In the preceding chapters, we discussed how replication can prevent data loss caused by single points of failure, how partitioning can handle massive amounts of data, and how distributed transactions can ensure the atomicity of cross-node operations.
However, when we try to combine these mechanisms into a truly production-grade system that runs 24/7 with automatic fault tolerance, we discover an obvious gap: how can surviving nodes reach agreement on the system state when some nodes have failed?
The traditional two-phase commit protocol (2PC) solves the consistency problem of “all nodes either commit together or roll back together,” but it is blocking—once the coordinator fails, the entire cluster may block indefinitely. This reveals a deeper challenge in distributed systems: we need a fault-tolerant consensus mechanism. That is, even if a minority of nodes in the cluster (e.g., less than half) crash or are network-partitioned, the system can still continue to make progress and serve externally.
This is where consensus algorithms come into play.
Essentially, consensus algorithms solve the famous “agreement” problem in distributed computing: in an unreliable network environment, a group of concurrent processes proposes a value, and finally reaches a unique, irreversible agreement on that value.
This seemingly simple goal is in fact the core challenge of distributed systems. Consensus algorithms are not only the theoretical foundation for implementing state machine replication, but also the core engine for modern distributed databases to achieve automatic leader election, atomic broadcast, and configuration changes. Whether it is the elegant theory of Paxos or the engineering practice of Raft, they both aim to abstract the uncertain physical world (packet loss, delay, downtime) into a logically strictly ordered whole.
In this chapter, we will explore in depth the principles and evolution of consensus algorithms, and understand how they find the perfect balance between “consistency” and “availability.”
Introduction to Consensus Algorithms #
Overview #
In distributed systems, the consensus problem occupies a central position. Before this, we discussed guaranteeing data durability through replication and expanding system capacity through partitioning. However, when these mechanisms face partial node failures or network partitions, how to make the entire system still act like a single, coherent whole is the fundamental problem that consensus algorithms aim to solve.
Intuitively, consensus is the process by which multiple participants (processes or nodes) reach a unanimous view on a specific value. This “value” can represent different meanings in different scenarios: it may be a boolean (deciding whether to commit or roll back a transaction), an elected primary node ID (leader election), or a specific log entry. This definition seems abstract, but it actually covers a wide range of practical application scenarios:
- In primary-backup replication, clients need to write data through the primary node. Therefore, nodes need to elect a leader to coordinate task distribution, log replication, and other work. Without a reliable consensus mechanism, multiple nodes may simultaneously believe that they are the leader, leading to a split-brain scenario and causing data conflicts.
- In distributed databases, distributed storage, and other systems, data is usually replicated to multiple nodes to improve availability and fault tolerance. However, how to ensure that all replicas remain consistent during writes? This requires consensus algorithms to coordinate the write order and results.
- Consider the bank transfer problem. User A wants to transfer money to user B. This involves two operations: deducting the amount from user A’s account and adding the amount to user B’s account. These two operations must be combined into an “atomic operation”: either both succeed or both fail. In terms of specific operations, all nodes in the system need to reach agreement on this atomic operation: all nodes commit successfully, or all abort and roll back the data.
- When cluster configuration changes, such as when nodes are added or removed, this configuration information also needs to reach consensus among the nodes in the cluster.
- The system state is composed of events in order. Therefore, if a group of events can maintain the same order across all nodes in a distributed system, then these events will produce the same state on all nodes. This “event order” is also a form of consensus.
- When multiple nodes in the system need to access critical section resources, the access order needs to be determined.
Although the above problems are different, and the content that needs to be agreed upon varies in different scenarios, they all share a common characteristic: the nodes in the system need to reach agreement on some shared information.
Difficulties of Consensus Algorithms #
If the network were perfectly reliable, or if there were no delays between nodes, reaching consensus would be easy. The complexity and difficulty of consensus algorithms stem from the fact that the distributed environment we are in is usually asynchronous and unreliable.
In this environment, consensus algorithms face the following core challenges:
- Node failures: Nodes may stop working due to hardware failures, software errors, or power outages. Consensus algorithms need to ensure that the system can still reach consensus even if some nodes fail.
- Network problems: Nodes in distributed systems communicate through the network, which may face delays, partitions, or message loss. Consensus algorithms need to handle these problems through timeouts, retries, or voting mechanisms.
- Byzantine failures: Some nodes may exhibit malicious behavior, such as sending incorrect messages, forging data, or deliberately not responding. Consensus algorithms need to design mechanisms to identify and isolate malicious nodes.
- Data consistency: In distributed databases or file systems, multiple replicas need to remain consistent. Consensus algorithms solve this problem by defining how to choose the “correct” value.
Imagine a group of explorers searching for treasure in a foggy forest. Each person has an incomplete map (the node state in a distributed system). They need to decide on a meeting place by shouting (network communication), but someone may get lost (node failure), someone may deliberately point in the wrong direction (Byzantine failure), and someone may not hear the shouting clearly (network delay). A consensus algorithm is like a magic protocol that ensures all honest explorers eventually gather in the same place, even in the face of these challenges.
Consensus and Consistency #
Due to the influence of translation, many materials discussing consensus algorithms call them “distributed consistency algorithms.” Although the words “consistency” and “consensus” are very similar, they have clear distinctions and close connections in distributed systems.
Consistency
Consistency refers to whether data between multiple replicas is consistent, or whether the client sees a consistent data view when accessing the system. Consistency is more about viewing the system state from an external perspective, emphasizing whether the results of read and write operations conform to the expected behavior model.
Consensus
Consensus is a protocol or algorithmic mechanism used to reach agreement on a value among multiple nodes. It is a means of achieving consistency, especially in multi-replica systems, where consensus is an important tool for achieving strong consistency.
Consensus protocols usually satisfy the following properties:
- Termination: All non-faulty nodes eventually make a decision.
- Agreement: All non-faulty nodes agree on the same value.
- Validity: The consensus value must be a legal value proposed by some node.
Consensus focuses more on the internal logical coordination mechanism and is the specific technical path the system takes to achieve a certain consistent state.
According to the safety and liveness goals, a distributed consensus algorithm must satisfy:
- Safety: Different nodes in the system cannot decide on conflicting values. For example, the system cannot have more than one primary node at the same time, and it cannot happen that some nodes commit one value while other nodes commit another value.
- Liveness: Ensures that the system can eventually decide on a value even when some nodes fail or network problems occur.
Although the two are different, they are inseparable in many scenarios:
- Consensus is one way to achieve consistency. For example, through consensus algorithms such as Paxos and Raft, the log order of multiple replicas can be ensured to be consistent, thereby achieving linearizability.
- Consistency is a description of system behavior, while consensus is the implementation of the system mechanism. Consistency can be regarded as the goal, and consensus is one of the tools to achieve that goal.
For example, in a distributed database, the client wants to see the latest write result (strong consistency requirement). Then the system may internally use the Raft protocol to synchronize the logs of each replica (consensus mechanism), thereby ensuring that the data returned when reading is the latest.
FLP Impossibility Theorem #
The previous section gave a brief introduction to consensus algorithms. A natural question arises: does there exist a general, perfect consensus algorithm that can work reliably in any network environment?
In 1985, three scientists, Fischer, Lynch, and Paterson, published the famous paper Impossibility of Distributed Consensus with One Faulty Process [1], providing a sobering yet crucial answer. This conclusion was later called the FLP impossibility theorem. It delineated an insurmountable theoretical boundary for the consensus problem in distributed systems, profoundly influencing the design philosophy of distributed systems for the subsequent forty years.
The core conclusion of the FLP theorem can be stated as: In a fully asynchronous distributed system, even if only one process may suffer a crash fault, there does not exist a deterministic consensus algorithm that can guarantee reaching consensus within a finite amount of time.
In short, in an asynchronous system, a consensus algorithm cannot simultaneously satisfy safety (i.e., agreement), liveness (i.e., termination), and fault tolerance. This is known as the “impossible triangle” of distributed consensus.
To truly understand the profound meaning of the FLP theorem, one must first understand the “system model” it describes and its key assumptions:
- The process failure model adopts the crash model: This is a very mild failure model. Nodes only stop running due to crashes. They will not produce malicious deception or tamper with data like Byzantine failures. The theorem points out that even the simplest downtime can destroy consensus.
- Communication is reliable: Messages may be out of order, but they will eventually be delivered. They will not be lost or tampered with.
- Fully asynchronous environment: This is the root of the problem. In an asynchronous system, there is no global clock, and the time for processes to process messages, the time for messages to pass through the network, and clock drift between different processes have no upper bound.
In such an asynchronous environment, a fatal ambiguity appears: when process A sends a message to process B but has not received a response for a long time, process A cannot judge at all whether process B has “crashed” or is merely “very slow.”
The essence of the FLP theorem reveals the destructive power of “uncertainty” on algorithmic decision-making.
Imagine a group of explorers (distributed nodes) trying to decide on a meeting place by passing notes (messages) in a foggy forest.
- To guarantee safety: The explorers agree that they must receive confirmation from all key teammates before acting, lest everyone goes to different places.
- To guarantee liveness: The explorers hope to make a decision as soon as possible and cannot wait forever.
Suppose explorer A makes a proposal, but explorer B has not responded. At this point, the system faces two choices:
- If B is truly incapacitated (crashed), A should ignore B and reach consensus with other teammates to guarantee liveness.
- If B is just walking very slowly (asynchronous delay), if A rashly decides to ignore B, when B finally arrives, B may propose a different suggestion, thereby destroying consistency.
In a fully asynchronous system, no “timeout mechanism” is absolutely reliable. At any time, the algorithm may be in a critical state: waiting further may lead to infinite waiting (sacrificing liveness), while not waiting may lead to wrong decisions due to incomplete information (sacrificing safety). FLP proves that a clever adversary can always control message delays and scheduling to keep the algorithm forever wandering on the edge of “reaching consensus,” but never crossing that line.
The proof of the FLP impossibility theorem is beyond the scope of this book. Readers can refer to the original paper or [2]. The following provides an intuitive explanation of the theorem. Because the system is asynchronous, an algorithm cannot distinguish whether a process has “crashed” or is “just very slow.” Any deterministic algorithm that pursues “agreement,” in order to ensure safety (no disagreement), when encountering a suspicious situation (such as waiting for a response from a process), must wait indefinitely. This causes the algorithm to potentially never satisfy “termination,” i.e., falling into infinite waiting.
Conversely, if the algorithm pursues “termination” (making a decision as soon as possible), it may, under some extreme timing, cause different processes to make different decisions based on incomplete information, thereby destroying “consistency.”
At first glance, the FLP theorem seems to sound the death knell for distributed consensus. Since it is theoretically “impossible,” why do we still study algorithms such as Paxos and Raft, and why do they work well in engineering?
In fact, the FLP theorem was not intended to hinder development, but to point the way. It tells us not to try to find a perfect solution in a purely asynchronous model, but to make compromises or relax assumptions in the model. In engineering practice, mainstream consensus algorithms usually adopt the following strategies to “bypass” the limitations of FLP:
- Relax the assumption of “asynchrony” (introduce failure detection): Real networks, although unreliable, are usually not completely asynchronous. We introduce “failure detectors” (such as heartbeat mechanisms and timeout judgments). Although timeout judgments are not always accurate, this transforms the “asynchronous model” into a “partially synchronous model.” Raft and Paxos actually rely on this assumption.
- Sacrifice determinism (introduce randomness): Some algorithms introduce random numbers. When nodes cannot decide, they randomly choose a value or randomly wait for a period of time. This randomness breaks the symmetry that leads to infinite loops.
- Sacrifice liveness for safety: This is the most common trade-off. Taking Paxos and Raft as examples, they adhere to the “safety” bottom line in their design. When the network is extremely unstable or split-brain occurs, the algorithm may temporarily stop serving (losing liveness) until the network recovers stability.
In summary, the FLP impossibility theorem is the “uncertainty principle” of the distributed field. It reminds architects and developers: when designing distributed systems, trade-offs must be made between consistency, availability, and network delay.
Paxos Algorithm #
The Paxos algorithm [3] was proposed by Leslie Lamport [4] as a distributed consensus algorithm. In the field of distributed consensus, it is almost synonymous with “consensus” itself. In the words of Mike Burrows [5], author of Chubby:
“There is only one consensus protocol, and that’s ‘Paxos’—all other approaches are just broken versions of Paxos.”
Although this statement is slightly exaggerated, it is undeniable that modern consensus algorithms, including Raft and ZAB (ZooKeeper Atomic Broadcast), share the same core ideas as Paxos in essence.
However, Paxos is notorious for being “obscure and difficult to understand.” Its extremely high level of abstraction makes engineering implementation exceptionally difficult. In the following subsections, we will avoid complex mathematical proofs and directly delve into the principles of Paxos to explore how it establishes order in a chaotic distributed environment through two-phase interaction.
Birth of the Paxos Algorithm #
Leslie Lamport first proposed the Paxos algorithm in 1988. The original paper The Part-Time Parliament [6] was submitted in 1990, but was not officially published in ACM Transactions on Computer Systems until 1998. The paper faced challenges in publication for the following reasons:
- Lamport used a very peculiar narrative style in the paper: he packaged the distributed consistency problem into a fictional story about a parliament on the ancient Greek island of “Paxos,” where legislators voted on laws by sending letters. Although the metaphor was vivid, it left reviewers at the time baffled. As a result, the paper was rejected several times. This paper was not accepted until 1998.
- Lamport was quite dissatisfied with the academic review process. To make it easier for everyone to understand, he wrote another more straightforward paper in 2001, Paxos Made Simple [7], directly discarding the “Paxos island” story and explaining the algorithm with clearer terminology. However, Lamport joked in the paper: “The Paxos algorithm is simple only after you have already understood it.”
It can be seen that in the first few years after the Paxos paper was published, it did not attract much attention from the industry. It was not until 2006, when Google’s Chubby [8] service used the Paxos algorithm to solve distributed consensus problems, that people began to study the Paxos algorithm. In 2013, Lamport received the Turing Award for his outstanding theoretical contributions to distributed systems.
Intuitive Explanation of Paxos #
Unlike other literature that reiterates the original paper, this book takes a different approach to explaining Paxos. To help readers better understand the “why” of the Paxos algorithm, we start from the problem that consensus algorithms need to solve, consider various different strategies, and derive the core idea of the Paxos algorithm step by step [9].
In a distributed system, for high availability of the system, a certain degree of redundancy must be provided. Consensus algorithms were proposed precisely to solve the strong consistency problem when replicating data. Returning to the root of the problem, consensus algorithms can be regarded as a “replication strategy” for replicating data among nodes. Below, we try different replication strategies one by one to see what problems each of them encounters.
Imperfect Replication Strategies #
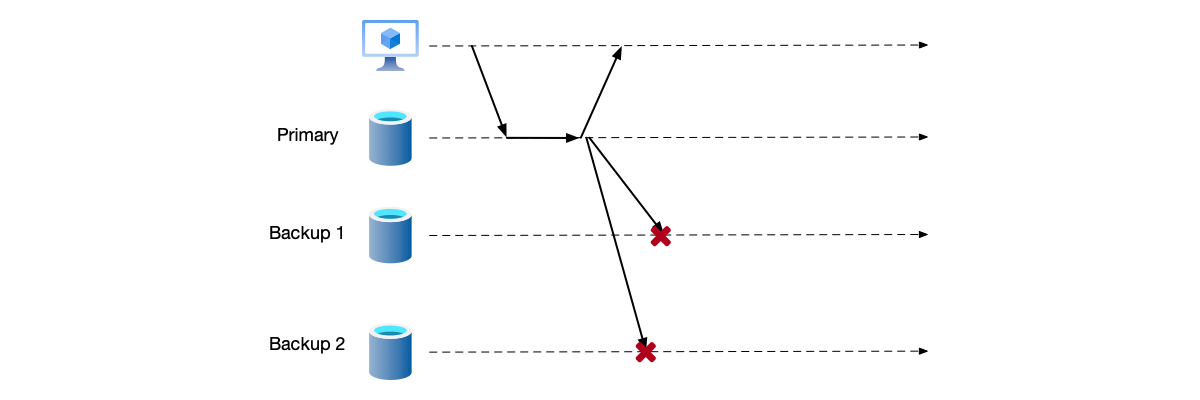
Primary-Backup Asynchronous Replication
The process of primary-backup asynchronous replication is as follows:
- The client’s write request is sent to the primary node.
- The primary node persists the write request data.
- The primary node responds to the client that the write is successful.
- The primary node replicates the data to the backup nodes.
The advantage is fast response speed. However, if an error occurs during the process of replicating data from the primary node to the backup nodes, then this data only has a backup on the primary node. Therefore, primary-backup asynchronous replication is not a reliable replication strategy.
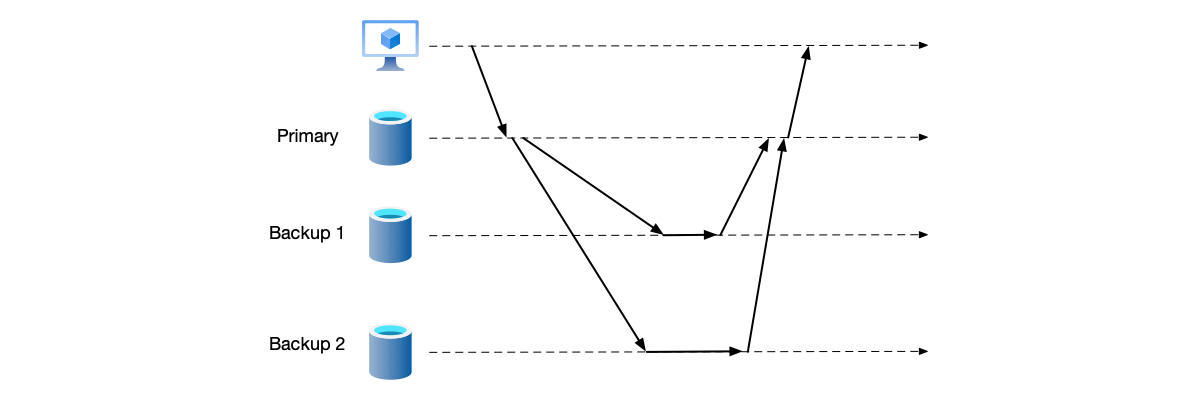
Primary-Backup Synchronous Replication
In primary-backup asynchronous replication, the system lacks reliability. So we change the strategy to synchronous replication, requiring the primary node to replicate data to all nodes before responding to the client:
- The client’s write request is sent to the primary node.
- The primary node persists the write request data.
- The primary node replicates the data to the backup nodes.
- After receiving replication success responses from all backup nodes, the primary node responds to the client that the write is successful.
Because data needs to be replicated to all backup nodes before responding to the client, the reliability is higher. However, it also faces another problem: if one node in the system does not respond, this write request cannot be completed, and system availability is reduced.
Primary-Backup Semi-synchronous Replication
Primary-backup semi-synchronous replication strikes a balance between the two schemes: before responding to the client that the write is successful, the primary node requires replication of data to enough (not necessarily all) backup nodes. As shown below, the system requires the primary node to only successfully replicate data to one backup node before responding to the client.
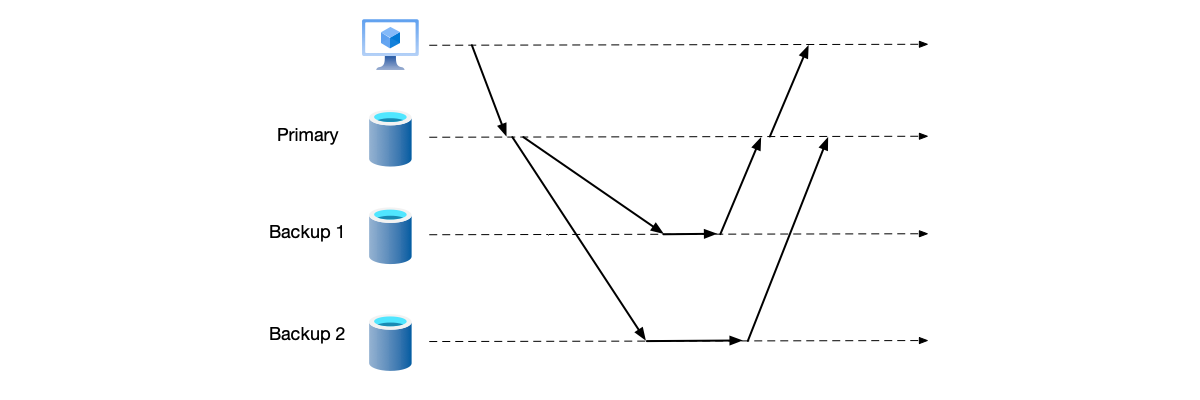
But semi-synchronous replication also has flaws: the data on any backup node may be incomplete. Consider the following scenario:
- The client writes data $a$ to the primary node. The primary node only replicates to backup node 1 before responding to the client.
- At the same time, the client writes data $b$ to the primary node. The primary node only replicates to backup node 2 before responding to the client.
- If the primary node crashes at this point, then neither backup node 1 nor backup node 2 has a complete copy of the system data.
Quorum Reads and Writes
To solve the data inconsistency problem in semi-synchronous replication, the strategy is changed to a quorum reads and writes strategy:
- Quorum write: Each write requires writing to more than half of the nodes before returning.
- Quorum read: Each read must read the data from more than half of the nodes.
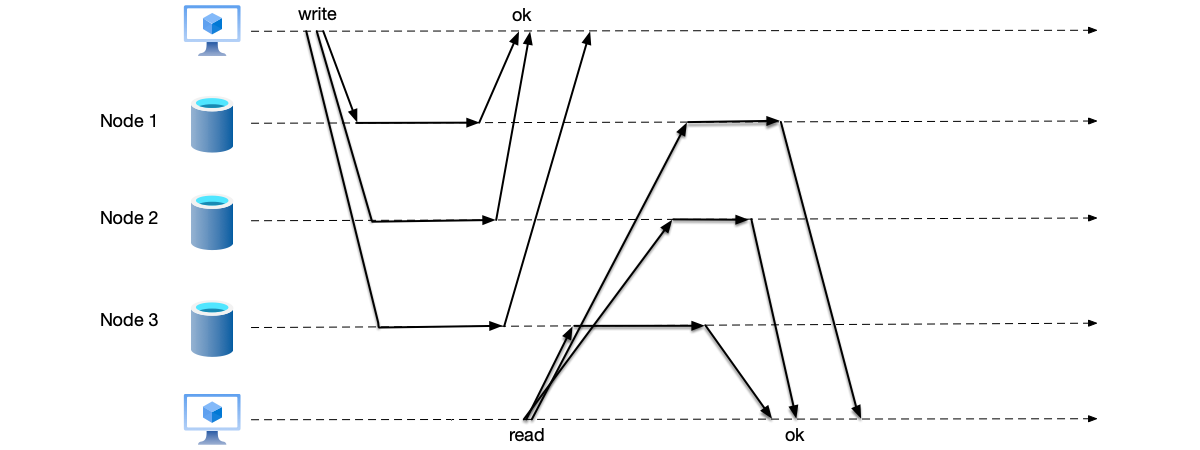
Because $W + R > N$, the node sets for quorum read and write operations must overlap. Therefore, during quorum read operations, the result of the previous quorum write can definitely be read.
Quorum Reads and Writes with Timestamps
However, the quorum reads and writes strategy also has other problems. Consider the following scenario:
- Nodes 1 and 2 both write data $x=a$.
- The next time this data is updated, data $x=b$ is written to nodes 2 and 3.
- That is, after these two data writes, the data on node 1 is $x=a$, while the data on nodes 2 and 3 is $x=b$.
If a client wants to read data, according to the quorum read strategy, it reads the data from nodes 1 and 3. There will be two different pieces of data. To solve the conflict, a monotonically increasing timestamp is added to the data when writing. During quorum read, the data with the larger timestamp is selected.
However, quorum reads and writes with timestamps still has problems. Using subscripts to indicate timestamps:
- At timestamp 1, nodes 1 and 2 both write data $x=a_1$.
- The next time, the timestamp is 2. The client writes data $x=b_2$ to nodes 2 and 3, but only node 3 wrote successfully.
- After these two writes, the data on nodes 1 and 2 is $x=a_1$, while the data on node 3 is $x=b_2$.
When the client reads data, the read result depends on which nodes are contacted:
- If nodes 1 and 2 are contacted, the data read is $x=a_1$.
- If node 1 (or node 2) and node 3 are contacted, the latest data is $x=b_2$.
It can be seen that in such scenarios, a system with quorum reads and writes with timestamps may also exhibit data inconsistency.
From Quorum Reads and Writes to Paxos #
We have successively learned about several different replication strategies and their flaws above. Now we come to the Paxos algorithm. It can be regarded as an upgrade based on quorum reads and writes with timestamps: by combining two loosely constrained quorum read/write phases with timestamps, a rigorous strongly consistent consensus algorithm is achieved.
To describe the idea of the Paxos algorithm, we implement a strongly consistent storage service that stores one variable $x$ and exposes three interfaces: get(), set(n), and incr(n).
The incr(n) operation needs to be decomposed into two steps:
- Through a quorum read, obtain the latest value $i$ of variable $x$.
- Through a quorum write, write the latest value $i + n$ of variable $x$.
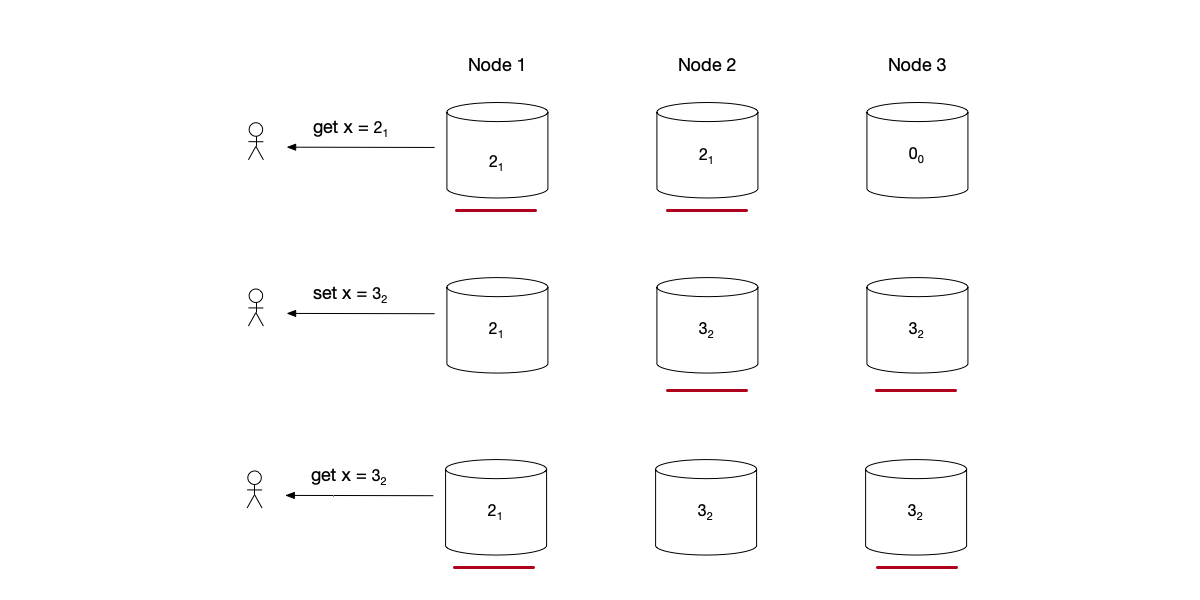
When multiple clients concurrently perform incr operations, a situation may arise where one client overwrites the write result of another client:
- Two clients simultaneously perform
incr(1)andincr(2)operations. - Client 1’s
incr(1)operation has client 2’s completeincr(2)operation between its read and write. Thus, when client 1 writes data, it overwrites the value written by client 2, resulting in two different values with the same timestamp.
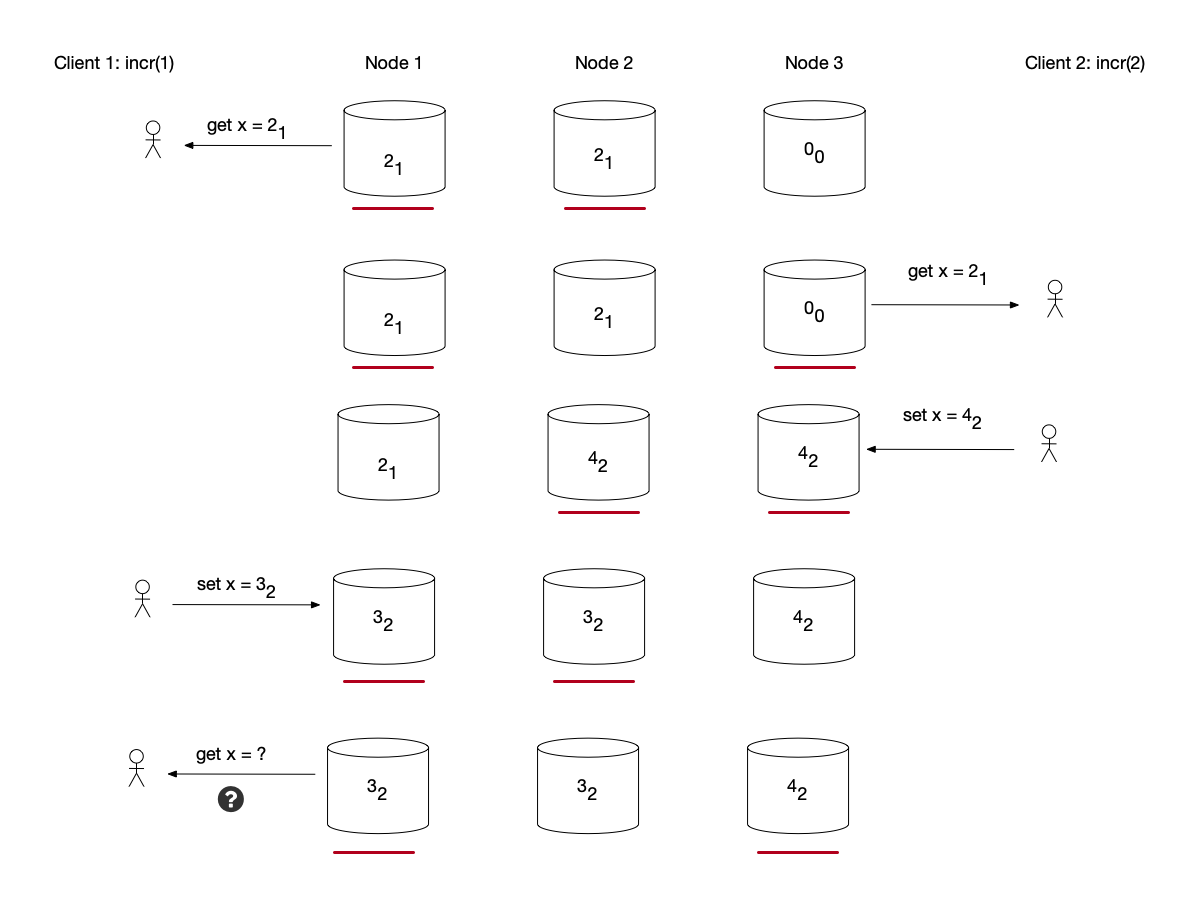
To solve this problem, we agree that a version can only have one determined value. Thus, the problem is transformed into another simpler problem: how to determine whether a value has been written. The most intuitive approach is: each time before the client writes data, perform a quorum read to determine whether another client is also writing data for this version.
But this solution still has concurrency problems: two clients simultaneously perform read operations before writing, and both receive feedback that no other process is currently writing.
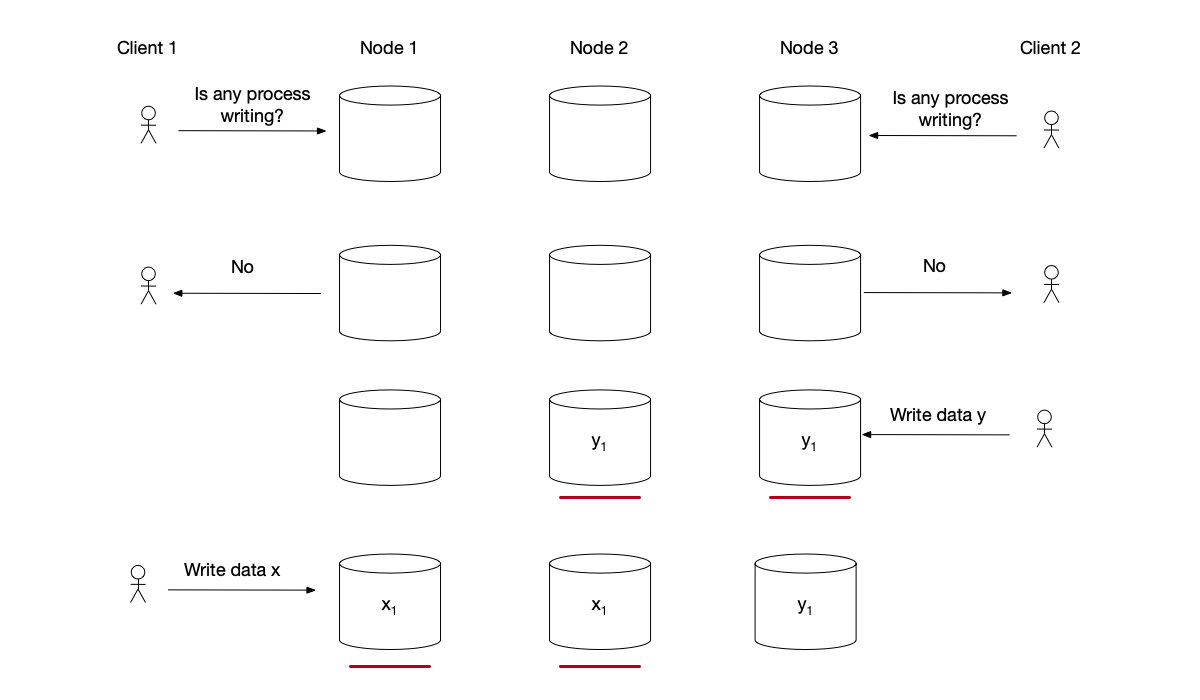
To solve the above problem, storage nodes also need to add a memory function:
- Each storage node must remember the last client that performed a read-before-write operation.
- Only the last client that completed the read-before-write operation is allowed to write data subsequently.
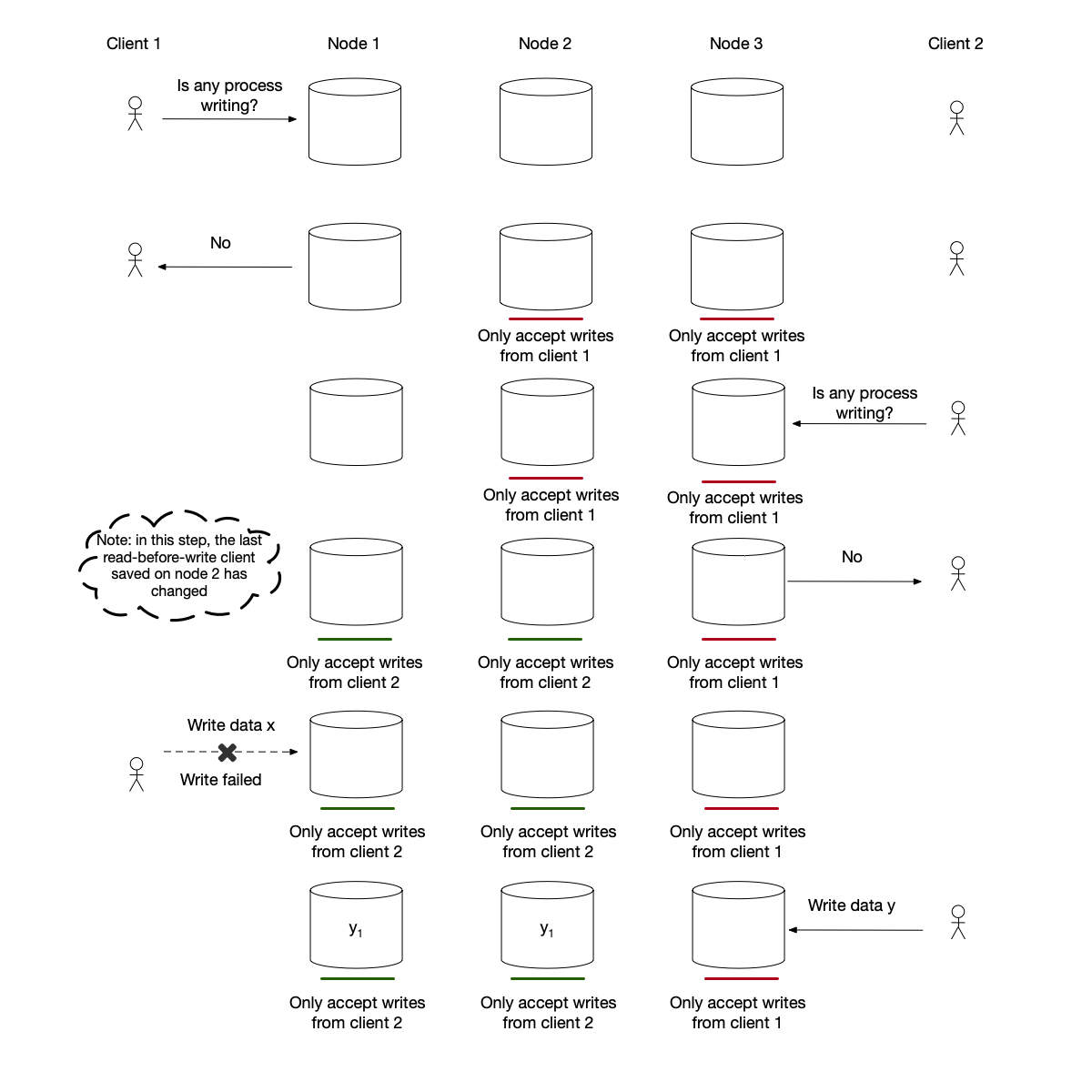
The Paxos algorithm uses two quorum reads and writes to achieve strong consistency:
- Client 1 first performs a read-before-write operation. This quorum request is received by nodes 2 and 3.
- Client 2 also performs a read-before-write operation. Its quorum request is received by nodes 1 and 2. Node 2 changes its record to client 2.
- So far, nodes 1 and 2 can only accept write operations from client 2, while only node 3 can accept write operations from client 1. Client 1 cannot complete the quorum write operation. Client 2 can eventually complete the quorum write operation.
The above is the core idea of the Paxos algorithm. Let us do a brief review:
- Initially, the system was implemented based on quorum reads and writes with timestamps.
- But this system has concurrent write conflict problems. To solve this, we agreed that a version can only write one determined value.
- Thus, the problem is transformed into how to determine whether a value has been written.
- Nodes are required to add a memory function: remember the last client that performed a read-before-write.
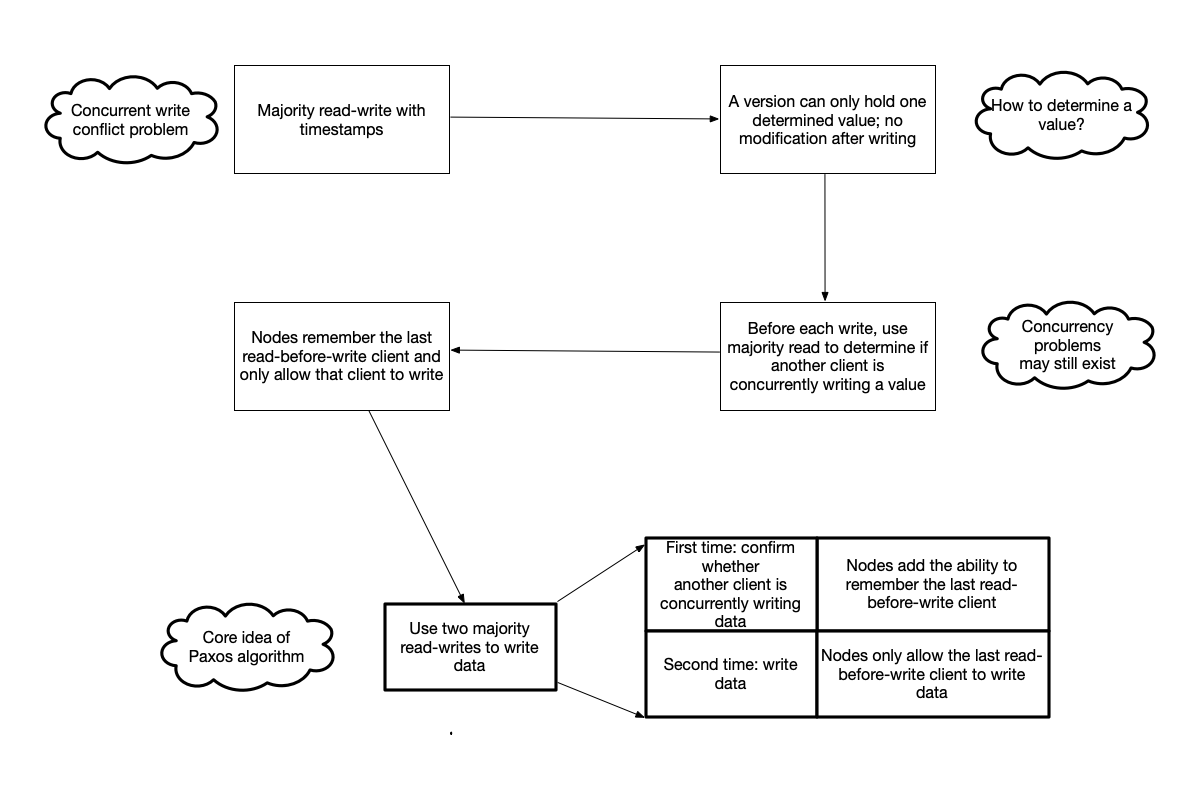
At this point, we can briefly summarize the core idea of the Paxos algorithm:
- Paxos is a strongly consistent storage system based on quorum reads and writes.
- It uses two rounds of quorum reads and writes (RPC) to determine a value: the first round to confirm whether another client is also concurrently writing data, and the second round to write data.
- Paxos’s way of resolving conflicts is to require that a value cannot be modified after it is “determined.”
Paxos Algorithm Description #
With the above intuitive explanation, we now begin the formal explanation of the complete process of the Paxos algorithm. In the Paxos algorithm, there are the following roles:
- Proposer: Can be understood as the client performing data reads and writes.
- Acceptor: Can be understood as the node storing data, i.e., the server.
- Round: Used to identify a Paxos algorithm flow. Rounds are represented by monotonically increasing numbers.
Note: Essentially, any set that satisfies the total order relationship can be used to represent rounds. Rounds must satisfy the monotonically increasing total order characteristic in order to distinguish the order of submissions.
Storage nodes need to record the following data:
last_round: The last Proposer that performed a read-before-write recorded by the Acceptor.value: The last written value.value_round: Paired with value, recording the round in which value was written.
Prepare Phase #
The task of the first phase is: to determine whether another client is also writing data at the same time.
- Proposer: The request carries its own round. If the Acceptor currently has no client request with a larger round, it will save this round.
- Acceptor: When receiving the Proposer’s phase 1 request, compare the round in the request with the local
last_round:- If
last_roundis greater than the requested round, the request is rejected. - Otherwise, update
last_roundwith the round of this request.
- If
- Acceptor will return the locally saved
last_round,value, andvalue_round.
Accept Phase #
After Proposer receives the response from Acceptor:
- If the
last_roundreturned in the responses from more than half of the Acceptors is not equal to the round of the Proposer’s phase 1 request, then the cluster has rejected the Proposer’s phase 1 request. - Otherwise, the Proposer can submit phase 2 data:
- If there is no non-empty
valuein the Acceptor’s response, the Proposer can continue to write the value it wants to write. - If a response contains a non-empty
value, the Proposer must use thevaluecorresponding to the largestvalue_roundamong all responses as the phase 2 write value (performing a data repair).
- If there is no non-empty
When Acceptor receives the Proposer’s phase 2 request:
- First, determine whether the requested round is consistent with the locally saved
last_round. If inconsistent, reject the request. - Save the value and round in the request to the local
valueandvalue_round.
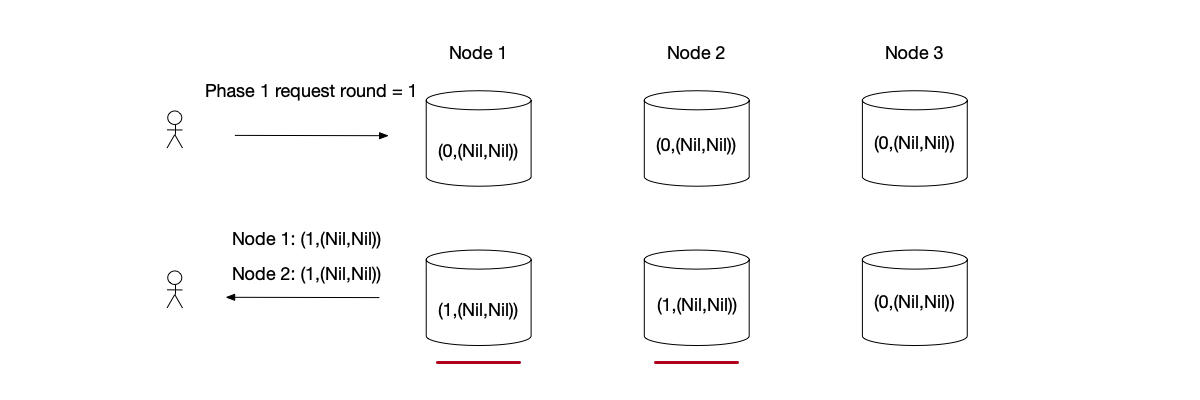
Paxos Algorithm Example without Conflict
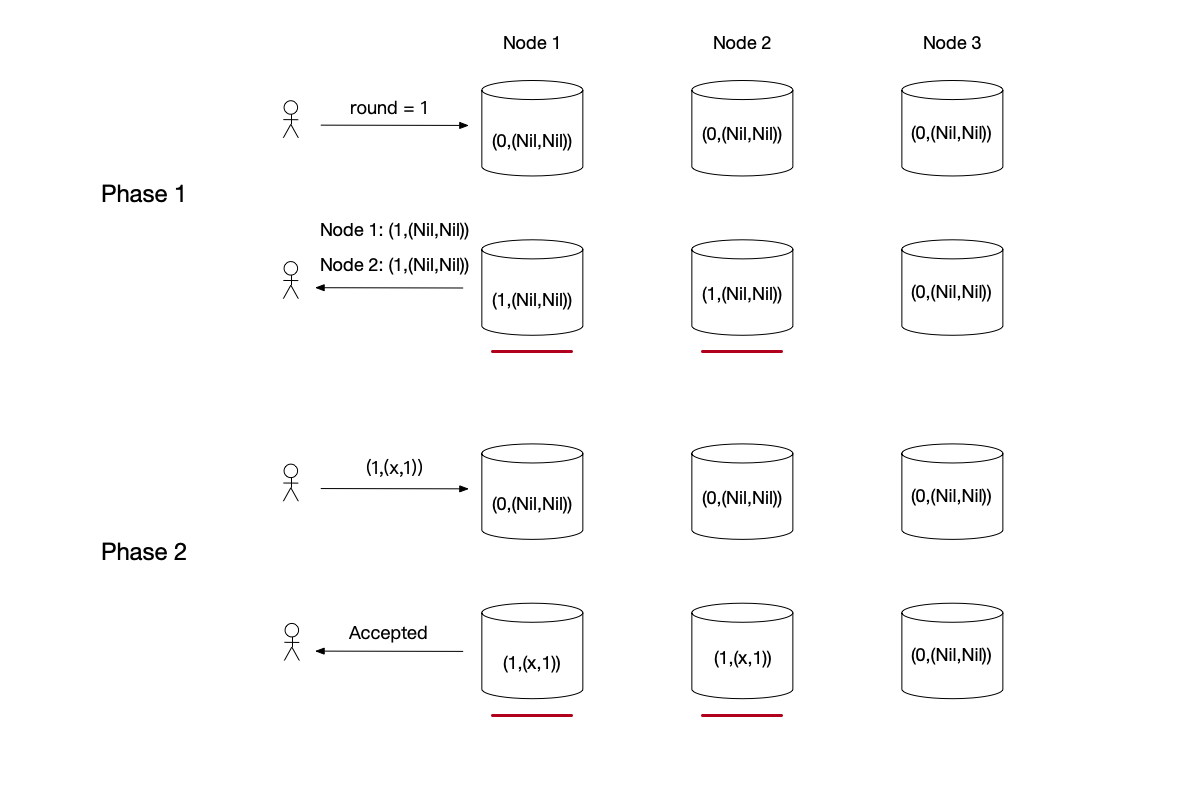
In the responses to the Proposer’s phase 1 request, the last_round of two nodes is the same as its own round, and no value has been written before. Therefore, the Proposer can choose to submit its own write value $x$ in phase 2.
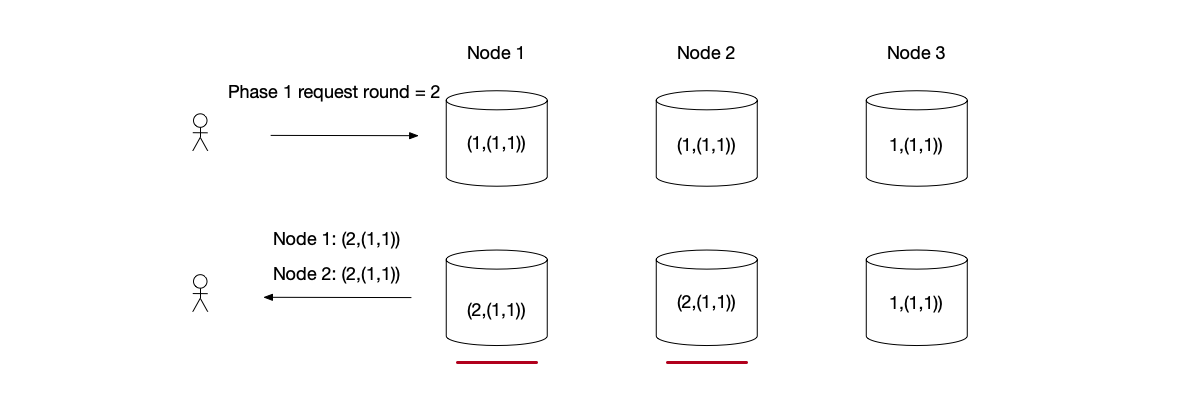
Paxos Algorithm Example Resolving Concurrent Conflict
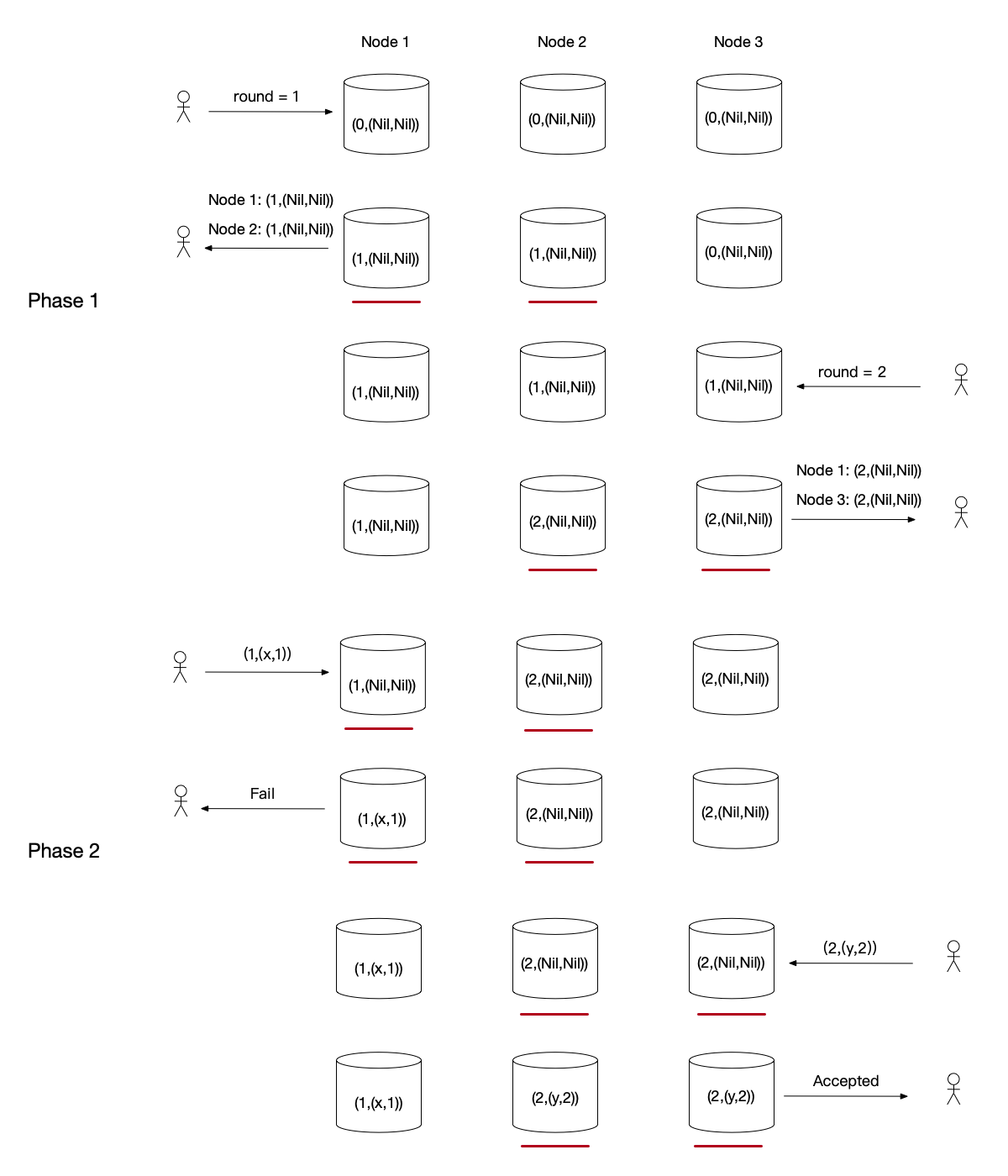
Two Proposers simultaneously write data:
- Phase 1: The Proposer on the left makes a phase 1 request with round 1. Nodes 1 and 2 modify their
last_roundto 1. Then the Proposer on the right makes a phase 1 request with round 2. Nodes 2 and 3 modify theirlast_roundto 2. - Phase 2: Both Proposers passed phase 1. The Proposer on the left submits value $x$ with round 1, but node 2’s
last_roundis 2, so node 2 rejects it. The left Proposer fails. The Proposer on the right submits value $y$ with round 2. Nodes 2 and 3 agree, and the data is modified to (2, ($y$, 2)).
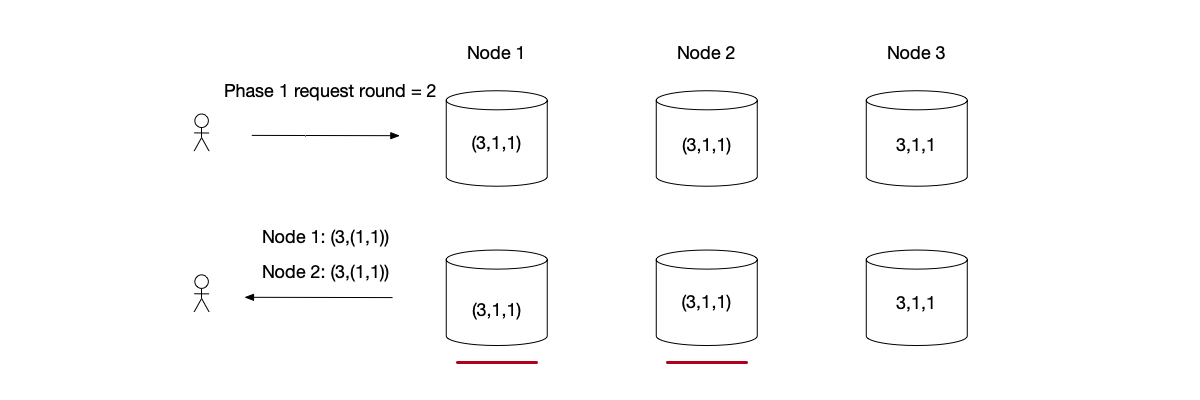
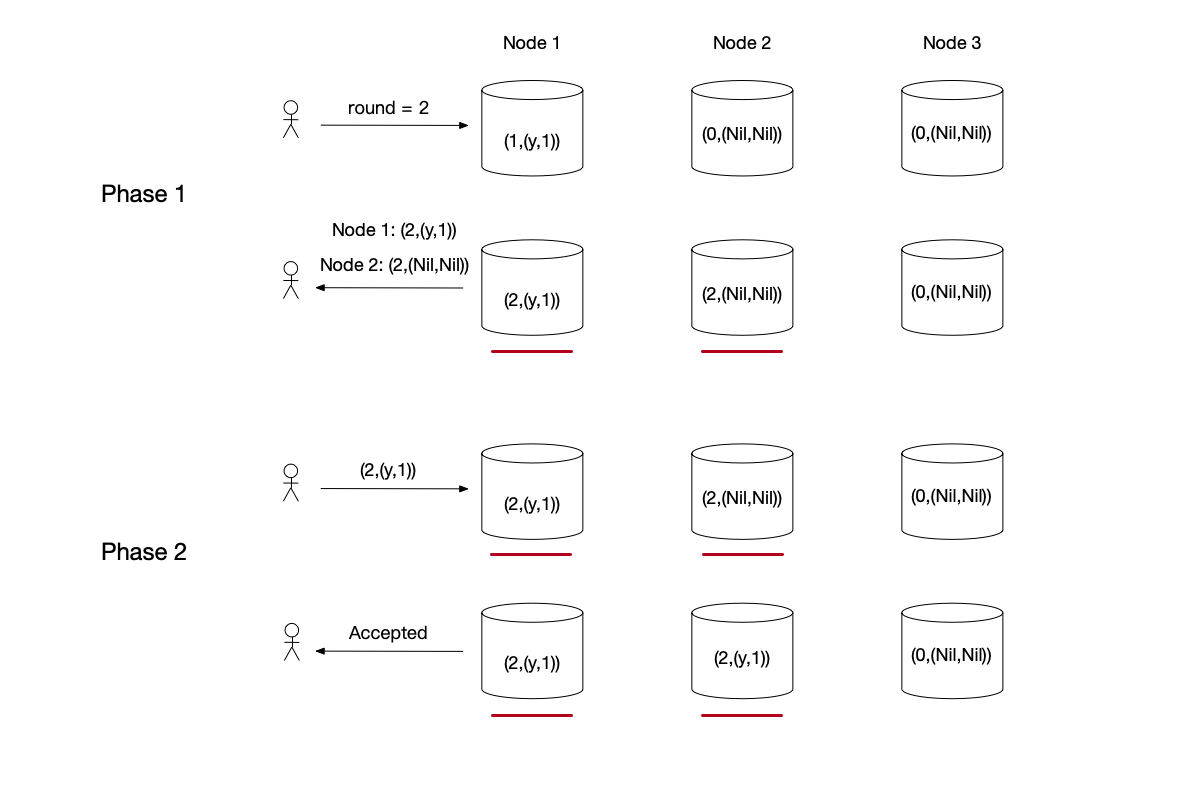
Paxos Algorithm Example Repairing Data
- Phase 1: The Proposer submits a phase 1 request with round 2. Node 1’s data is (1, ($y$, 1)), so it modifies
last_roundto 2 and returns data (2, ($y$, 1)). Node 2 returns data (2, (Nil, Nil)). - Phase 2: The Proposer passed phase 1. However, because the data returned by node 1 is ($y$, 1), the Proposer needs to perform data repair with this value. Finally, the data on nodes 1 and 2 is modified to (2, ($y$, 1)).
Multi-Paxos Algorithm #
In the previous section, we completely derived the Paxos algorithm (usually called Basic Paxos). Although Basic Paxos theoretically perfectly solves the problem of reaching consensus on a single value in an unreliable network, it faces serious performance bottlenecks in actual engineering applications.
A typical distributed storage system needs to reach consensus on a series of continuous operations (log stream), not just a single value. If a complete Basic Paxos instance is simply run for every log entry, the following problems will arise:
- Low performance: Reaching a consensus requires two rounds of RPC (Prepare and Accept).
- Livelock risk: If multiple Proposers simultaneously and frequently submit requests, they can easily fall into an infinite loop of competing for rounds.
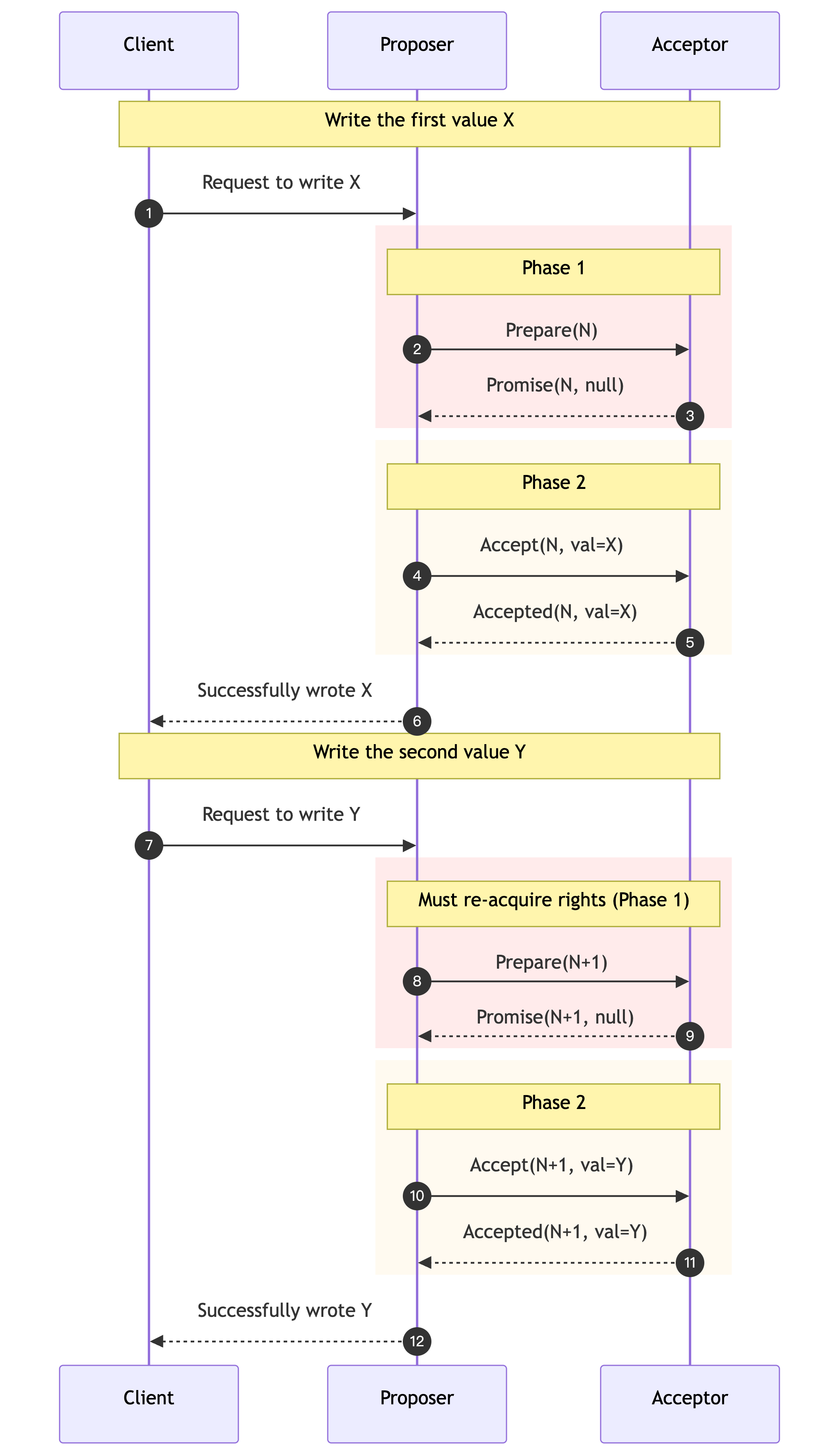
To solve the above problems, Lamport proposed Multi-Paxos. Its core optimization is: one Prepare, multiple Accepts.
If a Proposer has just passed the Prepare phase and successfully submitted a value, this means that it has obtained the current highest round number. Then, in subsequent submissions, this Proposer can completely reuse this already obtained “privilege” without having to go through the Prepare phase every time.
The optimized process is:
- Phase 1 (Prepare): Proposer election. Once it obtains the promise of a majority of Acceptors, the node becomes the de facto Leader.
- Phase 2 (Accept): Continuous submission. The Leader directly skips the Prepare phase and initiates Accept requests.
Only when the Leader node fails, or network partitioning causes new Proposer competition, will the Prepare phase be triggered again.
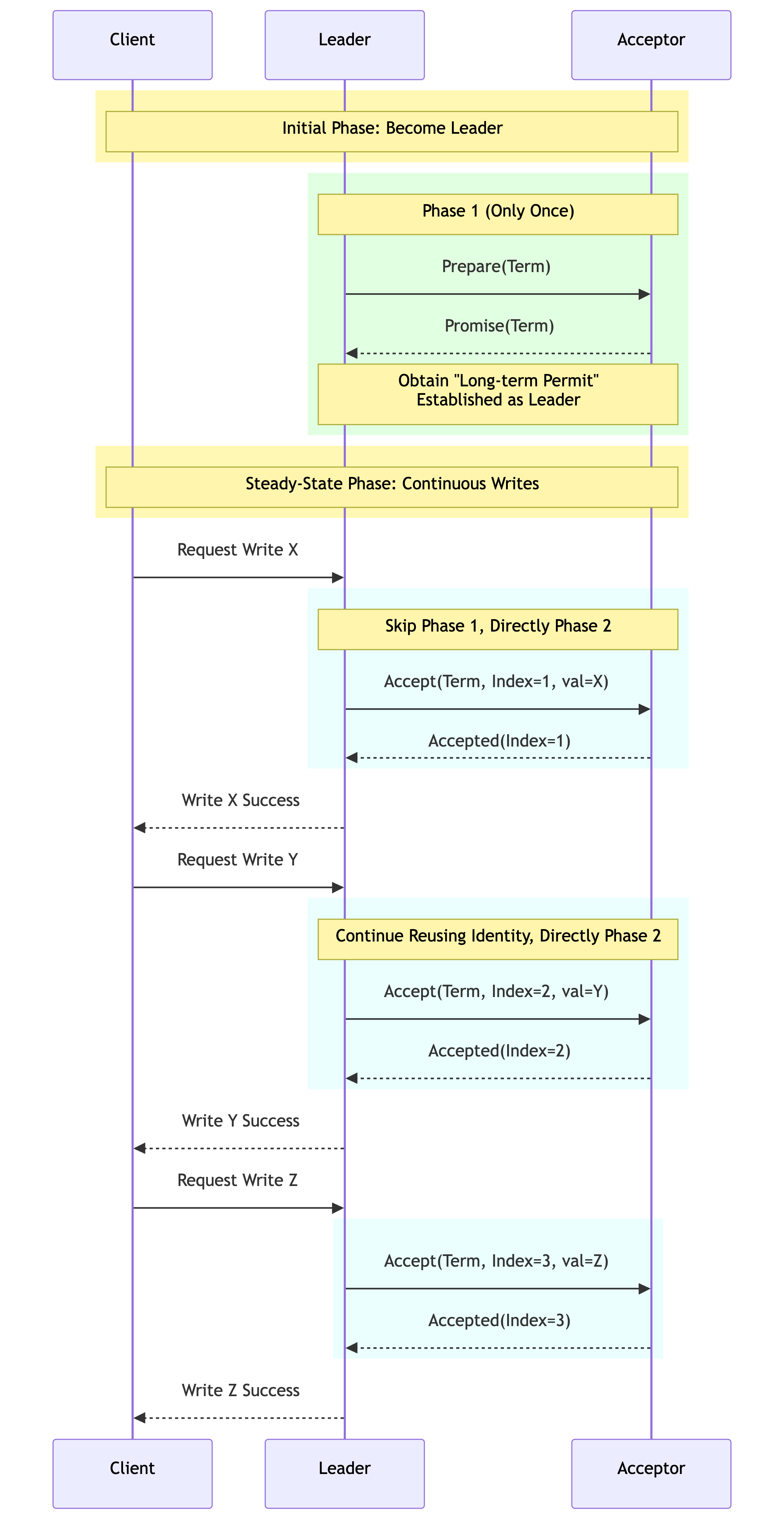
Unfortunately, in Lamport’s original description of Multi-Paxos, many details were missing. Readers interested in the Multi-Paxos algorithm can refer to the papers [8] and [10]. Leslie Lamport did not specify specific Leader election details, log recovery processes, or membership change mechanisms in the paper. This led to even top technology companies like Google paying a huge engineering cost when implementing Multi-Paxos for Chubby.
We can summarize it this way: Multi-Paxos provides an idea of optimizing performance through a “strong Leader,” but leaves many complex implementation details unspecified.
It is precisely to fill these gaps that the Raft algorithm emerged. Raft can be regarded as a strongly restricted version or specific implementation of Multi-Paxos.
Note: Paxos’s “version number” (i.e., the Proposal ID) only needs to satisfy the total order property. This core idea carries over into Raft: Raft’s “version number” takes the form of a
(Term, Index)tuple, which equally satisfies the total order property.
Raft Algorithm #
The Paxos algorithm provided a theoretical foundation for consensus algorithms in distributed systems. However, the algorithm explanation in the Paxos paper only answered the “why” question. A production system needs to consider more problems beyond the algorithm:
- How to elect a Leader node, and how to avoid having more than one Leader node.
- How to handle cluster membership changes.
- How to interact with clients to achieve linearizability.
- How to replicate logs, and how to quickly synchronize current cluster data when new nodes are added.
These “how” problems had not been adequately addressed until the Raft algorithm was proposed. For example, Google engineers complained in [11]:
Although a page of pseudocode can describe the Paxos algorithm, our complete implementation contains thousands of lines of C++ code. Transforming this algorithm into a practical, production-grade usable system requires implementing numerous features and optimizations—some of which have been published in literature, and some of which have not.
The paper [11] also proposed:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system $\cdots$ the final system will be based on an unproven protocol.
This situation did not change until 2014, when Diego Ongaro and John Ousterhout published the paper In Search of an Understandable Consensus Algorithm [12]. After the Raft paper was published, many strongly consistent data services based on the Raft algorithm appeared, such as etcd [14], TiKV [15], Consul [16], etc. Readers can see Raft algorithm implementations in various languages on the Raft official website [17], including the OpenRaft [18] project that the author participated in.
Note: Diego Ongaro detailed the origin of the algorithm name “Raft” in the Raft community’s Google Groups [19]. They coined a word: R{eliable|eplicated|edundant} And Fault Tolerant. Literally, a “raft” is a flat structure made of logs used for floating. Since a raft is constructed from logs, it aptly reflects the Raft algorithm’s idea of using log replication to implement consensus. Finally, using a “Raft” to escape Paxos island is a clever pun.
Raft achieves its goals by decomposing the consensus problem into several easily understandable sub-problems:
- Leader Election: When the cluster starts up or the leader fails, a new leader needs to be elected.
- Log Replication: The leader receives client requests and replicates them to other nodes in the form of logs.
- Safety: The Raft algorithm must satisfy safety requirements, such as there cannot be multiple Leader nodes at the same time.
Basic Concepts #
Three States
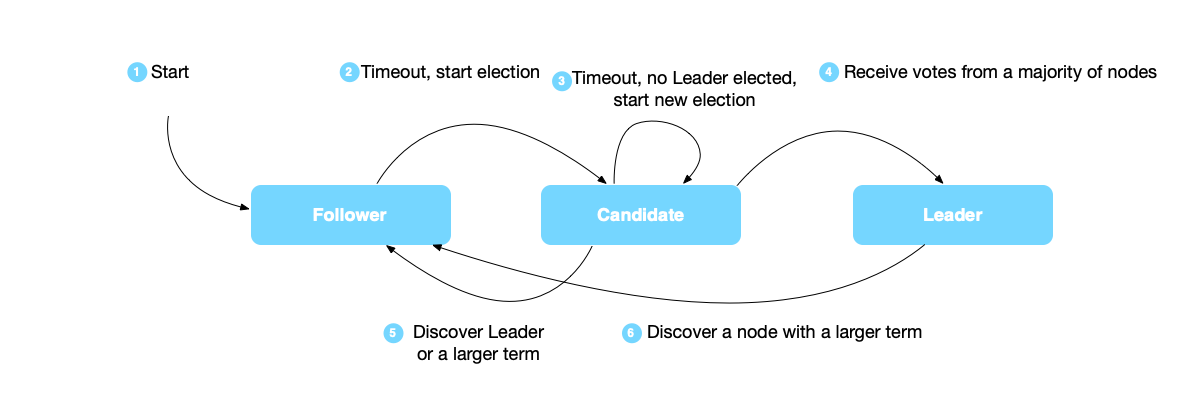
In the Raft algorithm, a node can only be in one of the following three states at any time:
- Leader: Responsible for receiving client requests, managing log replication, and communicating with all other nodes. There is only one leader within a term.
- Follower: Passively responds to the leader’s requests, and switches to the candidate state to participate in elections when the leader is unavailable.
- Candidate: When initiating a leader election, the node temporarily becomes a candidate, trying to win votes from other nodes to become the new leader.
The transition mechanism between these states:
- After node startup, it first enters the Follower state.
- If a Follower node does not receive any message from the Leader before the election timeout, it switches to the Candidate state.
- After a Candidate initiates a new round of election, if no new Leader is elected before the election timeout, it will initiate the next round of election again.
- If a Candidate obtains consent from more than half of the nodes, it becomes the Leader of this round.
- If another node wins the election or a node with a larger term number is discovered, the Candidate will switch to the Follower state.
- If a Leader node discovers another node with a larger term, it will switch to the Follower state.
Terms
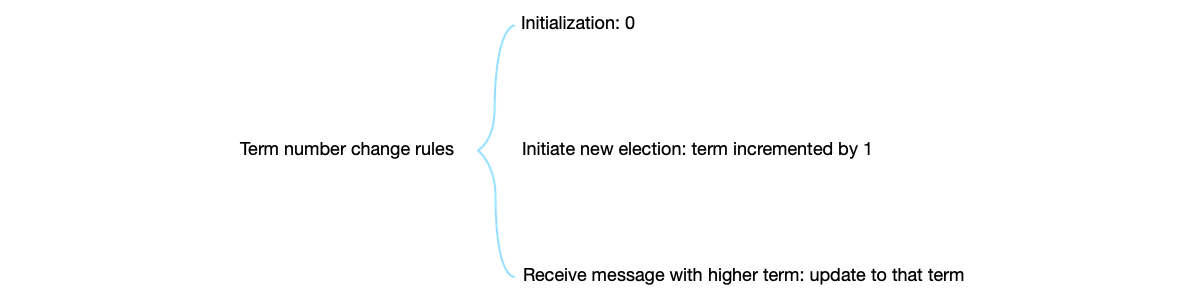
In the Raft algorithm, term is a core concept that plays the role of a logical clock, used to coordinate the behavior of nodes:
- Terms use monotonically increasing natural numbers. Each election corresponds to a term.
- When a Follower converts to a Candidate, it increments the term number.
- Current Term must be persistently saved.
- When receiving a message with a higher term, the Current Term will be modified. If in the Leader state, it will switch to the Follower state.
- The leader periodically broadcasts the current term number through heartbeat messages.
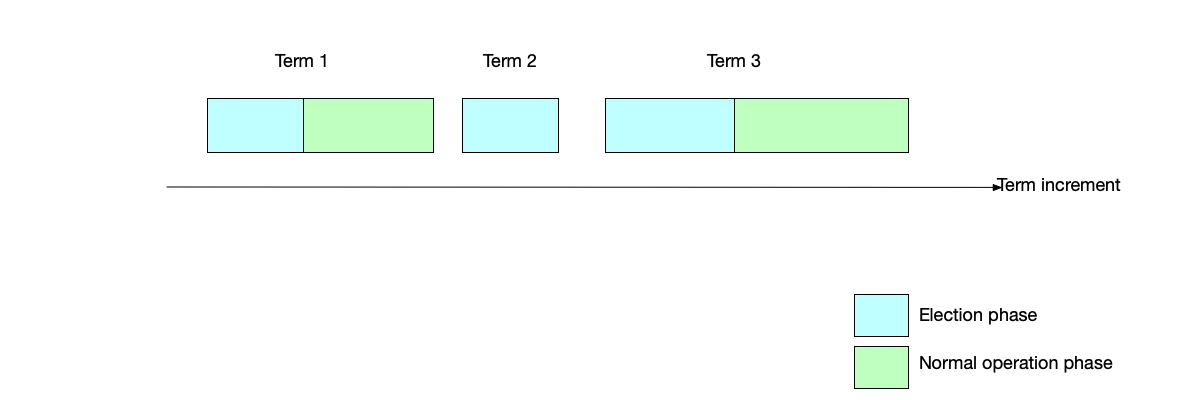
Each term is divided into an election phase and a normal operation phase. However, there may also be cases where some terms only have an election phase.
Leader Election #
In the Raft algorithm, a heartbeat mechanism is used to trigger the election process. Each node has a timer called “election timeout.” The detailed process of electing a Leader:
- If a Follower node does not receive any message from the Leader before the election timeout, it will switch to the Candidate state.
- The Candidate node will increment the current term number.
- The Candidate node broadcasts RequestVote messages to all nodes.
- If before the election timeout, the node receives votes from a majority of nodes, it becomes the Leader.
- If before the election timeout, the node receives a Leader message from another node, it switches to the Follower state.
- If neither of the above two situations is satisfied, the node increments the term number to initiate the next round of election.
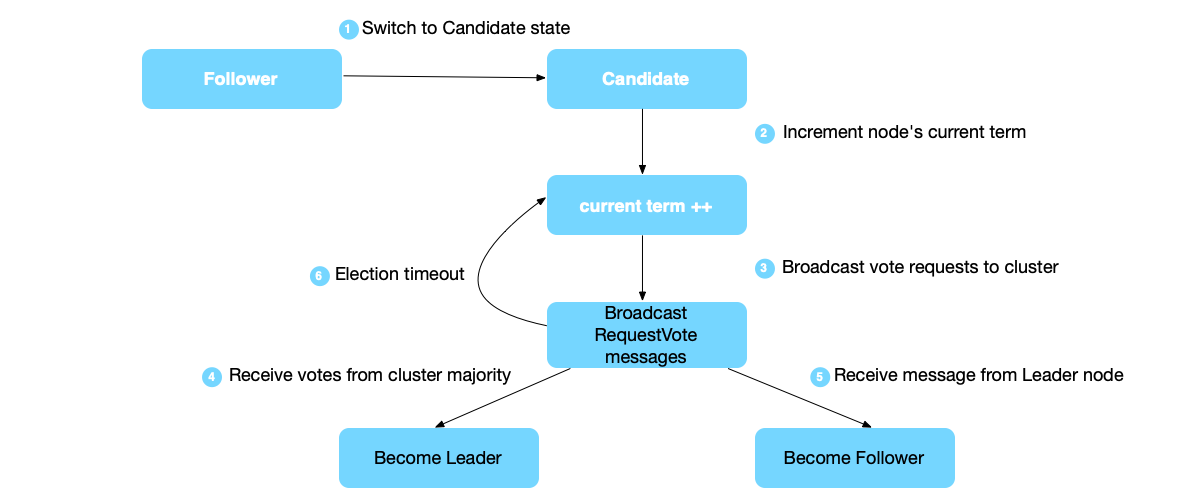
Safety: Within any term, only one Leader can be elected. Each node can only vote for one node in a round, following the “first come, first served” principle. The election process requires the consent of a majority.
Liveness: To solve the livelock problem where no Leader is elected, the Raft algorithm randomizes the election timeout. Each node randomly selects a value in the [T, 2T] interval.
Log Replication #
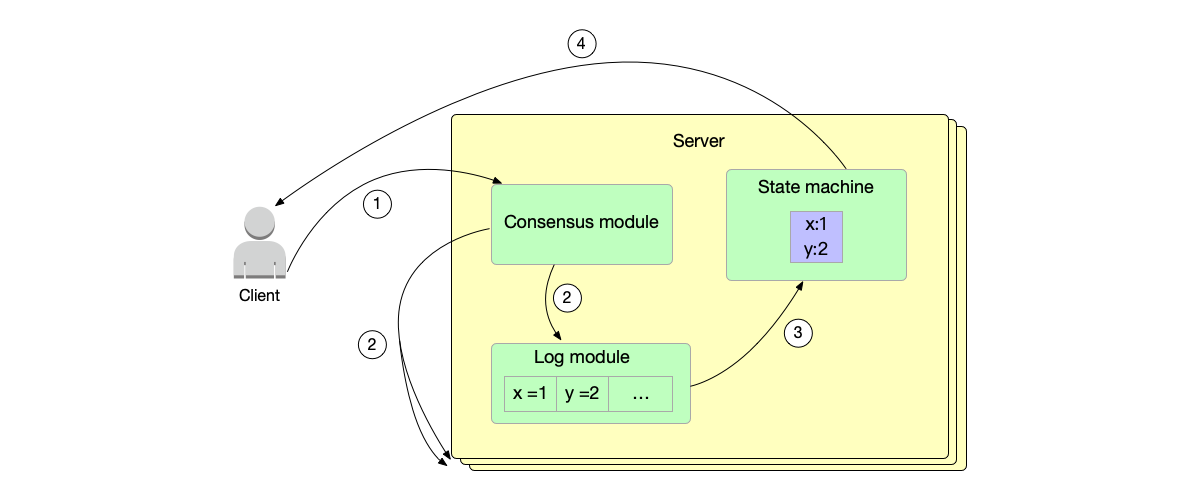
The log replication process:
- The client initiates a write data request to the Leader node.
- The consensus algorithm module combines the data with the current term number and the incremented index to form a change log and saves it locally. It synchronizes this log to other nodes.
- When the Leader node receives responses from a majority of nodes, it considers that the log can be committed, and inputs the log into the state machine module.
- After the state machine module applies the log, it responds to the client that the write data is successful.
- Commit: A log can only be considered successfully committed after it has been successfully synchronized on a majority of nodes.
- Apply: Only successfully committed logs can be applied to the state machine.
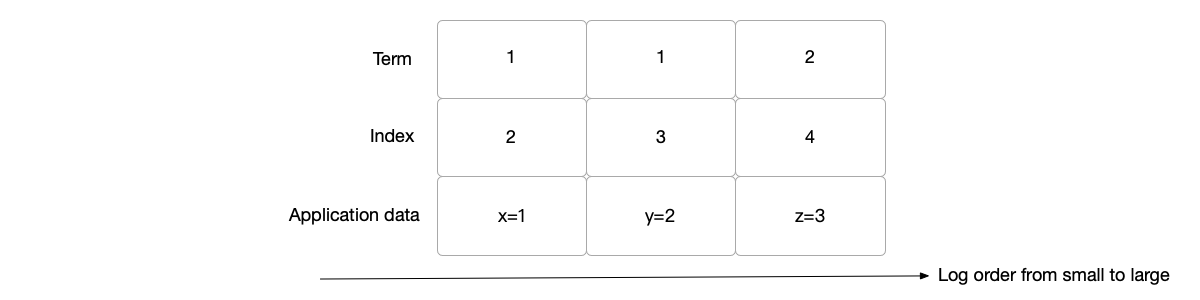
A log entry in Raft contains: the term in which the log is located, the index of the log, and the application-layer data. The term number and index form a binary tuple that satisfies a total order. The log order is compared by:
- First, compare the term numbers. The log with the larger term number has a larger order.
- If the term numbers are the same, the log with the larger index has a larger order.
Safety of Log Replication
Log replication needs to satisfy the “log matching property”:
- If the (term number, index) binary tuples of two logs are consistent, the data stored in the logs is also the same.
- If two logs have the same (term number, index), then all the logs before these two logs are the same.
The Leader node maintains an index called nextIndex for each Follower node. When the Leader has just been elected, it will default to replicating from the latest log. If replication receives a rejection from the Follower node, it will adjust accordingly.
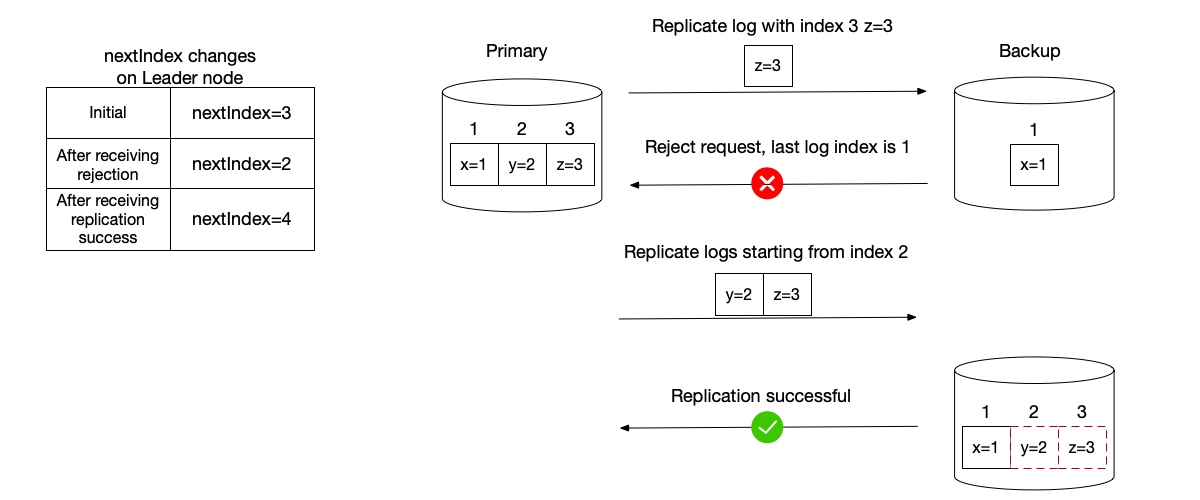
The possible situations where Follower node log data is inconsistent:
- Missing logs: The Follower node needs to catch up.
- Has uncommitted logs: These need to be overwritten by committed logs.
- A combination of both.
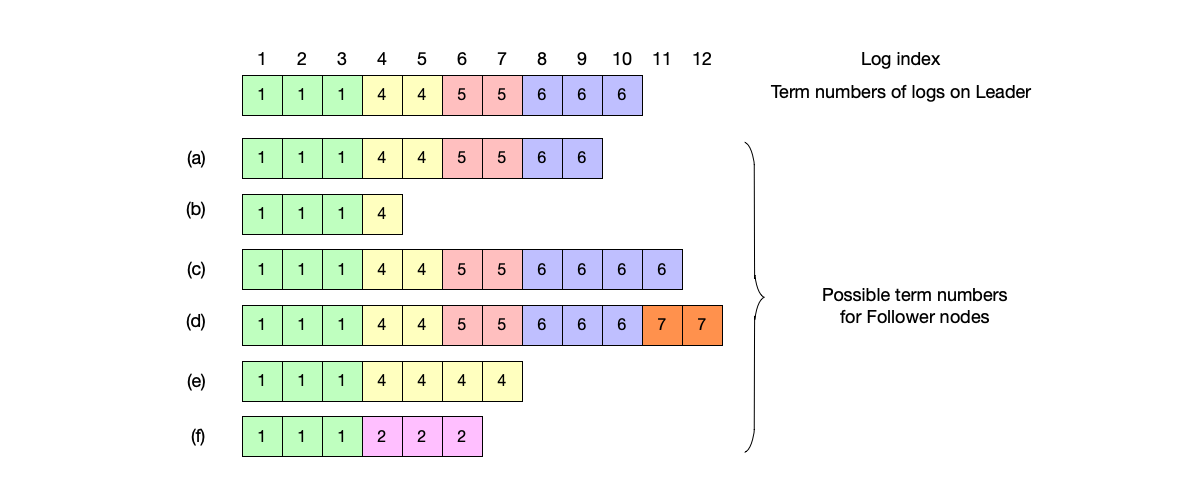
Safety #
Leader Election Restriction
Votes can only be cast for Candidate nodes whose logs are not older than this node’s logs. This avoids the situation where committed logs are overwritten by the new term Leader.
Replicating Uncommitted Logs from Old Terms
The Raft algorithm stipulates: after the Leader node is elected, the first log that can be replicated must be a log of this term. According to the log matching property, if a log of this term can be successfully committed, then the old term logs before it can also be committed.
Note: In specific implementations, after a node is newly elected as the Leader node, it will first replicate an empty log of this term (a “no-op log”).
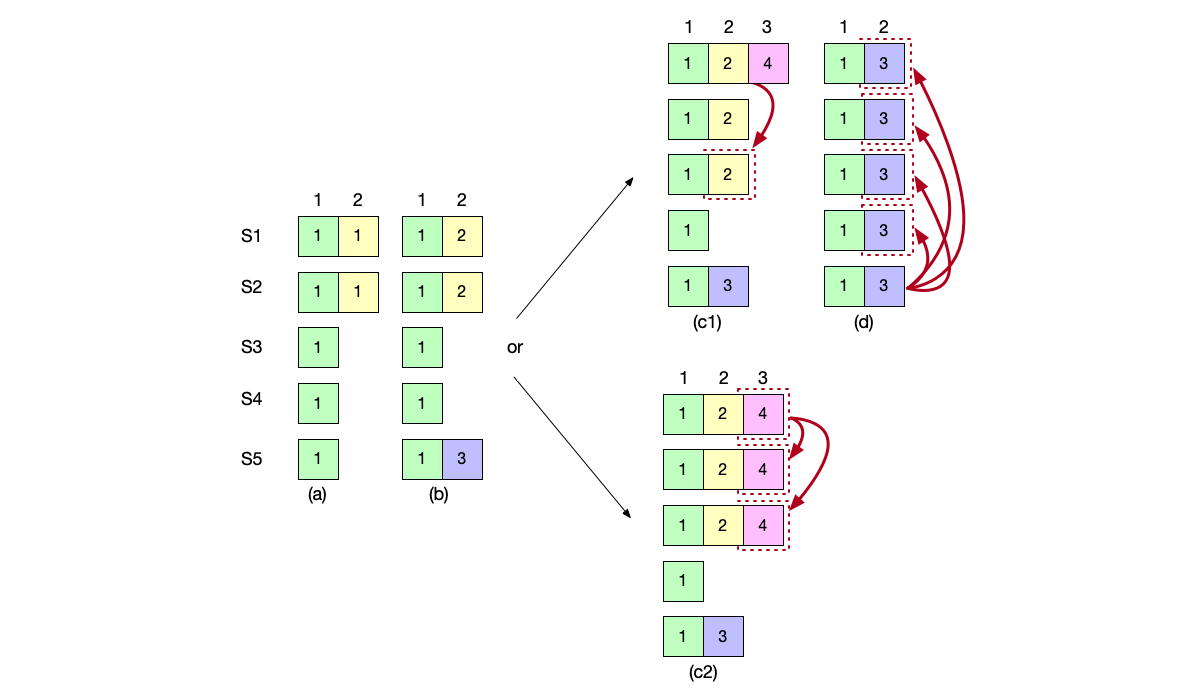
Cluster Membership Changes #
Safety #
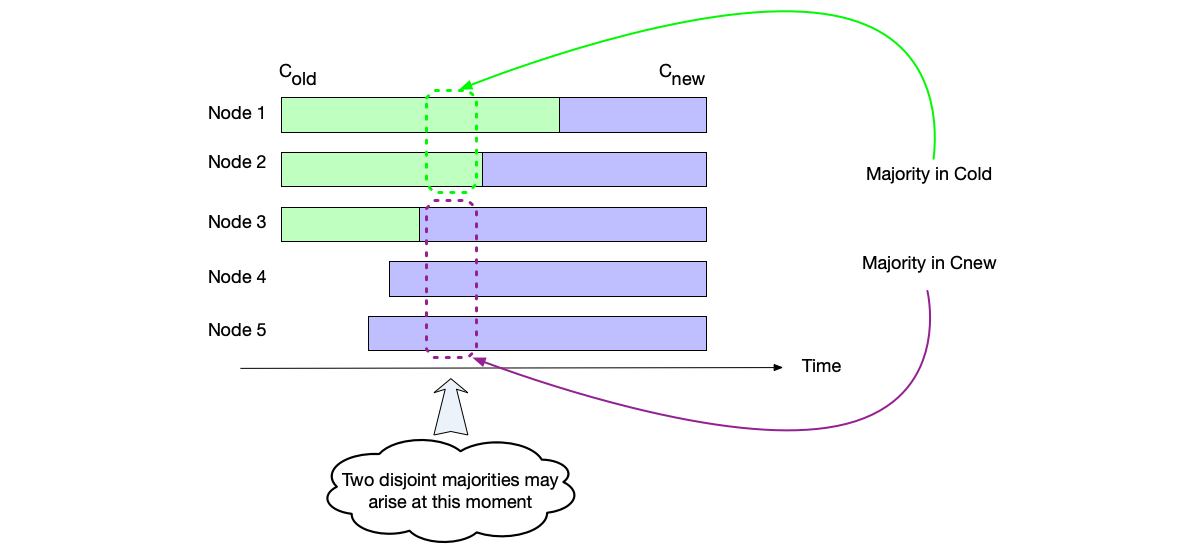
The safety that needs to be guaranteed during the membership change process is: at any moment, there cannot be more than one Leader node in the cluster.
To avoid the split-brain phenomenon, the change process must avoid the scenario of two disjoint majorities.
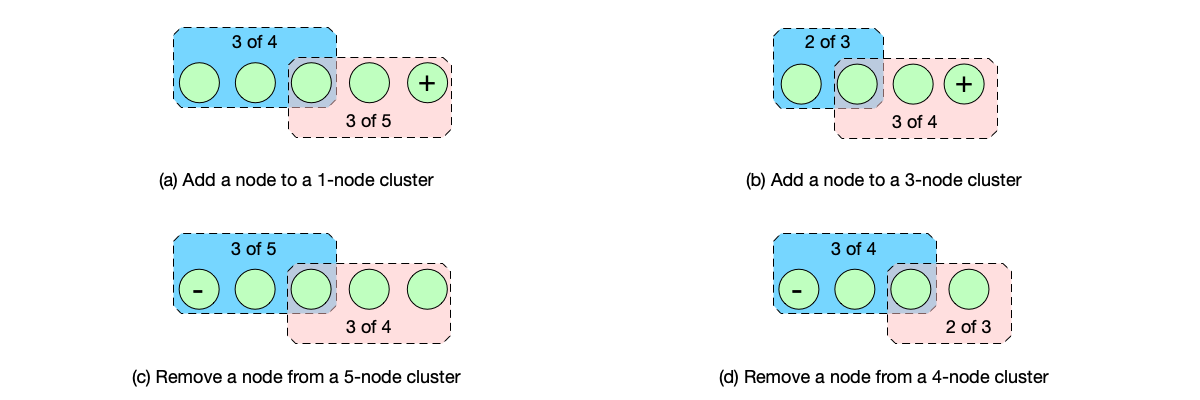
Single-Step Membership Change #
In the single-step membership change algorithm, only one node is allowed to be changed (added or removed) each time. In each case, there will not be two disjoint majority sets.
Correctness Problem: Single-step membership change may have correctness problems in some cases, causing committed logs to be overwritten [20]. The fix is: the new Leader must commit a log in the current term before being allowed to synchronize membership change logs.
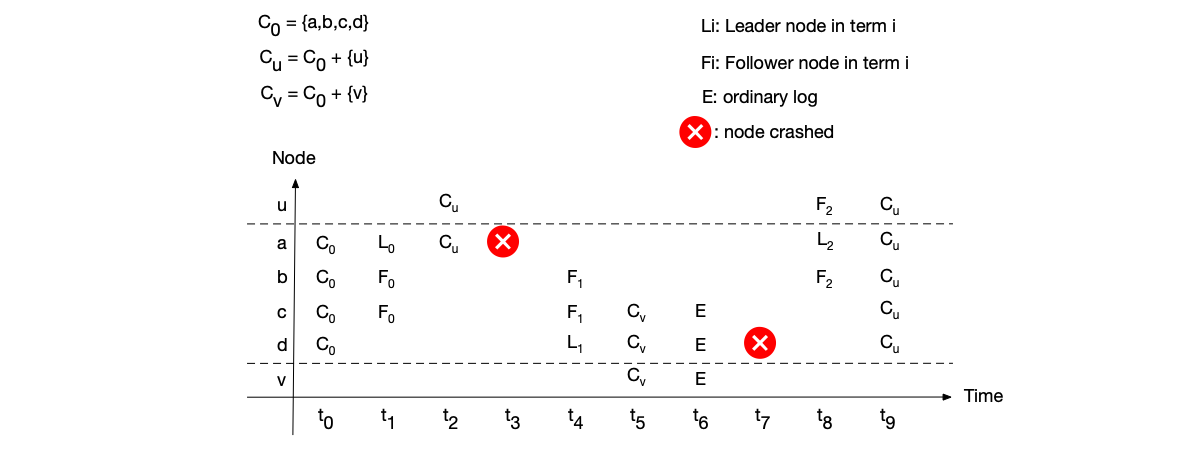
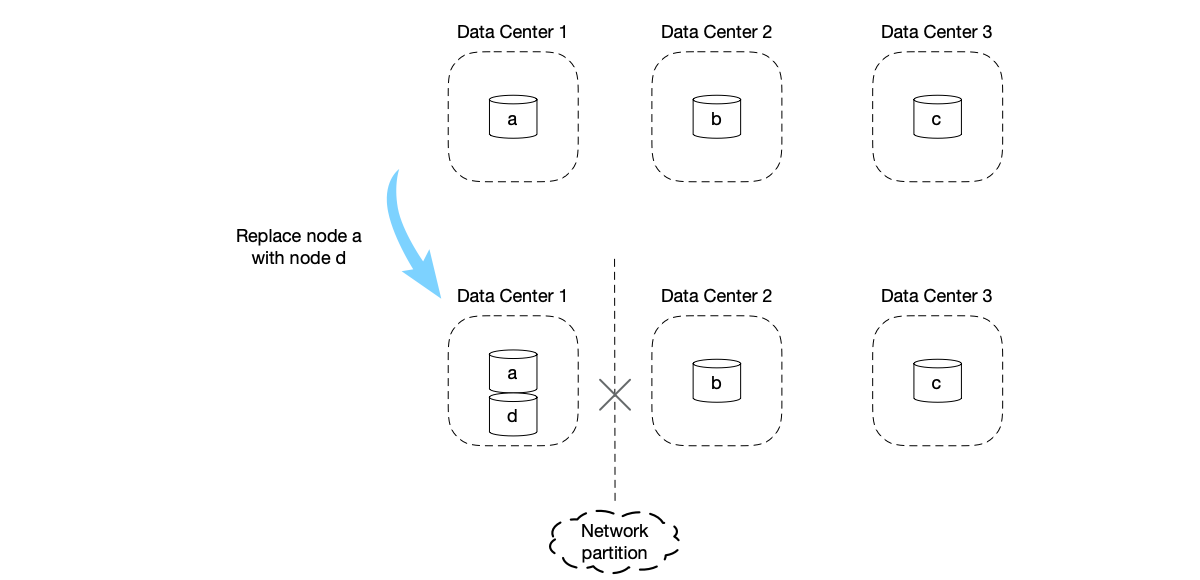
Availability Problem: Single-step changes may cause the cluster to be unavailable when network partitioning exists.
Joint Consensus #
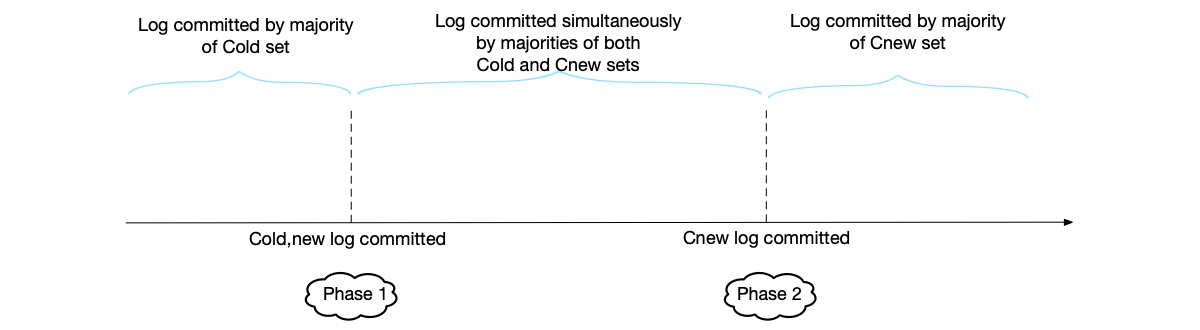
Joint consensus introduces a transitional phase $C_{old,new}$ to ensure that majorities of both the old and new configurations agree to the change.
- Phase 1: The leader generates a joint log entry ($C_{old,new}$) and replicates it. Logs must simultaneously satisfy the majority confirmation of both $C_{old}$ and $C_{new}$ to be committed.
- Phase 2: The leader generates a log entry containing only $C_{new}$ and replicates it. This log only needs the majority confirmation of $C_{new}$.
Liveness Problems During Network Partitioning #
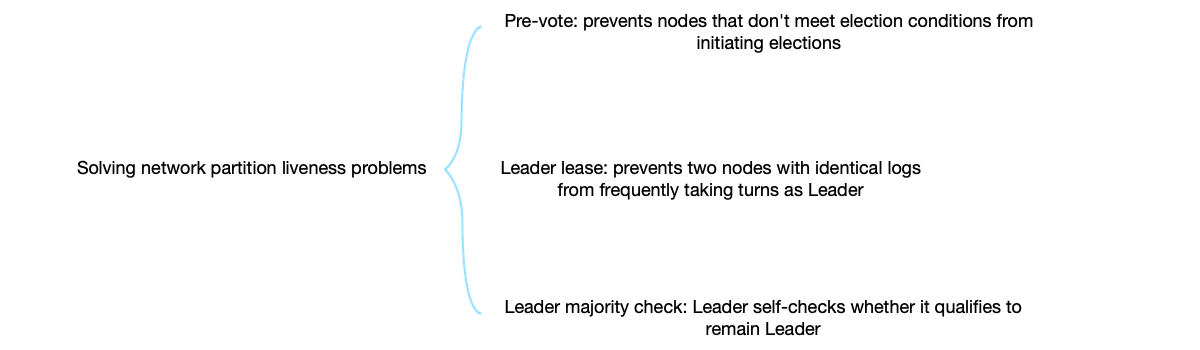
In some extreme cases, due to network partitioning, Raft frequently conducts leader elections, resulting in liveness problems affecting system availability [21, 22].
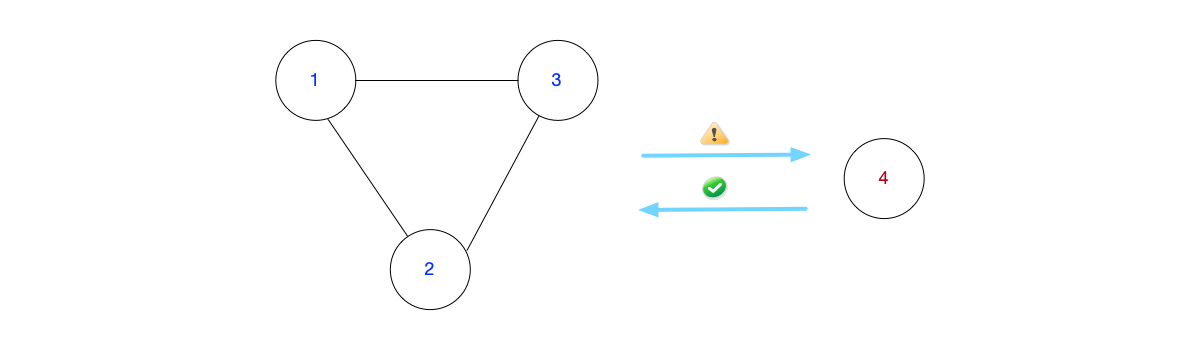
Three solutions:
- Pre-Vote: A node first enters the PreCandidate state to initiate a “pre-election” without incrementing the term number.
- Leader Lease: If a Follower node receives a message from the current Leader node within one election timeout period, it will not vote for other nodes.
- CheckQuorum [23]: The Leader node periodically checks if it can reach a majority of nodes. If not, it actively steps down.
Log Compaction #
Over time, a lot of redundant data will accumulate in the operation log.

The Raft algorithm introduces snapshot to solve this:
- The index and term number of the last log in the snapshot.
- The state machine data in the compressed snapshot.
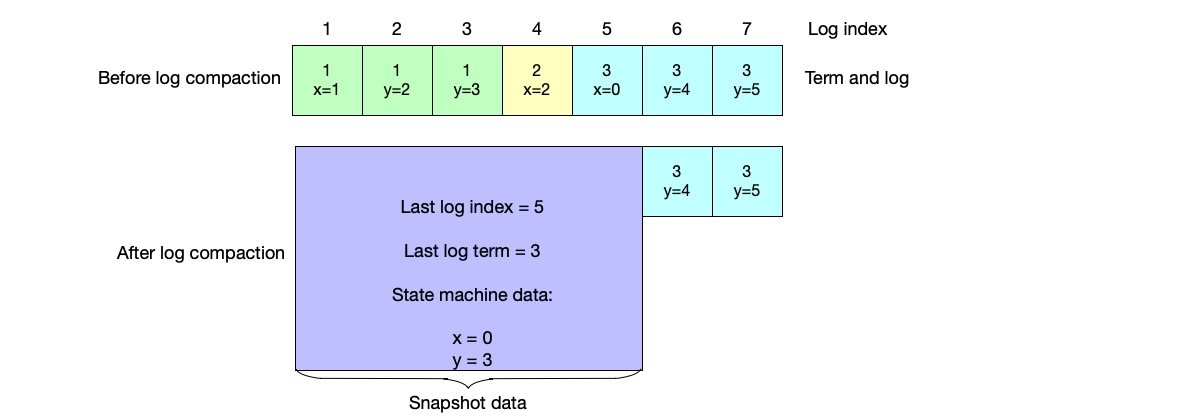
After adopting snapshot compression, system startup is divided into two steps:
- If snapshot data exists, the snapshot data is read first to obtain the current state machine data.
- Next, the remaining logs are read, and the current state machine data is synchronously updated.
Implementing Linearizable Reads #
The difficulty is: the Leader node needs a mechanism to ensure that it is still the Leader node, so that it can safely return the result of the read request.
The Raft algorithm optimizes linearizable reads by introducing a variable called readIndex:
- Leader confirms identity: commit a no-op log in the new term.
- Obtain read index: record the latest
commitIndexasreadIndex. - Wait for state machine application: wait until the state machine has applied at least to the
readIndexposition. - Execute read: safely read data from the local state machine.
- Return result to the client.
The leader lease is a common optimization: during the lease period, the leader can skip the heartbeat confirmation and directly use the current commitIndex as the readIndex.
Chapter Summary #
This chapter systematically elaborated on the core principles, theoretical boundaries, and evolutionary context in engineering practice of distributed consensus algorithms.
Theoretical Boundaries: The FLP impossibility theorem clarifies that in a fully asynchronous distributed system, there does not exist a deterministic consensus algorithm that can guarantee fault tolerance.
Paxos Algorithm: We analyzed the birth background of Paxos through step-by-step derivation from primary-backup replication to quorum reads and writes. Multi-Paxos introduced the concept of a stable leader, solving the performance bottleneck of Basic Paxos.
Raft Algorithm: As an engineering and standardization of Multi-Paxos, Raft decouples the complex consensus problem into three independent sub-problems: Leader Election, Log Replication, and Safety Constraints. The chapter also covered key engineering issues: cluster membership changes, log compaction, and performance optimizations (Pre-Vote, ReadIndex, Lease Read).
In summary, distributed consensus algorithms essentially abstract the uncertain physical network into a logically strictly ordered whole through strict majority protocols and state machine replication mechanisms.
References #
-
Michael J. Fischer, Nancy Lynch, and Michael S. Paterson: “Impossibility of Distributed Consensus with One Faulty Process,” Journal of the ACM, volume 32, number 2, pages 374–382, April 1985.
-
Paper Trail: “A Brief Tour of FLP Impossibility,” the-paper-trail.org, 2008.
-
Wikipedia: “Paxos (Computer Science)”
-
Wikipedia: “Leslie Lamport”
-
Wikipedia: “Michael Burrows (Computer Scientist)”
-
Leslie Lamport: “The Part-Time Parliament,” ACM Transactions on Computer Systems (TOCS), volume 16, number 2, pages 133–169, May 1998.
-
Leslie Lamport: “Paxos Made Simple,” ACM SIGACT News, volume 32, number 4, pages 18–25, December 2001.
-
Mike Burrows: “The Chubby Lock Service for Loosely-Coupled Distributed Systems,” at 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2006.
-
OpenAcid: “Reliable Distributed Systems: An Intuitive Explanation of Paxos”
-
Zhiying Liang, Vahab Jabrayilov, and Aleksey Charapko: “MultiPaxos Made Complete,” 2024.
-
Tushar Chandra, Robert Griesemer, and Joshua Redstone: “Paxos Made Live — An Engineering Perspective,” at ACM Symposium on Principles of Distributed Computing (PODC), 2007.
-
Diego Ongaro and John K. Ousterhout: “In Search of an Understandable Consensus Algorithm,” at USENIX Annual Technical Conference, 2014.
-
Diego Ongaro: “Consensus: Bridging Theory and Practice,” Stanford University PhD Thesis, 2014.
-
etcd: “GitHub Repository”
-
TiKV: “GitHub Repository”
-
Consul: “GitHub Repository”
-
Raft: “Official Website”
-
OpenRaft: “GitHub Repository”
-
Diego Ongaro: “Origin of the Name ‘Raft’,” Raft Google Groups.
-
Diego Ongaro: “Issues with Single-Step Membership Changes,” Raft Developer Mailing List, 2015.
-
Cloudflare: “A Byzantine Failure in the Real World”
-
Ittai Abraham: “Raft Liveness Revisited”, decentralizedthoughts.github.io, 2020.
-
etcd: “Issue #3866: CheckQuorum”