so not all business types are suitable for SAGA transactions.
In addition to the differences in business intrusion and applicable scenarios, TCC and SAGA also have essential differences in concurrency control and isolation mechanisms. This difference directly determines their resistance to problems such as “overselling” and “dirty reads” in high-concurrency scenarios.
- TCC’s resource reservation mechanism (strong isolation): TCC’s core advantage lies in the resource locking of the Try phase. By explicitly freezing resources at the business level (for example, changing inventory from “available” to “frozen”), TCC actually implements an application-layer “pessimistic lock.” This mechanism ensures that resources are absolutely available when the Confirm phase is executed. Therefore, TCC performs excellently in dealing with resource competition under high concurrency (such as flash sales); it can effectively prevent overselling and logically guarantees better isolation, avoiding other transactions reading unavailable resources.
- SAGA’s lack of isolation (weak isolation): In contrast, SAGA sacrifices isolation for the execution efficiency of long processes. In SAGA mode, every subtransaction (Local Transaction) is directly committed to the database, which means data changes are immediately visible to other concurrent transactions. SAGA lacks a resource reservation phase similar to TCC, which causes it to naturally face the challenge of lack of isolation.
This characteristic causes two serious problems in concurrent scenarios:
- Dirty reads and cascading rollback risk: If a subtransaction of transaction A modifies data, and transaction B then reads that data and performs subsequent operations based on it; once transaction A subsequently fails and triggers compensation (rollback), the data held by transaction B becomes invalid “dirty data,” and may even cause transaction B to also have to perform complex cascading rollbacks.
- Non-commutativity: If concurrent SAGA transactions involve modifications to the same resource, and the operation does not satisfy commutativity (for example, calculating interest or non-additive numerical updates), the randomness of execution order may cause the final result to be incorrect due to the lack of a locking mechanism.
Therefore, SAGA is more suitable for long-process scenarios with low concurrency conflicts or where business operations satisfy commutativity (Commutative, such as simple addition and subtraction operations). In high-concurrency financial/e-commerce core links where overselling must be strictly prevented or intermediate-state visibility is sensitive, TCC is often a safer choice.
Chapter Summary #
In this chapter, starting from the logical correctness of data operations, we systematically explored transaction technology in distributed systems. As a cornerstone of building reliable systems, transaction technology shields the complexity brought by underlying hardware failures, concurrency conflicts, and network uncertainty, providing the upper-layer application with an “all-or-nothing” atomicity promise.
First, we based ourselves on single-node databases and deeply analyzed the implementation principles of ACID properties. We learned that atomicity (A) and durability (D) do not come out of thin air, but rely on the log mechanism of Undo Log and Redo Log (WAL) to respectively implement failure rollback and crash recovery. In the field of concurrency control, we discussed the evolution from pessimistic Two-Phase Locking (2PL) to optimistic MVCC (Multi-Version Concurrency Control). Especially MVCC, by maintaining multi-version history of data, achieves a highly efficient concurrency mode of “reads and writes never block each other,” and has become the standard implementation of modern mainstream databases. However, we also pointed out that even under MVCC, anomalies such as write skew still exist, and need to be avoided through reasonable selection of isolation levels.
Subsequently, we expanded our view to distributed systems. In scenarios spanning networks and nodes, facing severe challenges of partial failure and communication delay, traditional ACID properties are constrained by the CAP theorem. In response, this chapter presented two completely different technical evolution routes:
- Hard transactions pursuing strong consistency: Represented by 2PC (Two-Phase Commit), although it provides strict atomicity guarantees, it also introduces synchronous blocking and single-point failure risks. As the pinnacle of this field, we focused on deconstructing the architectural design of Google Spanner. Spanner creatively combines TrueTime atomic-clock technology, the Paxos consensus algorithm, and 2PL, achieving External Consistency on a global cross-continental scale, breaking the traditional belief that “strong consistency cannot scale horizontally,” and pointing the direction for NewSQL databases.
- Soft transactions pursuing high availability: Based on the BASE theory, we abandon immediate strong consistency and instead pursue eventual consistency at the business level. We introduced in detail the TCC (Try-Confirm-Cancel) mode, which achieves finer-grained control through business resource reservation; and the SAGA mode, which solves the efficiency problem of Long Lived Transactions through the orchestration of forward operations and compensation operations. Although these two types of solutions have strong intrusion into business code, they provide excellent system availability in high-concurrency Internet scenarios.
In summary, there is no “silver bullet” for distributed transactions. From single-node ACID to distributed 2PC/3PC, to Spanner’s TrueTime innovation, and the business compromises of TCC/SAGA, the essence is to find the best balance point among data consistency, system availability, and performance. As system designers, understanding the principles and costs behind these technologies and making appropriate trade-offs according to specific business scenarios is the essence of mastering distributed transactions.
References #
- Andreas Reuter and Theo Härder. “A Transaction Model.” ACM Transactions on Database Systems, 1983.
- Wikipedia. Isolation (database systems). https://en.wikipedia.org/wiki/Isolation_(database_systems)
- Wikipedia. Two-phase locking. https://en.wikipedia.org/wiki/Two-phase_locking
- Wikipedia. Optimistic concurrency control. https://en.wikipedia.org/wiki/Optimistic_concurrency_control
- H.T. Kung and John T. Robinson. “On Optimistic Methods for Concurrency Control.” ACM Transactions on Database Systems, 1981.
- Wikipedia. Multiversion concurrency control. https://en.wikipedia.org/wiki/Multiversion_concurrency_control
- David P. Reed. “Naming and Synchronization in a Decentralized Computer System.” PhD Dissertation, Massachusetts Institute of Technology, 1978.
- Philip A. Bernstein and Nathan Goodman. “Concurrency Control in Distributed Database Systems.” ACM Computing Surveys, 1981.
- PostgreSQL. VACUUM. https://www.postgresql.org/docs/current/sql-vacuum.html
- PostgreSQL. Introduction to MVCC. https://www.postgresql.org/docs/7.1/mvcc.html
- MySQL. InnoDB Multi-Versioning. https://dev.mysql.com/doc/refman/8.4/en/innodb-multi-versioning.html
- Wikipedia. List of databases using MVCC. https://en.wikipedia.org/wiki/List_of_databases_using_MVCC
- A fable in which each blind man touches a different part of an elephant and draws a different conclusion.
- Wikipedia. Snapshot isolation. https://en.wikipedia.org/wiki/Snapshot_isolation
- Michael J. Cahill et al. “Serializable Isolation for Snapshot Databases.” ACM Transactions on Database Systems, 2008.
- Dan Pritchett. “BASE: An ACID Alternative.” ACM Queue, 2008.
- Wikipedia. Two-phase commit protocol. https://en.wikipedia.org/wiki/Two-phase_commit_protocol
- Wikipedia. Three-phase commit protocol. https://en.wikipedia.org/wiki/Three-phase_commit_protocol
- James C. Corbett et al. “Spanner: Google’s Globally-Distributed Database.” Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2012.
- Keith Marzullo. “Maintaining the Time in a Distributed System.” ACM Symposium on Principles of Distributed Computing, 1983.
- Pat Helland. “Life beyond Distributed Transactions: An Apostate’s Opinion.” CIDR, 2007.
- Hector Garcia-Molina and Kenneth Salem. “Sagas.” Proceedings of the 1987 ACM SIGMOD International Conference on Management of Data, 1987.